
メールなどによるお客様からの問い合わせへの対応は、多くのビジネスで不可欠な業務ですが、すぐに手に負えなくなる可能性があります。Gemma などの人工知能(AI)モデルは、少しの労力でこの作業を簡単にします。
メールなどの問い合わせへの対応は、企業によって少しずつ異なります。そのため、生成 AI などのテクノロジーを自社のニーズに合わせて調整することが重要です。このプロジェクトでは、パン屋に届いたメールから注文情報を抽出して構造化データに変換し、注文処理システムにすばやく追加できるようにするという特定の問題に取り組んでいます。問い合わせと必要な出力の例を 10 ~ 20 個使用して、Gemma モデルを調整し、顧客からのメールを処理して迅速な返信を支援し、既存のビジネス システムと統合できます。このプロジェクトは、ビジネスで Gemma モデルの価値を引き出すために拡張および適応できる AI アプリケーション パターンとして構築されています。
プロジェクトの概要と拡張方法の動画(作成者のインサイトを含む)については、ビジネス メール AI アシスタントの Build with Google AI 動画をご覧ください。このプロジェクトのコードは、Gemma Cookbook コード リポジトリで確認することもできます。それ以外の場合は、次の手順に沿ってプロジェクトの拡張を開始できます。
概要
このチュートリアルでは、Gemma、Python、Flask で構築されたビジネス メール アシスタント アプリケーションの設定、実行、拡張について説明します。このプロジェクトでは、ニーズに合わせて変更できる基本的なウェブ ユーザー インターフェースが提供されます。このアプリケーションは、架空のパン屋の構造に顧客のメールからデータを抽出するように構築されています。このアプリケーション パターンは、テキスト入力とテキスト出力を使用するビジネス タスクで使用できます。
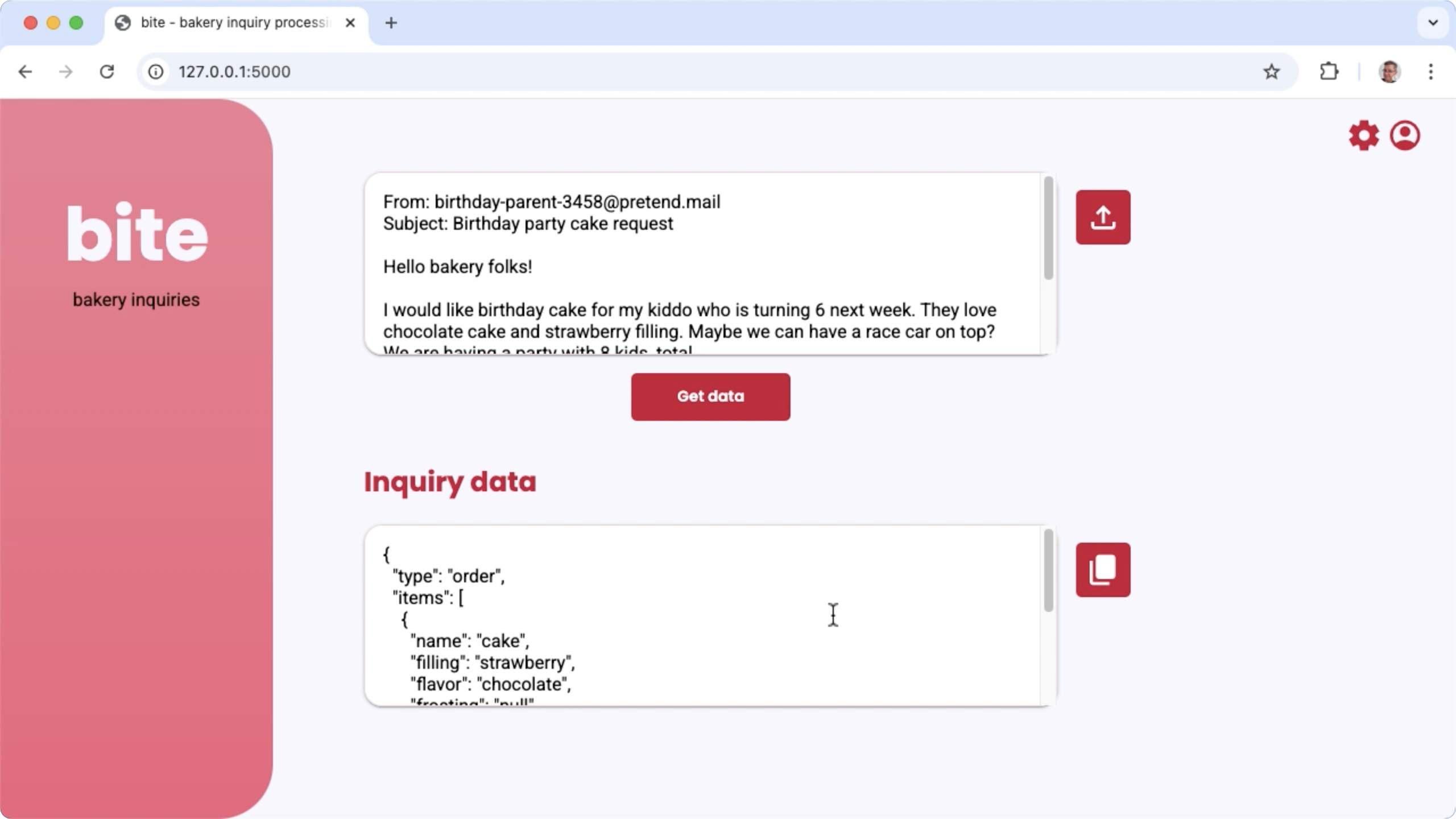
図 1. パン屋のメール問い合わせを処理するためのプロジェクトのユーザー インターフェース
ハードウェア要件
このチューニング プロセスは、画像処理装置(GPU)または Tensor 処理装置(TPU)を備え、既存のモデルとチューニング データを保持するのに十分な GPU または TPU メモリを備えたコンピュータで実行します。このプロジェクトでチューニング構成を実行するには、約 16 GB の GPU メモリ、同程度の通常の RAM、および 50 GB 以上のディスク容量が必要です。
このチュートリアルの Gemma モデル チューニング部分を実行するには、T4 GPU ランタイムを使用する Colab 環境を使用します。このプロジェクトを Google Cloud VM インスタンスで構築する場合は、次の要件に従ってインスタンスを構成します。
- GPU ハードウェア: このプロジェクトを実行するには NVIDIA T4 が必要です(NVIDIA L4 以降を推奨)。
- オペレーティング システム: [Linux でのディープ ラーニング] オプションを選択します。具体的には、GPU ソフトウェア ドライバがプリインストールされた [Deep Learning VM with CUDA 12.3 M124] を選択します。
- ブートディスク サイズ: データ、モデル、サポート ソフトウェア用に 50 GB 以上のディスク容量をプロビジョニングします。
プロジェクトの設定
ここでは、このプロジェクトを開発とテスト用に準備する手順について説明します。一般的な設定手順には、前提条件となるソフトウェアのインストール、コード リポジトリからのプロジェクトのクローン作成、いくつかの環境変数の設定、Python ライブラリのインストール、ウェブ アプリケーションのテストが含まれます。
Velostrata ソリューションの
このプロジェクトでは、Python 3 と仮想環境(venv)を使用してパッケージを管理し、アプリケーションを実行します。次のインストール手順は、Linux ホストマシン用です。
必要なソフトウェアをインストールするには:
Python 3 と Python 用の
venv仮想環境パッケージをインストールします。sudo apt update sudo apt install git pip python3-venv
プロジェクトのクローンを作成する
プロジェクト コードを開発用コンピュータにダウンロードします。プロジェクトのソースコードを取得するには、git ソース管理ソフトウェアが必要です。
プロジェクト コードをダウンロードするには:
次のコマンドを使用して、git リポジトリのクローンを作成します。
git clone https://github.com/google-gemini/gemma-cookbook.git必要に応じて、スパース チェックアウトを使用するようにローカル Git リポジトリを構成して、プロジェクトのファイルのみを取得します。
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
Python ライブラリをインストールする
venv Python 仮想環境を有効にして Python ライブラリをインストールし、Python パッケージと依存関係を管理します。pip インストーラを使用して Python ライブラリをインストールする前に、Python 仮想環境を有効にしてください。Python 仮想環境の使用方法については、Python venv のドキュメントをご覧ください。
Python ライブラリをインストールするには:
ターミナル ウィンドウで
business-email-assistantディレクトリに移動します。cd Demos/business-email-assistant/このプロジェクトの Python 仮想環境(venv)を構成して有効にします。
python3 -m venv venv source venv/bin/activatesetup_pythonスクリプトを使用して、このプロジェクトに必要な Python ライブラリをインストールします。./setup_python.sh
環境変数を設定する
このプロジェクトを実行するには、Kaggle ユーザー名や Kaggle API トークンなど、いくつかの環境変数が必要です。Gemma モデルをダウンロードするには、Kaggle アカウントを取得し、Gemma モデルへのアクセスをリクエストする必要があります。このプロジェクトでは、Kaggle ユーザー名と Kaggle API トークンを 2 つの .env ファイルに追加します。これらのファイルは、ウェブ アプリケーションとチューニング プログラムによってそれぞれ読み取られます。
環境変数を設定するには:
- Kaggle のドキュメントの手順に沿って、Kaggle のユーザー名とトークンキーを取得します。
- Gemma の設定ページの Gemma にアクセスするの手順に沿って、Gemma モデルにアクセスします。
- プロジェクトの環境変数ファイルを作成します。これを行うには、プロジェクトのクローン内の次の各ロケーションに
.envテキスト ファイルを作成します。email-processing-webapp/.env model-tuning/.env
.envテキスト ファイルを作成したら、両方のファイルに次の設定を追加します。KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
アプリケーションを実行してテストする
プロジェクトのインストールと構成が完了したら、ウェブ アプリケーションを実行して、正しく構成されていることを確認します。これは、プロジェクトを編集して独自に使用する前に、ベースライン チェックとして行う必要があります。
プロジェクトを実行してテストするには:
ターミナル ウィンドウで
email-processing-webappディレクトリに移動します。cd business-email-assistant/email-processing-webapp/run_appスクリプトを使用してアプリケーションを実行します。./run_app.shウェブ アプリケーションを起動すると、プログラム コードに参照とテストが可能な URL が表示されます。通常、このアドレスは次のようになります。
http://127.0.0.1:5000/ウェブ インターフェースで、最初の入力フィールドの下にある [データを取得] ボタンを押して、モデルからレスポンスを生成します。
アプリケーションを実行した後のモデルからの最初のレスポンスは、最初の生成実行で初期化ステップを完了する必要があるため、時間がかかります。すでに実行中のウェブ アプリケーションに対する後続のプロンプト リクエストと生成は、より短時間で完了します。
アプリケーションを拡張する
アプリケーションを実行したら、ユーザー インターフェースとビジネス ロジックを変更して、自分やビジネスに関連するタスクで動作するように拡張できます。アプリが生成 AI モデルに送信するプロンプトのコンポーネントを変更することで、アプリケーション コードを使用して Gemma モデルの動作を変更することもできます。
アプリケーションは、ユーザーからの入力データとともに、モデルの完全なプロンプトをモデルに指示として提供します。これらの手順を変更して、生成するパラメータの名前や JSON の構造を指定するなど、モデルの動作を変更できます。モデルの動作を変更する簡単な方法は、生成された返信に Markdown 形式を含めないように指定するなど、モデルのレスポンスに追加の指示やガイダンスを提供することです。
プロンプトの指示を変更するには:
- 開発プロジェクトで、
business-email-assistant/email-processing-webapp/app.pyコードファイルを開きます。 app.pyコードで、get_prompt():関数に追加の指示を追加します。def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
この例では、「追加のマークダウン形式なし」というフレーズを手順に追加しています。
プロンプトに指示を追加すると、生成される出力に大きな影響を与えることができ、実装にかかる労力も大幅に軽減されます。まずこの方法を試して、モデルから目的の動作を取得できるかどうかを確認してください。ただし、プロンプト指示を使用して Gemma モデルの動作を変更するには、制限があります。特に、モデルの入力トークンの合計上限(Gemma 2 の場合は 8,192 トークン)があるため、詳細なプロンプト指示と提供する新しいデータのサイズをバランスよく調整して、上限を超えないようにする必要があります。
モデルのチューニング
Gemma モデルのファインチューニングを行うことは、特定のタスクに対してより信頼性の高いレスポンスを得るための推奨される方法です。特に、特定の構造の JSON を生成するモデル(特定の名前のパラメータを含む)が必要な場合は、その動作に合わせてモデルをチューニングすることを検討してください。モデルに完了させたいタスクに応じて、10 ~ 20 個の例で基本的な機能を実現できます。このチュートリアルのこのセクションでは、特定のタスク用に Gemma モデルでファインチューニングを設定して実行する方法について説明します。
次の手順では、VM 環境でファインチューニング オペレーションを実行する方法について説明します。ただし、このチューニング オペレーションは、このプロジェクトに関連付けられた Colab ノートブックを使用して実行することもできます。
ハードウェア要件
ファインチューニングのコンピューティング要件は、プロジェクトの残りの部分のハードウェア要件と同じです。入力トークンを 256 に制限し、バッチサイズを 1 に制限すると、T4 GPU ランタイムを使用して Colab 環境でチューニング オペレーションを実行できます。
データの準備
Gemma モデルのチューニングを開始する前に、チューニング用のデータを準備する必要があります。特定のタスク用にモデルをチューニングする場合は、リクエストとレスポンスの例のセットが必要です。これらの例では、リクエスト テキストと、指示なしの想定されるレスポンス テキストを示す必要があります。まず、10 個程度の例を含むデータセットを準備します。これらの例は、さまざまなリクエストと理想的なレスポンスを網羅している必要があります。リクエストとレスポンスが繰り返されないようにしてください。繰り返されると、モデルのレスポンスも繰り返され、リクエストのバリエーションに適切に対応できなくなる可能性があります。構造化されたデータ形式を生成するようにモデルをチューニングする場合は、提供されたすべてのレスポンスが、目的のデータ出力形式に厳密に準拠していることを確認してください。次の表は、このコード例のデータセットのサンプルレコードをいくつか示しています。
| リクエスト | レスポンス |
|---|---|
| Indian Bakery Central 様\n\n お世話になります。\n\n ペンダー 10 個とブンディ ラドゥ 30 個はありますか?バニラ フロスティングとチョコレート味のケーキも販売していますか?6 インチのサイズを探しています | { "type": "inquiry", "items": [ { "name": "pendas", "quantity": 10 }, { "name": "bundi ladoos", "quantity": 30 }, { "name": "cake", "filling": null, "frosting": "vanilla", "flavor": "chocolate", "size": "6 in" } ] } |
| Google マップであなたのビジネスを見ました。ジャラビとグラブ ジャムンは販売していますか? | { "type": "inquiry", "items": [ { "name": "jellabi", "quantity": null }, { "name": "gulab jamun", "quantity": null } ] } |
表 1. パン屋のメールデータ抽出用のチューニング データセットの一部。
データ形式と読み込み
Python コードでレコードを取得できる限り、チューニング データは、データベース レコード、JSON ファイル、CSV、プレーン テキスト ファイルなど、任意の形式で保存できます。このプロジェクトは、data ディレクトリから JSON ファイルを読み取り、辞書オブジェクトの配列に格納します。この例のチューニング プログラムでは、チューニング データセットは prepare_tuning_dataset() 関数を使用して model-tuning/main.py モジュールに読み込まれます。
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
前述のように、関連するレスポンスを含むリクエストを取得し、チューニング レコードとして使用されるテキスト文字列に組み立てることができる限り、データセットは便利な形式で保存できます。
チューニング レコードを組み立てる
実際のチューニング プロセスでは、プロンプトの指示とレスポンスの内容を含む 1 つの文字列に、各リクエストとレスポンスがまとめられます。チューニング プログラムは、モデルで使用できるように文字列をトークン化します。チューニング レコードを組み立てるコードは、model-tuning/main.py モジュールの prepare_tuning_dataset() 関数にあります。
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
この関数は、データを入力として受け取り、指示とレスポンスの間に改行を追加してデータをフォーマットします。
モデルの重みを生成する
チューニング データが配置され、読み込まれたら、チューニング プログラムを実行できます。このサンプル アプリケーションのチューニング プロセスでは、Keras NLP ライブラリを使用して、Low Rank Adaptation(LoRA)手法でモデルをチューニングし、新しいモデルの重みを生成します。LoRA はモデルの重みの変化を近似するため、フル精度チューニングよりもメモリ効率が大幅に向上します。その後、これらの近似重みを既存のモデルの重みに重ねて、モデルの動作を変更できます。
チューニング実行を行い、新しい重みを計算するには:
ターミナル ウィンドウで、
model-tuning/ディレクトリに移動します。cd business-email-assistant/model-tuning/tune_modelスクリプトを使用してチューニング プロセスを実行します。./tune_model.sh
チューニング プロセスには、使用可能なコンピューティング リソースに応じて数分かかります。チューニング プログラムが正常に完了すると、次の形式で新しい *.h5 重みファイルが model-tuning/weights ディレクトリに書き込まれます。
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
トラブルシューティング
チューニングが正常に完了しなかった場合、次の 2 つの理由が考えられます。
- メモリ不足またはリソース不足: これらのエラーは、チューニング プロセスが使用可能な GPU メモリまたは CPU メモリを超えるメモリをリクエストすると発生します。チューニング プロセスが実行されている間は、ウェブ アプリケーションを実行しないようにしてください。GPU メモリが 16 GB のデバイスでチューニングする場合は、
token_limitを 256 に、batch_sizeを 1 に設定してください。 - GPU ドライバがインストールされていないか、JAX と互換性がない: チューニング プロセスでは、コンピューティング デバイスに JAX ライブラリのバージョンと互換性のあるハードウェア ドライバがインストールされている必要があります。詳細については、JAX のインストールのドキュメントをご覧ください。
チューニングされたモデルをデプロイする
チューニング プロセスでは、チューニング データとチューニング アプリケーションで設定されたエポックの総数に基づいて、複数の重みが生成されます。デフォルトでは、チューニング プログラムはチューニング エポックごとに 1 つずつ、3 つのモデル重みファイルを生成します。チューニング エポックを繰り返すたびに、チューニング データの結果をより正確に再現する重みが生成されます。各エポックの精度は、次のようにチューニング プロセスのターミナル出力で確認できます。
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
精度率は 0.80 程度と比較的高い方が望ましいですが、1.00 に近いほど高すぎるのは、重みがチューニング データに過学習していることを意味するため、望ましくありません。その場合、モデルはチューニングの例と大きく異なるリクエストに対して十分なパフォーマンスを発揮しません。デフォルトでは、デプロイ スクリプトはエポック 3 の重みを選択します。通常、この重みの精度は約 0.80 です。
生成された重みをウェブ アプリケーションにデプロイするには:
ターミナル ウィンドウで
model-tuningディレクトリに移動します。cd business-email-assistant/model-tuning/deploy_weightsスクリプトを使用してチューニング プロセスを実行します。./deploy_weights.sh
このスクリプトを実行すると、email-processing-webapp/weights/ ディレクトリに新しい *.h5 ファイルが表示されます。
新しいモデルをテストする
新しい重みをアプリケーションにデプロイしたら、新しくチューニングされたモデルを試してみましょう。これを行うには、ウェブ アプリケーションを再実行してレスポンスを生成します。
プロジェクトを実行してテストするには:
ターミナル ウィンドウで
email-processing-webappディレクトリに移動します。cd business-email-assistant/email-processing-webapp/run_appスクリプトを使用してアプリケーションを実行します。./run_app.shウェブ アプリケーションを起動すると、プログラム コードに閲覧とテストに使用できる URL が表示されます。通常、このアドレスは次のようになります。
http://127.0.0.1:5000/ウェブ インターフェースで、最初の入力フィールドの下にある [データを取得] ボタンを押して、モデルからレスポンスを生成します。
これで、アプリケーションで Gemma モデルをチューニングしてデプロイしました。アプリケーションをテストして、タスクに対するチューニング済みモデルの生成能力の限界を特定します。モデルが適切に機能しないシナリオが見つかった場合は、リクエストを追加して理想的なレスポンスを提供することで、それらのリクエストの一部をチューニングのサンプルデータのリストに追加することを検討してください。次に、チューニング プロセスを再実行し、新しい重みを再デプロイして、出力をテストします。
参考情報
このプロジェクトの詳細については、Gemma Cookbook コード リポジトリをご覧ください。アプリの作成についてサポートが必要な場合や、他のデベロッパーとのコラボレーションをご希望の場合は、Google Developers Community Discord サーバーをご利用ください。Build with Google AI プロジェクトの詳細については、動画の再生リストをご覧ください。