
Modellseite:CodeGemma
Ressourcen und technische Dokumentation:
Nutzungsbedingungen: Begriffe
Autoren: Google
Modellinformationen
Modellübersicht
Beschreibung
CodeGemma ist eine Familie einfacher Open-Code-Modelle, die auf Gemma basieren. CodeGemma-Modelle sind reine Decodermodelle für Text-zu-Text- und Text-zu-Code-Aufgaben. Sie sind als 7-Milliarden-Variante mit Vorabtraining für Codevervollständigungs- und Codegenerierungsaufgaben, als 7-Milliarden-Parameter-Variante mit Anweisungsabstimmung für Codechats und das Ausführen von Anweisungen sowie als 2-Milliarden-Parameter-Variante mit Vorabtraining für die schnelle Codevervollständigung verfügbar.
Eingaben und Ausgaben
Eingabe:Bei vortrainierten Modellvarianten: Codepräfix und optional Suffix für Codevervollständigungs- und ‑generierungsszenarien oder Text/Prompt in natürlicher Sprache. Für die anhand von Anweisungen optimierte Modellvariante: Text in natürlicher Sprache oder Prompt.
Ausgabe:Für vortrainierte Modellvarianten: Codevervollständigung vom Typ „Lückentext“, Code und natürliche Sprache. Für die an Anweisungen angepasste Modellvariante: Code und natürliche Sprache.
Zitation
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
Modelldaten
Trainings-Dataset
Mit Gemma als Basismodell werden die vortrainierten Varianten CodeGemma 2B und 7B mit zusätzlichen 500 bis 1.000 Milliarden Tokens hauptsächlich englischsprachiger Daten aus Open-Source-Mathematik-Datasets und synthetisch generiertem Code weiter trainiert.
Datenverarbeitung von Trainingsdaten
Für das Training von CodeGemma wurden die folgenden Techniken zur Datenvorverarbeitung angewendet:
- FIM – Vortrainierte CodeGemma-Modelle konzentrieren sich auf Aufgaben vom Typ „Füllen Sie die Lücke aus“. Die Modelle sind für die Verwendung mit PSM- und SPM-Modi trainiert. Unsere FIM-Einstellungen sind eine FIM-Rate von 80% bis 90% mit 50–50 PSM/SPM.
- Paketierungstechniken auf Grundlage von Abhängigkeitsgraphen und Unit-Tests: Um die Modellausrichtung auf reale Anwendungen zu verbessern, haben wir Trainingsbeispiele auf Projekt-/Repositoryebene strukturiert, um die relevantesten Quelldateien in jedem Repository zu platzieren. Insbesondere haben wir zwei heuristische Verfahren eingesetzt: paketbasiertes Packen mit Abhängigkeitsgraphen und lexikalisches Packen mithilfe von Unit-Tests.
- Wir haben eine neue Methode entwickelt, um die Dokumente in Präfix, Mitte und Suffix aufzuteilen, damit das Suffix an einer syntaktisch natürlicheren Stelle beginnt, anstatt rein zufällig verteilt zu werden.
- Sicherheit: Ähnlich wie bei Gemma haben wir strenge Sicherheitsfilter eingeführt, darunter die Filterung personenbezogener Daten, die Filterung von Missbrauchsdarstellungen von Kindern im Internet und andere Filter, die auf der Qualität und Sicherheit von Inhalten basieren und unseren Richtlinien entsprechen.
Informationen zur Implementierung
Hardware und Frameworks, die während des Trainings verwendet werden
Wie Gemma wurde CodeGemma mit der neuesten Generation von Tensor Processing Unit (TPU)-Hardware (TPUv5e) mit JAX und ML Pathways trainiert.
Informationen zur Bewertung
Benchmark-Ergebnisse
Bewertungsansatz
- Benchmarks für die Codevervollständigung: HumanEval (HE) (Ein- und mehrzeiliges Ausfüllen)
- Benchmarks für die Codegenerierung: HumanEval, MBPP, BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
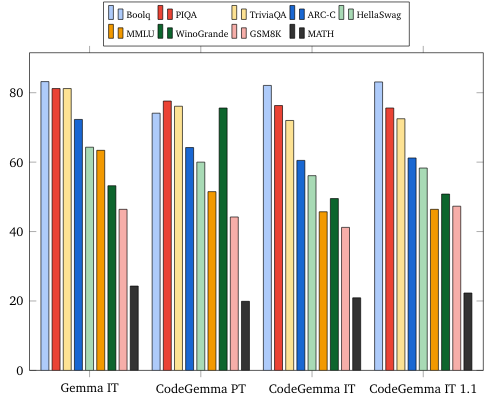
- Fragen und Antworten: BoolQ, PIQA, TriviaQA
- Natürliche Sprache: ARC-Challenge, HellaSwag, MMLU, WinoGrande
- Mathematisches Denken: GSM8K, MATH
Ergebnisse des Codierungs-Benchmarks
| Benchmark | 2 Mrd. | 2B (1.1) | 7B | 7B-IT | 7B-IT (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31.1 | 37,8 | 44,5 | 56,1 | 60,4 |
| MBPP | 43,6 | 49,2 | 56,2 | 54.2 | 55,6 |
| HumanEval – eine Zeile | 78,4 | 79,3 | 76,1 | 68,3 | 77,4 |
| HumanEval Mehrzeilige Antwort | 51,4 | 51,0 | 58,4 | 20.1 | 23,7 |
| BC HE C++ | 24.2 | 19,9 | 32,9 | 42.2 | 46,6 |
| BC HE C# | 10.6 | 26.1 | 22,4 | 26,7 | 54,7 |
| BC HE Go | 20,5 | 18.0 | 21.7 | 28,6 | 34,2 |
| BC HE Java | 29,2 | 29,8 | 41,0 | 48,4 | 50,3 |
| BC HE JavaScript | 21.7 | 28.0 | 39,8 | 46,0 | 48,4 |
| BC HE Kotlin | 28.0 | 32,3 | 39,8 | 51,6 | 47,8 |
| BC HE Python | 21.7 | 36,6 | 42.2 | 48,4 | 54,0 |
| BC HE Rust | 26,7 | 24.2 | 34.1 | 36,0 | 37,3 |
| BC MBPP C++ | 47.1 | 38,9 | 53,8 | 56,7 | 63,5 |
| BC MBPP C# | 28,7 | 45,3 | 32,5 | 41.2 | 62,0 |
| BC MBPP Go | 45,6 | 38,9 | 43,3 | 46,2 | 53,2 |
| BC MBPP Java | 41,8 | 49,7 | 50,3 | 57,3 | 62,9 |
| BC MBPP JavaScript | 45,3 | 45,0 | 58,2 | 61,4 | 61,4 |
| BC MBPP Kotlin | 46,8 | 49,7 | 54,7 | 59,9 | 62,6 |
| BC MBPP Python | 38,6 | 52,9 | 59,1 | 62,0 | 60,2 |
| BC MBPP Rust | 45,3 | 47,4 | 52,9 | 53,5 | 52,3 |
Benchmarks für natürliche Sprache (auf 7B-Modellen)
Ethik und Sicherheit
Ethik- und Sicherheitsbewertungen
Bewertungsansatz
Zu unseren Bewertungsmethoden gehören strukturierte Bewertungen und interne Red-Team-Tests der relevanten Inhaltsrichtlinien. Das Red-Teaming wurde von mehreren verschiedenen Teams durchgeführt, die jeweils unterschiedliche Ziele und Bewertungsmesswerte für Menschen hatten. Diese Modelle wurden anhand verschiedener Kategorien bewertet, die für Ethik und Sicherheit relevant sind, darunter:
Manuelle Bewertung von Prompts im Hinblick auf die Sicherheit von Inhalten und repräsentative Schäden. Weitere Informationen zum Bewertungsansatz finden Sie auf der Gemma-Modellkarte.
Spezifische Tests von Cyberangriffsfähigkeiten, die sich auf das Testen autonomer Hacking-Fähigkeiten konzentrieren und dafür sorgen, dass potenzielle Schäden begrenzt werden.
Bewertungsergebnisse
Die Ergebnisse der Ethik- und Sicherheitsbewertungen liegen innerhalb der zulässigen Grenzwerte, um die internen Richtlinien für Kategorien wie den Schutz von Kindern, die Sicherheit von Inhalten, repräsentative Schäden, das Auswendiglernen und Schäden in großem Umfang einzuhalten. Weitere Informationen finden Sie auf der Gemma-Modellkarte.
Modellnutzung und -einschränkungen
Bekannte Einschränkungen
Large Language Models (LLMs) haben Einschränkungen, die auf ihren Trainingsdaten und den inhärenten Einschränkungen der Technologie beruhen. Weitere Informationen zu den Einschränkungen von LLMs finden Sie auf der Gemma-Modellkarte.
Ethische Aspekte und Risiken
Die Entwicklung von Large Language Models (LLMs) wirft mehrere ethische Fragen auf. Bei der Entwicklung dieser Modelle haben wir mehrere Aspekte sorgfältig berücksichtigt.
Weitere Informationen zum Modell finden Sie in derselben Diskussion auf der Gemma-Modellkarte.
Verwendungszweck
Anwendung
Code Gemma-Modelle haben eine breite Palette von Anwendungen, die zwischen IT- und PT-Modellen variieren. Die folgende Liste möglicher Anwendungsfälle ist nicht vollständig. Diese Liste soll Kontextinformationen zu den möglichen Anwendungsfällen liefern, die die Ersteller des Modells im Rahmen der Modellerstellung und -entwicklung berücksichtigt haben.
- Codevervollständigung: PT-Modelle können verwendet werden, um Code mit einer IDE-Erweiterung zu vervollständigen.
- Codegenerierung: IT-Modell kann verwendet werden, um Code mit oder ohne IDE-Erweiterung zu generieren
- Code Conversation: IT-Modell kann Konversationsschnittstellen unterstützen, die Code beinhalten
- Code Education: IT-Modell unterstützt interaktives Code-Lernen, hilft bei der Syntaxkorrektur oder bietet Programmierübungen
Vorteile
Zum Zeitpunkt der Veröffentlichung bietet diese Modellfamilie im Vergleich zu Modellen ähnlicher Größe hochleistungsfähige, auf Open-Code ausgerichtete Large Language Model-Implementierungen, die von Grund auf für die Entwicklung verantwortungsbewusster KI entwickelt wurden.
Anhand der in diesem Dokument beschriebenen Bewertungsmesswerte für den Codierungsbenchmark haben diese Modelle eine bessere Leistung als andere Open-Source-Modelle vergleichbarer Größe gezeigt.