
Страница модели: CodeGemma
Ресурсы и техническая документация:
- Технический отчет
- Инструментарий ответственного генеративного искусственного интеллекта
- CodeGemma на Kaggle
Условия использования: Условия
Авторы: Google
Информация о модели
Краткое описание модели
Описание
CodeGemma — это семейство облегченных моделей с открытым кодом, построенных на основе Gemma. Модели CodeGemma представляют собой модели преобразования текста в текст и преобразования текста в код только для декодера и доступны в виде предварительно обученного варианта на 7 миллиардов, который специализируется на задачах завершения кода и генерации кода, а также варианта на 7 миллиардов параметров, настроенного на инструкции для чата кода и инструкций. следующий и предварительно обученный вариант с 2 миллиардами параметров для быстрого завершения кода.
Входы и выходы
Входные данные: для предварительно обученных вариантов модели: префикс кода и (необязательно) суффикс для сценариев завершения и генерации кода или текста/подсказки на естественном языке. Для варианта модели, настроенной на инструкции: текст на естественном языке или подсказка.
Выходные данные: для предварительно обученных вариантов модели: завершение кода в середине, код и естественный язык. Для варианта модели, настроенной на инструкции: код и естественный язык.
Цитирование
@article{codegemma_2024,
title={CodeGemma: Open Code Models Based on Gemma},
url={https://goo.gle/codegemma},
author={ {CodeGemma Team} and Hartman, Ale Jakse and Hu, Andrea and Choquette-Choo, Christopher A. and Zhao, Heri and Fine, Jane and Hui,
Jeffrey and Shen, Jingyue and Kelley, Joe and Howland, Joshua and Bansal, Kshitij and Vilnis, Luke and Wirth, Mateo and Nguyen, Nam, and Michel, Paul and Choy, Peter and Joshi, Pratik and Kumar, Ravin and Hashmi, Sarmad and Agrawal, Shubham and Zuo, Siqi and Warkentin, Tris and Gong, Zhitao et al.},
year={2024}
}
Данные модели
Набор обучающих данных
Используя Gemma в качестве базовой модели, предварительно обученные варианты CodeGemma 2B и 7B дополнительно обучаются на дополнительных 500–1000 миллиардах токенов преимущественно англоязычных данных из наборов математических данных с открытым исходным кодом и синтетически сгенерированного кода.
Обработка обучающих данных
Для обучения CodeGemma применялись следующие методы предварительной обработки данных:
- FIM — предварительно обученные модели CodeGemma ориентированы на задачи с заполнением посередине (FIM). Модели обучены работать как в режимах PSM, так и в SPM. Наши настройки FIM составляют от 80% до 90% скорости FIM с 50-50 PSM/SPM.
- Методы упаковки на основе графа зависимостей и лексической упаковки на основе модульного тестирования. Чтобы улучшить согласованность модели с реальными приложениями, мы структурировали обучающие примеры на уровне проекта/репозитория, чтобы разместить наиболее подходящие исходные файлы в каждом репозитории. В частности, мы использовали два эвристических метода: упаковку на основе графа зависимостей и лексическую упаковку на основе модульного тестирования.
- Мы разработали новую технику разделения документов на префикс, середину и суффикс, чтобы суффикс начинался в более синтаксически естественной точке, а не в чисто случайном распределении.
- Безопасность. Как и в случае с Gemma, мы внедрили строгую фильтрацию безопасности, включая фильтрацию личных данных, фильтрацию CSAM и другие фильтры, основанные на качестве и безопасности контента, в соответствии с нашими политиками .
Информация о реализации
Аппаратное обеспечение и платформы, используемые во время обучения
Как и Gemma , CodeGemma прошла обучение на аппаратном обеспечении TPU последнего поколения (TPUv5e) с использованием JAX и ML Pathways .
Информация об оценке
Результаты тестов
Подход к оценке
- Тесты завершения кода: HumanEval (HE) (заполнение одной и нескольких строк)
- Тесты генерации кода: HumanEval, MBPP , BabelCode (BC) [C++, C#, Go, Java, JavaScript, Kotlin, Python, Rust]
- Вопросы и ответы: BoolQ , PIQA , TriviaQA
- Естественный язык: ARC-Challenge , HellaSwag , MMLU , WinoGrande.
- Математическое мышление: GSM8K , MATH
Результаты тестов кодирования
| Контрольный показатель | 2Б | 2Б (1,1) | 7Б | 7Б-ИТ | 7Б-ИТ (1.1) |
|---|---|---|---|---|---|
| HumanEval | 31,1 | 37,8 | 44,5 | 56,1 | 60,4 |
| МБПП | 43,6 | 49,2 | 56,2 | 54,2 | 55,6 |
| HumanEval, одна строка | 78,4 | 79,3 | 76,1 | 68,3 | 77,4 |
| HumanEval Многолинейный | 51,4 | 51,0 | 58,4 | 20.1 | 23,7 |
| BC HE C++ | 24.2 | 19,9 | 32,9 | 42,2 | 46,6 |
| BC HE C# | 10,6 | 26.1 | 22,4 | 26,7 | 54,7 |
| BC HE Go | 20,5 | 18,0 | 21,7 | 28,6 | 34,2 |
| Британская Колумбия, Ява | 29,2 | 29,8 | 41,0 | 48,4 | 50,3 |
| BC HE JavaScript | 21,7 | 28,0 | 39,8 | 46,0 | 48,4 |
| БК ВО Котлин | 28,0 | 32,3 | 39,8 | 51,6 | 47,8 |
| BC HE Питон | 21,7 | 36,6 | 42,2 | 48,4 | 54,0 |
| BC HE Ржавчина | 26,7 | 24.2 | 34,1 | 36,0 | 37,3 |
| БК МБПП С++ | 47,1 | 38,9 | 53,8 | 56,7 | 63,5 |
| BC MBPP C# | 28,7 | 45,3 | 32,5 | 41,2 | 62,0 |
| БК МБПП Го | 45,6 | 38,9 | 43,3 | 46,2 | 53,2 |
| БК МБПП Ява | 41,8 | 49,7 | 50,3 | 57,3 | 62,9 |
| БК МБПП JavaScript | 45,3 | 45,0 | 58,2 | 61,4 | 61,4 |
| БЦ МБПП Котлин | 46,8 | 49,7 | 54,7 | 59,9 | 62,6 |
| BC MBPP Python | 38,6 | 52,9 | 59,1 | 62,0 | 60,2 |
| БЦ МБПП Руст | 45,3 | 47,4 | 52,9 | 53,5 | 52,3 |
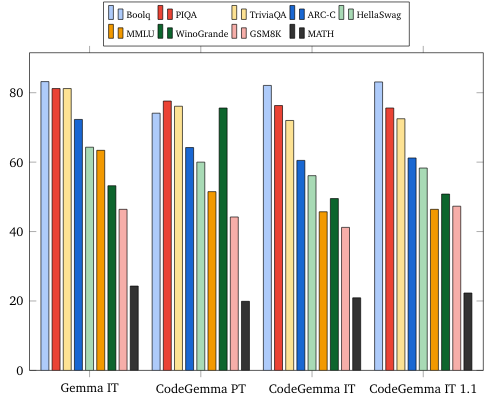
Тесты естественного языка (на моделях 7B)
Этика и безопасность
Оценка этики и безопасности
Подход к оценке
Наши методы оценки включают структурированные оценки и внутреннее групповое тестирование соответствующих политик в отношении контента. «Красная команда» проводилась несколькими разными командами, каждая из которых преследовала разные цели и показатели человеческой оценки. Эти модели оценивались по ряду различных категорий, имеющих отношение к этике и безопасности, в том числе:
Человеческая оценка подсказок, касающихся безопасности контента и репрезентативного вреда. Более подробную информацию о подходе к оценке см. в карточке модели Gemma .
Специальное тестирование возможностей киберпреступлений с упором на тестирование возможностей автономного взлома и обеспечение ограничения потенциального вреда.
Результаты оценки
Результаты оценок этики и безопасности находятся в пределах допустимых порогов соответствия внутренней политике по таким категориям, как безопасность детей, безопасность контента, репрезентативный вред, запоминание, крупномасштабный вред. Более подробную информацию можно найти на карточке модели Gemma .
Использование модели и ограничения
Известные ограничения
Модели большого языка (LLM) имеют ограничения, основанные на данных обучения и присущих технологии ограничениях. Более подробную информацию об ограничениях программ LLM см. в карточке модели Gemma .
Этические соображения и риски
Разработка больших языковых моделей (LLM) вызывает ряд этических проблем. Мы тщательно рассмотрели множество аспектов при разработке этих моделей.
Подробную информацию о модели можно найти в том же обсуждении в карточке модели Gemma.
Использование по назначению
Приложение
Модели Code Gemma имеют широкий спектр применения, который варьируется в зависимости от модели IT и PT. Следующий список потенциальных применений не является исчерпывающим. Цель этого списка — предоставить контекстную информацию о возможных вариантах использования, которые создатели модели рассматривали как часть обучения и разработки модели.
- Дополнение кода: модели PT можно использовать для завершения кода с помощью расширения IDE.
- Генерация кода: ИТ-модель можно использовать для генерации кода с расширением IDE или без него.
- Обсуждение кода: ИТ-модель может способствовать созданию интерфейсов диалога, в которых обсуждается код.
- Обучение кодированию: ИТ-модель поддерживает интерактивный опыт изучения кода, помогает исправлять синтаксис или предоставляет практику кодирования.
Преимущества
На момент выпуска это семейство моделей предоставляет высокопроизводительные реализации больших языковых моделей с открытым кодом, разработанные с нуля для ответственной разработки ИИ по сравнению с моделями аналогичного размера.
Используя метрики оценки эталонного кода кодирования, описанные в этом документе, эти модели продемонстрировали превосходную производительность по сравнению с другими альтернативами открытой модели сопоставимого размера.