
Ky udhëzues ofron udhëzime për konvertimin e modeleve Gemma në formatin Hugging Face Safetensors ( .safetensors ) në formatin e skedarit MediaPipe Task ( .task ). Ky konvertim është thelbësor për vendosjen e modeleve Gemma të trajnuara paraprakisht ose të rregulluara mirë për nxjerrjen e përfundimeve në pajisje në Android dhe iOS duke përdorur MediaPipe LLM Inference API dhe kohën e ekzekutimit LiteRT.
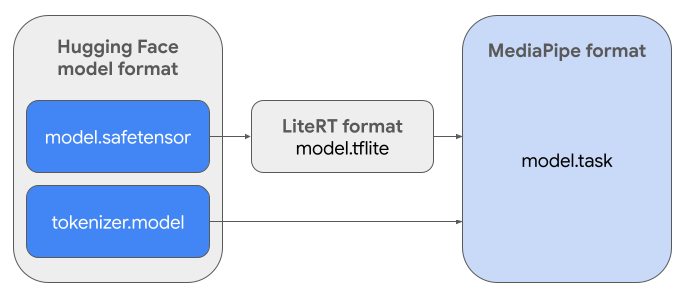
Për të krijuar Task Bundle-in e kërkuar ( .task ), do të përdorni LiteRT Torch . Ky mjet eksporton modelet PyTorch në modele LiteRT ( .tflite ) me shumë nënshkrime, të cilat janë të pajtueshme me MediaPipe LLM Inference API dhe të përshtatshme për t'u ekzekutuar në backend-et e CPU-së në aplikacionet mobile.
Skedari përfundimtar .task është një paketë e pavarur e kërkuar nga MediaPipe, që përfshin modelin LiteRT, modelin tokenizer dhe meta të dhënat thelbësore. Ky paketë është i nevojshëm sepse tokenizer (i cili konverton kërkesat e tekstit në ngulitje tokenësh për modelin) duhet të paketohet me modelin LiteRT për të mundësuar inferencën nga fillimi në fund.
Ja një përshkrim hap pas hapi i procesit:
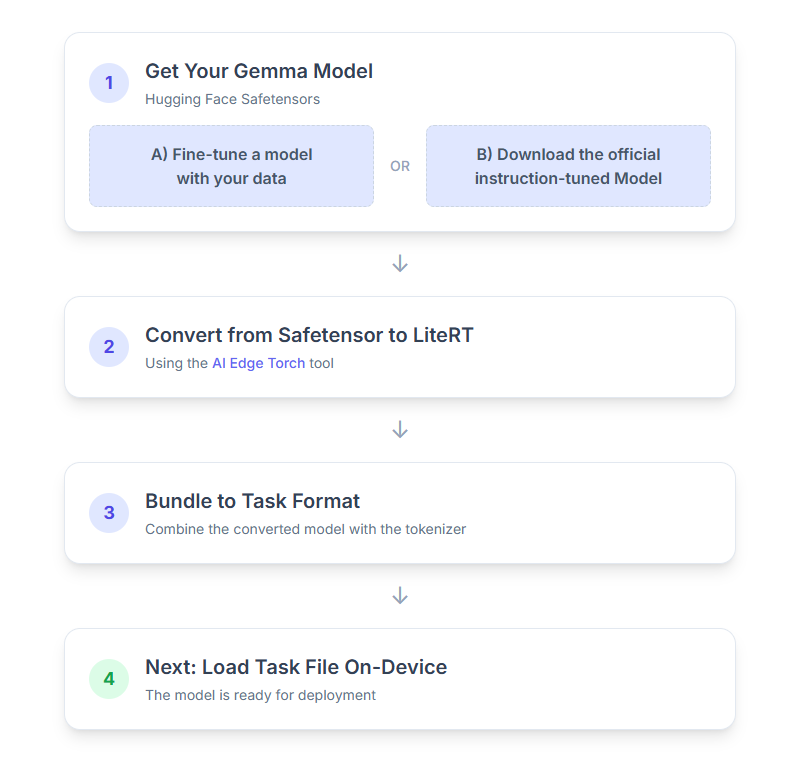
1. Merrni modelin tuaj Gemma
Keni dy mundësi për të filluar.
Opsioni A. Përdorni një model ekzistues të përmirësuar
Nëse keni përgatitur një model Gemma të përmirësuar , thjesht vazhdoni me hapin tjetër.
Opsioni B. Shkarkoni modelin zyrtar të akorduar me udhëzime
Nëse ju nevojitet një model, mund të shkarkoni një Gemma të përshtatur me udhëzime nga Hugging Face Hub.
Vendosni mjetet e nevojshme:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
Shkarkoni modelin:
Modelet në Hugging Face Hub identifikohen nga një ID modeli, zakonisht në formatin <organization_or_username>/<model_name> . Për shembull, për të shkarkuar modelin zyrtar të Google Gemma 3 270M të akorduar sipas udhëzimeve, përdorni:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. Konvertoni dhe kuantizoni modelin në LiteRT
Konfiguroni një mjedis virtual Python dhe instaloni versionin më të fundit të qëndrueshëm të paketës LiteRT Torch:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
Përdorni skriptin e mëposhtëm për të konvertuar Safetensor në modelin LiteRT.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
Kini parasysh se ky proces kërkon shumë kohë dhe varet nga shpejtësia e përpunimit të kompjuterit tuaj. Për referencë, në një CPU 2025 me 8 bërthama, një model 270M zgjat 5-10 minuta, ndërsa një model 1B mund të zgjasë afërsisht 10-30 minuta.
Rezultati përfundimtar, një model LiteRT, do të ruhet në OUTPUT_DIR_PATH të specifikuar.
Rregulloni vlerat e mëposhtme bazuar në kufizimet e memories dhe performancës së pajisjes suaj të synuar.
-
kv_cache_max_len: Përcakton madhësinë totale të alokuar të memories punuese të modelit (memoria e përkohshme KV). Ky kapacitet është një limit i prerë dhe duhet të jetë i mjaftueshëm për të ruajtur shumën e kombinuar të tokenëve të kërkesës (mbushja paraprake) dhe të gjithë tokenëve të gjeneruar më pas (dekodimi). -
prefill_seq_len: Specifikon numrin e tokenëve të kërkesës hyrëse për ndarjen paraprake të tokenëve. Kur përpunohet kërkesa hyrëse duke përdorur ndarjen paraprake të tokenëve, e gjithë sekuenca (p.sh., 50,000 tokena) nuk llogaritet menjëherë; në vend të kësaj, ajo ndahet në segmente të menaxhueshme (p.sh., copa prej 2,048 tokenash) që ngarkohen në mënyrë sekuenciale në memorien e përkohshme për të parandaluar një gabim të mungesës së memories. -
quantize: varg për skemat e zgjedhura të kuantizimit. Më poshtë është lista e recetave të kuantizimit në dispozicion për Gemma 3.-
none: Pa kuantizim -
fp16: Peshat FP16, aktivizimet FP32 dhe llogaritja e pikës lundruese për të gjitha operacionet -
dynamic_int8: Aktivizimet FP32, peshat INT8 dhe llogaritja e numrave të plotë -
weight_only_int8: Aktivizimet FP32, peshat INT8 dhe llogaritja e pikës lundruese
-
3. Krijoni një Pako Detyrash nga LiteRT dhe tokenizer
Konfiguroni një mjedis virtual Python dhe instaloni paketën mediapipe Python:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
Përdorni bibliotekën genai.bundler për të paketuar modelin:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
Funksioni bundler.create_bundle krijon një skedar .task që përmban të gjithë informacionin e nevojshëm për të ekzekutuar modelin.
4. Nxjerrja e përfundimeve me Mediapipe në Android
Inicializoni detyrën me opsionet bazë të konfigurimit:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
Përdorni metodën generateResponse() për të gjeneruar një përgjigje tekstuale.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
Për të transmetuar përgjigjen, përdorni metodën generateResponseAsync() .
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
Shihni udhëzuesin LLM Inference për Android për më shumë informacion.
Hapat e ardhshëm
Ndërtoni dhe eksploroni më shumë me modelet Gemma: