
يقدّم هذا الدليل تعليمات حول تحويل نماذج Gemma بتنسيق Hugging Face
Safetensors (.safetensors) إلى تنسيق ملف MediaPipe Tasks
(.task). هذا التحويل ضروري لنشر نماذج Gemma المدرَّبة مسبقًا أو
المعدَّلة بدقة للاستدلال على الجهاز على نظامَي التشغيل Android وiOS باستخدام
واجهة برمجة التطبيقات MediaPipe LLM Inference API ووقت تشغيل LiteRT.
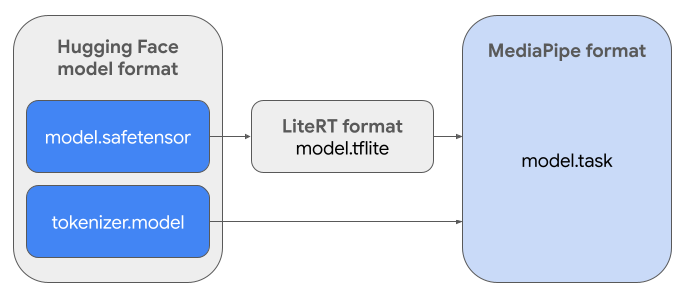
لإنشاء حزمة المهام المطلوبة (.task)، عليك استخدام LiteRT Torch. تصدّر هذه الأداة نماذج PyTorch إلى نماذج LiteRT متعددة التوقيعات (.tflite) المتوافقة مع MediaPipe LLM Inference API والمناسبة للتشغيل على الخلفيات المستندة إلى وحدة المعالجة المركزية في تطبيقات الأجهزة الجوّالة.
ملف .task النهائي هو حزمة مستقلة يتطلّبها MediaPipe،
وهي تجمع بين نموذج LiteRT ونموذج الترميز والبيانات الوصفية الأساسية. هذه الحزمة ضرورية لأنّ أداة الترميز (التي تحوّل الطلبات النصية إلى تضمينات رموز مميزة للنموذج) يجب أن تكون مضمّنة في نموذج LiteRT لتفعيل الاستدلال الشامل.
في ما يلي شرح تفصيلي للعملية:
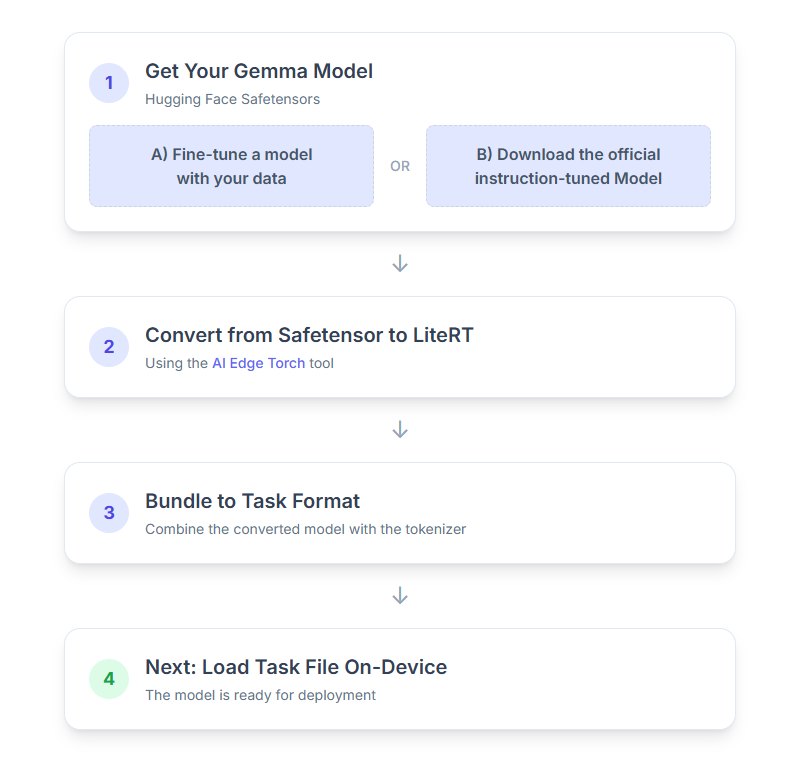
1. الحصول على نموذج Gemma
أمامك خياران للبدء.
الخيار (أ) استخدام نموذج معدَّل حالي
إذا كان لديك نموذج Gemma معدَّل بدقة جاهز، ما عليك سوى الانتقال إلى الخطوة التالية.
الخيار "ب" تنزيل النموذج الرسمي المضبوط على التعليمات
إذا كنت بحاجة إلى نموذج، يمكنك تنزيل نموذج Gemma محسَّن بالتعليمات من Hugging Face Hub.
إعداد الأدوات اللازمة:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
تنزيل النموذج:
يتم تحديد النماذج على Hugging Face Hub من خلال معرّف نموذج، ويكون عادةً بالتنسيق <organization_or_username>/<model_name>. على سبيل المثال، لتنزيل نموذج Gemma 3 270M الرسمي المحسَّن بالتعليمات من Google، استخدِم ما يلي:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. تحويل النموذج وتكميمه إلى LiteRT
يمكنك إعداد بيئة افتراضية للغة Python وتثبيت أحدث إصدار ثابت من حزمة LiteRT Torch باتّباع الخطوات التالية:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
استخدِم النص البرمجي التالي لتحويل Safetensor إلى نموذج LiteRT.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
يُرجى العِلم أنّ هذه العملية تستغرق وقتًا طويلاً وتعتمد على سرعة معالجة جهاز الكمبيوتر. للعلم، على وحدة معالجة مركزية (CPU) ثمانية النواة من طراز 2025، يستغرق نموذج بحجم 270 مليون معلَمة أكثر من 5 إلى 10 دقائق، بينما قد يستغرق نموذج بحجم مليار معلَمة من 10 إلى 30 دقيقة تقريبًا.
سيتم حفظ الناتج النهائي، وهو نموذج LiteRT، في
OUTPUT_DIR_PATH الذي حدّدته.
اضبط القيم التالية استنادًا إلى قيود الذاكرة والأداء في جهازك المستهدف.
-
kv_cache_max_len: تحدّد هذه السمة إجمالي حجم الذاكرة العاملة المخصّصة للنموذج (ذاكرة التخزين المؤقت KV). هذه السعة هي حدّ أقصى ثابت ويجب أن تكون كافية لتخزين المجموع المدمج للرموز المميزة الخاصة بالطلب (التعبئة المسبقة) وجميع الرموز المميزة التي تم إنشاؤها لاحقًا (فك التشفير). -
prefill_seq_len: تحدّد هذه السمة عدد الرموز المميّزة لطلب الإدخال من أجل تقسيم المحتوى إلى أجزاء. عند معالجة طلب الإدخال باستخدام تقسيم التعبئة المسبقة، يتم تقسيم التسلسل الكامل (مثل 50,000 رمز مميز) في وقت واحد، بل يتم تقسيمها إلى أجزاء يمكن إدارتها (مثل أجزاء من 2,048 رمزًا مميزًا) يتم تحميلها بالتسلسل في ذاكرة التخزين المؤقت لمنع حدوث خطأ في نفاد الذاكرة. -
quantize: سلسلة لأنظمة التكميم المحدّدة في ما يلي قائمة بوصفات التكميم المتاحة لطراز Gemma 3.none: ما مِن تحديد كمّي-
fp16: أوزان FP16 وعمليات التنشيط FP32 وعمليات حسابية بنقطة عائمة لجميع العمليات dynamic_int8: عمليات التنشيط FP32 والأوزان INT8 والحسابات الصحيحة-
weight_only_int8: عمليات التنشيط FP32 والأوزان INT8 والحسابات ذات الفاصلة العائمة
3- إنشاء حزمة مهام من LiteRT وtokenizer
إعداد بيئة Python افتراضية وتثبيت حزمة mediapipe Python:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
استخدِم مكتبة genai.bundler لتجميع النموذج:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
تنشئ الدالة bundler.create_bundle ملف .task يحتوي على جميع المعلومات اللازمة لتشغيل النموذج.
4. الاستدلال باستخدام Mediapipe على Android
ابدأ المهمة باستخدام خيارات الإعداد الأساسية:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
استخدِم طريقة generateResponse() لإنشاء ردّ نصي.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
لبث الرد، استخدِم الطريقة generateResponseAsync().
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
اطّلِع على دليل استنتاج النماذج اللغوية الكبيرة على Android للحصول على مزيد من المعلومات.
الخطوات التالية
يمكنك إنشاء المزيد واستكشافه باستخدام نماذج Gemma: