
|
|
|
|
|
 عرض المصدر على GitHub عرض المصدر على GitHub
|
يرشدك هذا الدليل إلى كيفية ضبط Gemma على مجموعة بيانات لشخصيات غير قابلة للعب في لعبة على الأجهزة الجوّالة باستخدام Transformers وTRL من Hugging Face. ستتعرّف على:
- إعداد بيئة التطوير
- إعداد مجموعة بيانات الضبط الدقيق
- ضبط نموذج Gemma بالكامل باستخدام مكتبة TRL وSFTTrainer
- اختبار استنتاج النماذج والتحقّق من الأجواء
إعداد بيئة التطوير
الخطوة الأولى هي تثبيت مكتبات Hugging Face، بما في ذلك TRL ومجموعات البيانات لضبط النموذج المفتوح بدقة، بما في ذلك تقنيات مختلفة لتعزيز التعلّم من خلال ردود الفعل البشرية (RLHF) والمواءمة.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
ملاحظة: إذا كنت تستخدم وحدة معالجة الرسومات (GPU) ببنية Ampere (مثل NVIDIA L4) أو أحدث، يمكنك استخدام Flash attention. Flash Attention هي طريقة تسرّع العمليات الحسابية بشكل كبير وتقلّل من استخدام الذاكرة من تربيعي إلى خطي في طول التسلسل، ما يؤدي إلى تسريع التدريب بمقدار 3 مرات. يمكنك الاطّلاع على مزيد من المعلومات على FlashAttention.
قبل بدء التدريب، عليك التأكّد من قبول بنود استخدام Gemma. يمكنك قبول الترخيص على Hugging Face من خلال النقر على الزر "الموافقة والوصول إلى المستودع" في صفحة النموذج على الرابط: http://huggingface.co/google/gemma-3-270m-it
بعد قبول الترخيص، تحتاج إلى رمز مميّز صالح من Hugging Face للوصول إلى النموذج. إذا كنت تستخدم Google Colab، يمكنك استخدام رمز Hugging Face Token بشكل آمن من خلال أسرار Colab، وإلا يمكنك ضبط الرمز المميز مباشرةً في طريقة login. تأكَّد من أنّ الرمز المميّز لديه إذن الوصول للكتابة أيضًا، لأنّك ستنقل النموذج إلى Hub أثناء التدريب.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
يمكنك الاحتفاظ بالنتائج على الجهاز الافتراضي المحلي في Colab. ومع ذلك، ننصحك بشدة بحفظ نتائجك المؤقتة في Google Drive. يضمن ذلك أمان نتائج التدريب ويسمح لك بسهولة مقارنة أفضل النماذج واختيارها.
from google.colab import drive
drive.mount('/content/drive')
اختَر النموذج الأساسي الذي تريد ضبطه بدقة، وعدِّل دليل نقاط التحقّق ومعدّل التعلّم.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
إنشاء مجموعة بيانات الضبط الدقيق وإعدادها
تقدّم مجموعة البيانات bebechien/MobileGameNPC عيّنة صغيرة من المحادثات بين لاعب وشخصيتَين من الشخصيات غير القابلة للعب (فضائي من المريخ وفضائي من الزهرة)، ولكل منهما أسلوب تحدث فريد. على سبيل المثال، يتحدث شخصية غير قابلة للعب من المريخ بلكنة تستبدل أصوات "س" بأصوات "ز"، وتستخدم "دا" بدلاً من "ال"، و"ديز" بدلاً من "هذا"، وتتضمّن نقرات عرضية مثل *k'tak*.
توضّح مجموعة البيانات هذه مبدأً أساسيًا للضبط الدقيق: يعتمد حجم مجموعة البيانات المطلوبة على الناتج المطلوب.
- لتعليم النموذج أسلوبًا مختلفًا من لغة يعرفها، مثل لهجة المريخيين، يمكن أن تكون مجموعة بيانات صغيرة تحتوي على 10 إلى 20 مثالاً فقط كافية.
- ومع ذلك، لتعليم النموذج لغة فضائية جديدة أو مختلطة تمامًا، يجب توفير مجموعة بيانات أكبر بكثير.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
ضبط Gemma بدقة باستخدام TRL وSFTTrainer
أنت الآن جاهز لضبط النموذج بدقة. تسهّل أداة SFTTrainer من Hugging Face TRL عملية الإشراف على الضبط الدقيق لنماذج اللغات الكبيرة المفتوحة. SFTTrainer هو فئة فرعية من Trainer من مكتبة transformers ويتوافق مع جميع الميزات نفسها.
يحمّل الرمز التالي نموذج Gemma وأداة الترميز من Hugging Face.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
قبل الضبط الدقيق
يوضّح الناتج أدناه أنّ الإمكانات الجاهزة للاستخدام قد لا تكون مناسبة لحالة الاستخدام هذه.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
يتحقّق المثال أعلاه من الوظيفة الأساسية للنموذج، وهي إنشاء حوار داخل اللعبة، بينما تم تصميم المثال التالي لاختبار اتّساق الشخصية. نختبر النموذج باستخدام طلب غير ذي صلة بالموضوع. على سبيل المثال، Sorry, you are a game NPC.، التي تقع خارج قاعدة معلومات الشخصية.
الهدف هو معرفة ما إذا كان النموذج يمكنه الحفاظ على شخصيته بدلاً من الإجابة عن السؤال غير ذي الصلة. سيكون هذا بمثابة خط أساس لتقييم مدى فعالية عملية الضبط الدقيق في غرس الشخصية المطلوبة.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
وعلى الرغم من أنّه يمكننا استخدام هندسة الطلبات لتوجيه أسلوبها، يمكن أن تكون النتائج غير متوقّعة وقد لا تتوافق دائمًا مع الشخصية التي نريدها.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
التدريب
قبل أن تتمكّن من بدء التدريب، عليك تحديد المعلمات الفائقة التي تريد استخدامها في مثيل SFTConfig.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
أصبح لديك الآن كلّ لبنات البناء التي تحتاج إليها لإنشاء SFTTrainer من أجل بدء تدريب نموذجك.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
ابدأ التدريب من خلال استدعاء الطريقة train().
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
لرسم خسائر التدريب والتحقّق من الصحة، عليك عادةً استخراج هذه القيم من الكائن TrainerState أو السجلات التي تم إنشاؤها أثناء التدريب.
يمكن بعد ذلك استخدام مكتبات مثل Matplotlib لعرض هذه القيم بشكل مرئي على مدار خطوات التدريب أو الفترات. سيمثّل المحور السيني خطوات التدريب أو عدد مرات التكرار، وسيمثّل المحور الصادي قيم الخسارة المقابلة.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
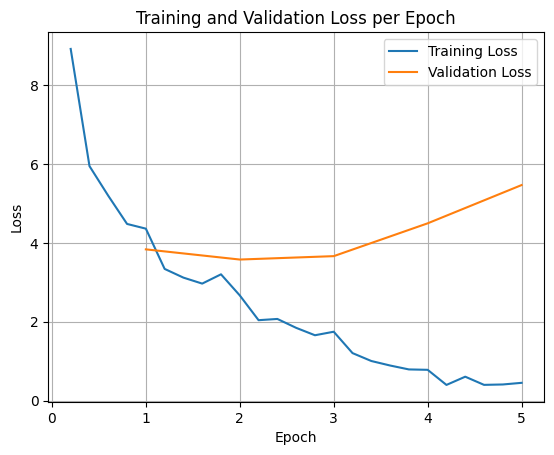
يساعد هذا التمثيل المرئي في مراقبة عملية التدريب واتّخاذ قرارات مدروسة بشأن ضبط المعلمات الفائقة أو الإيقاف المبكر.
يقيس خطأ التدريب الخطأ في البيانات التي تم تدريب النموذج عليها، بينما يقيس خطأ التحقّق من الصحة الخطأ في مجموعة بيانات منفصلة لم يسبق للنموذج أن اطّلع عليها. تساعد مراقبة كليهما في رصد فرط التخصيص (عندما يعمل النموذج بشكل جيد على بيانات التدريب ولكن بشكل غير جيد على البيانات غير المرئية).
- فقدان التحقّق من الصحة >> فقدان التدريب: الإفراط في التعلّم
- فقدان صحة البيانات > فقدان صحة التدريب: بعض الملاءمة الزائدة
- فقدان التحقّق < فقدان التدريب: بعض حالات نقص الملاءمة
- فقدان التحقّق << فقدان التدريب: نقص الملاءمة
اختبار استنتاج النموذج
بعد اكتمال التدريب، عليك تقييم النموذج واختباره. يمكنك تحميل عيّنات مختلفة من مجموعة بيانات الاختبار وتقييم النموذج استنادًا إلى هذه العيّنات.
في حالة الاستخدام هذه، يعتمد اختيار النموذج الأفضل على التفضيلات الشخصية. من المثير للاهتمام أنّ ما نسمّيه عادةً "الملاءمة المفرطة" يمكن أن يكون مفيدًا جدًا لشخصية غير قابلة للعب في لعبة. ويجبر النموذج على نسيان المعلومات العامة والتركيز بدلاً من ذلك على الشخصية والخصائص المحددة التي تم تدريبه عليها، ما يضمن بقاءه متوافقًا مع الشخصية.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
لنحمّل الآن جميع الأسئلة من مجموعة بيانات الاختبار وننشئ النتائج.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
إذا جرّبت طلبنا الأصلي المتعلّق بالمعلومات العامة، يمكنك ملاحظة أنّ النموذج لا يزال يحاول الإجابة بالأسلوب الذي تم تدريبه عليه. في هذا المثال، يكون الإفراط في التكيّف والنسيان الكارثي مفيدًا لشخصية غير قابلة للعب في اللعبة لأنّها ستبدأ في نسيان المعلومات العامة التي قد لا تكون قابلة للتطبيق. وينطبق ذلك أيضًا على الأنواع الأخرى من الضبط الدقيق الكامل حيث يكون الهدف هو حصر الناتج في تنسيقات بيانات محدّدة.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
الملخّص والخطوات التالية
تضمّن هذا البرنامج التعليمي كيفية إجراء عملية الضبط الدقيق للنموذج الكامل باستخدام TRL. يمكنك الاطّلاع على المستندات التالية: