
এই নির্দেশিকাটি Hugging Face Safetensors ফর্ম্যাট ( .safetensors ) এর Gemma মডেলগুলিকে MediaPipe Task ফাইল ফর্ম্যাট ( .task ) এ রূপান্তর করার নির্দেশাবলী প্রদান করে। MediaPipe LLM Inference API এবং LiterRT রানটাইম ব্যবহার করে Android এবং iOS-এ অন-ডিভাইস ইনফারেন্সের জন্য প্রাক-প্রশিক্ষিত বা সূক্ষ্ম-সুরক্ষিত Gemma মডেলগুলি স্থাপনের জন্য এই রূপান্তরটি অপরিহার্য।
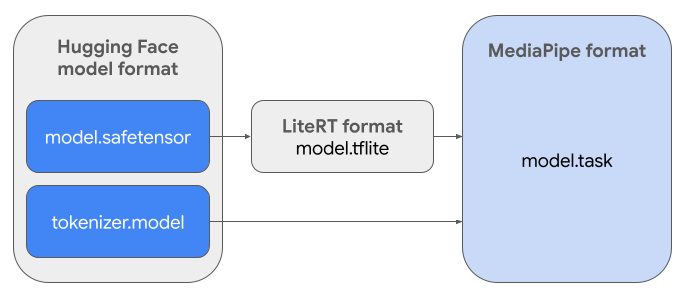
প্রয়োজনীয় টাস্ক বান্ডেল ( .task ) তৈরি করতে, আপনি Litert Torch ব্যবহার করবেন। এই টুলটি PyTorch মডেলগুলিকে মাল্টি-সিগনেচার Litert ( .tflite ) মডেলগুলিতে রপ্তানি করে, যা MediaPipe LLM ইনফারেন্স API এর সাথে সামঞ্জস্যপূর্ণ এবং মোবাইল অ্যাপ্লিকেশনগুলিতে CPU ব্যাকএন্ডে চালানোর জন্য উপযুক্ত।
চূড়ান্ত .task ফাইলটি MediaPipe-এর জন্য প্রয়োজনীয় একটি স্বয়ংসম্পূর্ণ প্যাকেজ, যা LiterRT মডেল, টোকেনাইজার মডেল এবং প্রয়োজনীয় মেটাডেটা একত্রিত করে। এই বান্ডেলটি প্রয়োজনীয় কারণ টোকেনাইজার (যা মডেলের জন্য টেক্সট প্রম্পটগুলিকে টোকেন এম্বেডিংয়ে রূপান্তর করে) এন্ড-টু-এন্ড ইনফারেন্স সক্ষম করার জন্য LiterRT মডেলের সাথে প্যাকেজ করা আবশ্যক।
এখানে প্রক্রিয়াটির ধাপে ধাপে বিশদ বিবরণ দেওয়া হল:
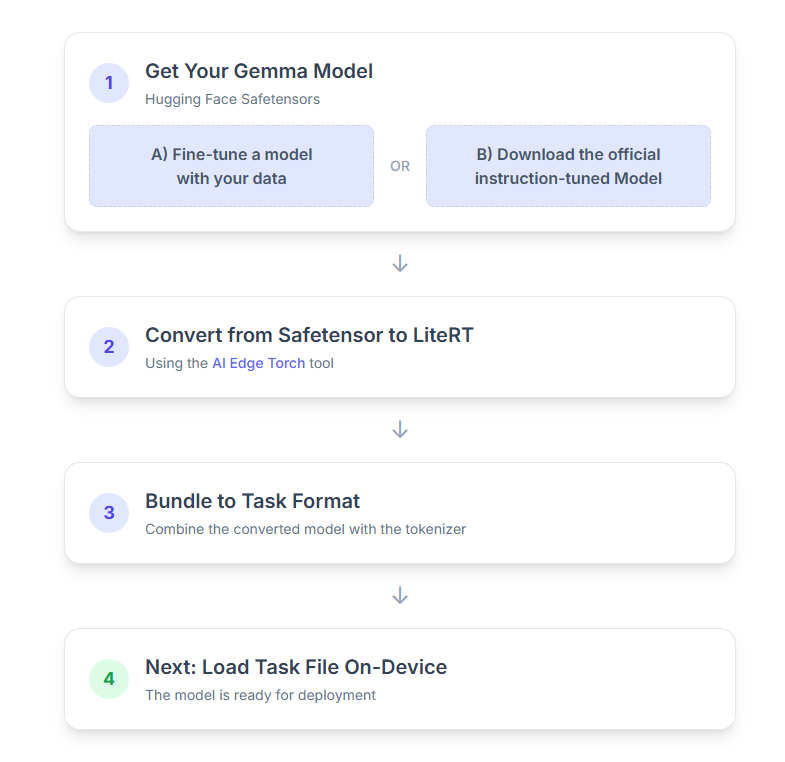
১. আপনার জেমা মডেলটি পান
শুরু করার জন্য আপনার কাছে দুটি বিকল্প আছে।
বিকল্প A. একটি বিদ্যমান সূক্ষ্ম সুরযুক্ত মডেল ব্যবহার করুন
যদি আপনার একটি সূক্ষ্মভাবে সুরক্ষিত জেমা মডেল প্রস্তুত থাকে, তাহলে পরবর্তী ধাপে এগিয়ে যান।
বিকল্প B. অফিসিয়াল নির্দেশ-টিউনড মডেলটি ডাউনলোড করুন
যদি আপনার একটি মডেলের প্রয়োজন হয়, তাহলে আপনি হাগিং ফেস হাব থেকে একটি নির্দেশ-টিউনড জেমা ডাউনলোড করতে পারেন।
প্রয়োজনীয় সরঞ্জাম সেটআপ করুন:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
মডেলটি ডাউনলোড করুন:
হাগিং ফেস হাবের মডেলগুলি একটি মডেল আইডি দ্বারা শনাক্ত করা হয়, সাধারণত <organization_or_username>/<model_name> ফর্ম্যাটে। উদাহরণস্বরূপ, অফিসিয়াল Google Gemma 3 270M নির্দেশ-টিউনড মডেল ডাউনলোড করতে, ব্যবহার করুন:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. মডেলটিকে LiterRT তে রূপান্তর এবং কোয়ান্টাইজ করুন
একটি পাইথন ভার্চুয়াল পরিবেশ সেট আপ করুন এবং LiteRT টর্চ প্যাকেজের সর্বশেষ স্থিতিশীল সংস্করণ ইনস্টল করুন:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
সেফটেন্সরকে LiterRT মডেলে রূপান্তর করতে নিম্নলিখিত স্ক্রিপ্টটি ব্যবহার করুন।
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
মনে রাখবেন যে এই প্রক্রিয়াটি সময়সাপেক্ষ এবং আপনার কম্পিউটারের প্রক্রিয়াকরণের গতির উপর নির্ভর করে। রেফারেন্সের জন্য, একটি 2025 8-কোর CPU-তে, একটি 270M মডেল 5-10 মিনিটেরও বেশি সময় নেয়, যেখানে একটি 1B মডেল প্রায় 10-30 মিনিট সময় নিতে পারে।
চূড়ান্ত আউটপুট, একটি LiterRT মডেল, আপনার নির্দিষ্ট OUTPUT_DIR_PATH এ সংরক্ষণ করা হবে।
আপনার টার্গেট ডিভাইসের মেমরি এবং কর্মক্ষমতা সীমাবদ্ধতার উপর ভিত্তি করে নিম্নলিখিত মানগুলি টিউন করুন।
-
kv_cache_max_len: মডেলের কার্যকরী মেমোরির (KV ক্যাশে) মোট বরাদ্দকৃত আকার নির্ধারণ করে। এই ক্ষমতা একটি হার্ড লিমিট এবং প্রম্পটের টোকেন (প্রিফিল) এবং পরবর্তীকালে তৈরি হওয়া সমস্ত টোকেন (ডিকোড) এর সম্মিলিত যোগফল সংরক্ষণ করার জন্য যথেষ্ট হতে হবে। -
prefill_seq_len: প্রিফিল চাঙ্কিংয়ের জন্য ইনপুট প্রম্পটের টোকেন গণনা নির্দিষ্ট করে। প্রিফিল চাঙ্কিং ব্যবহার করে ইনপুট প্রম্পট প্রক্রিয়াকরণের সময়, সম্পূর্ণ সিকোয়েন্স (যেমন, ৫০,০০০ টোকেন) একবারে গণনা করা হয় না; পরিবর্তে, এটি পরিচালনাযোগ্য অংশে বিভক্ত করা হয় (যেমন, ২,০৪৮ টোকেনের খণ্ড) যা মেমরির বাইরের ত্রুটি রোধ করার জন্য ক্যাশে ক্রমানুসারে লোড করা হয়। -
quantize: নির্বাচিত কোয়ান্টাইজেশন স্কিমের জন্য স্ট্রিং। জেমা 3 এর জন্য উপলব্ধ কোয়ান্টাইজেশন রেসিপিগুলির তালিকা নীচে দেওয়া হল।-
none: কোন পরিমাণ নির্ধারণ করা হয়নি -
fp16: সকল অপারেশনের জন্য FP16 ওজন, FP32 সক্রিয়করণ এবং ভাসমান বিন্দু গণনা -
dynamic_int8: FP32 অ্যাক্টিভেশন, INT8 ওজন এবং পূর্ণসংখ্যা গণনা -
weight_only_int8: FP32 অ্যাক্টিভেশন, INT8 ওজন এবং ফ্লোটিং পয়েন্ট গণনা
-
৩. LiterRT এবং টোকেনাইজার থেকে একটি টাস্ক বান্ডেল তৈরি করুন
একটি পাইথন ভার্চুয়াল পরিবেশ সেট আপ করুন এবং মিডিয়াপাইপ পাইথন প্যাকেজ ইনস্টল করুন:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
মডেলটি বান্ডেল করতে genai.bundler লাইব্রেরি ব্যবহার করুন:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
bundler.create_bundle ফাংশনটি একটি .task ফাইল তৈরি করে যাতে মডেলটি চালানোর জন্য প্রয়োজনীয় সমস্ত তথ্য থাকে।
৪. অ্যান্ড্রয়েডে মিডিয়াপাইপের সাথে অনুমান
মৌলিক কনফিগারেশন বিকল্পগুলি দিয়ে কাজটি শুরু করুন:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
একটি টেক্সট রেসপন্স তৈরি করতে generateResponse() পদ্ধতি ব্যবহার করুন।
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
প্রতিক্রিয়া স্ট্রিম করতে, generateResponseAsync() পদ্ধতিটি ব্যবহার করুন।
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
আরও তথ্যের জন্য অ্যান্ড্রয়েডের জন্য LLM ইনফারেন্স গাইড দেখুন।
পরবর্তী পদক্ষেপ
জেমা মডেলগুলির সাথে আরও তৈরি করুন এবং অন্বেষণ করুন: