
| | | | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন |
হাগিং ফেস ট্রান্সফরমার এবং টিআরএল ব্যবহার করে মোবাইল গেম NPC ডেটাসেটে জেমাকে কীভাবে সূক্ষ্ম-টিউন করা যায় এই নির্দেশিকাটি আপনাকে নির্দেশ করে। আপনি শিখবেন:
- উন্নয়ন পরিবেশ সেটআপ করুন
- ফাইন-টিউনিং ডেটাসেট প্রস্তুত করুন
- TRL এবং SFTTtrainer ব্যবহার করে সম্পূর্ণ মডেল ফাইন-টিউনিং জেমা
- মডেল ইনফারেন্স এবং ভাইব চেক পরীক্ষা করুন
উন্নয়ন পরিবেশ সেটআপ করুন
প্রথম ধাপ হল টিআরএল সহ হাগিং ফেস লাইব্রেরি এবং বিভিন্ন RLHF এবং প্রান্তিককরণ কৌশল সহ ওপেন মডেলকে ফাইন-টিউন করার জন্য ডেটাসেট ইনস্টল করা।
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
দ্রষ্টব্য: আপনি যদি অ্যাম্পিয়ার আর্কিটেকচারের (যেমন NVIDIA L4) বা আরও নতুন GPU ব্যবহার করেন, তাহলে আপনি ফ্ল্যাশ মনোযোগ ব্যবহার করতে পারেন। ফ্ল্যাশ অ্যাটেনশন হল এমন একটি পদ্ধতি যা উল্লেখযোগ্যভাবে গণনার গতি বাড়ায় এবং ক্রম দৈর্ঘ্যে চতুর্মুখী থেকে রৈখিক পর্যন্ত মেমরির ব্যবহার কমিয়ে দেয়, যা 3x পর্যন্ত প্রশিক্ষণকে ত্বরান্বিত করে। FlashAttention এ আরও জানুন।
আপনি প্রশিক্ষণ শুরু করার আগে, আপনাকে নিশ্চিত করতে হবে যে আপনি জেমার ব্যবহারের শর্তাবলী স্বীকার করেছেন। আপনি এখানে মডেল পৃষ্ঠায় Agree এবং অ্যাক্সেস সংগ্রহস্থল বোতামে ক্লিক করে Hugging Face- এর লাইসেন্স গ্রহণ করতে পারেন: http://huggingface.co/google/gemma-3-270m-it
আপনি লাইসেন্স গ্রহণ করার পরে, মডেলটি অ্যাক্সেস করার জন্য আপনার একটি বৈধ আলিঙ্গন ফেস টোকেন প্রয়োজন। আপনি যদি একটি Google Colab-এর মধ্যে দৌড়াচ্ছেন, তাহলে আপনি Colab গোপনীয়তাগুলি ব্যবহার করে আপনার আলিঙ্গন ফেস টোকেন নিরাপদে ব্যবহার করতে পারেন অন্যথায় আপনি login পদ্ধতিতে সরাসরি টোকেন সেট করতে পারেন। নিশ্চিত করুন যে আপনার টোকেনে লেখার অ্যাক্সেসও রয়েছে, কারণ আপনি প্রশিক্ষণের সময় আপনার মডেলকে হাবের দিকে ঠেলে দেন।
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
আপনি Colab-এর স্থানীয় ভার্চুয়াল মেশিনে ফলাফল রাখতে পারেন। যাইহোক, আমরা আপনার মধ্যবর্তী ফলাফলগুলিকে আপনার Google ড্রাইভে সংরক্ষণ করার সুপারিশ করছি। এটি নিশ্চিত করে যে আপনার প্রশিক্ষণের ফলাফল নিরাপদ এবং আপনাকে সহজে তুলনা করতে এবং সেরা মডেল নির্বাচন করতে দেয়।
from google.colab import drive
drive.mount('/content/drive')
ফাইন-টিউন করতে বেস মডেল নির্বাচন করুন, চেকপয়েন্ট ডিরেক্টরি এবং শেখার হার সামঞ্জস্য করুন।
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
ফাইন-টিউনিং ডেটাসেট তৈরি করুন এবং প্রস্তুত করুন
bebechien/MobileGameNPC ডেটাসেট একটি প্লেয়ার এবং দুটি এলিয়েন NPC-এর (একটি মঙ্গলযান এবং একটি ভেনুসিয়ান) মধ্যে একটি ছোট নমুনা কথোপকথন প্রদান করে, প্রতিটি একটি অনন্য বলার শৈলী সহ। উদাহরণস্বরূপ, Martian NPC একটি উচ্চারণে কথা বলে যা 's' ধ্বনিকে 'z' দিয়ে প্রতিস্থাপন করে, 'the'-এর জন্য 'da' ব্যবহার করে, 'this'-এর জন্য 'diz' ব্যবহার করে এবং মাঝে মাঝে ক্লিক যেমন *k'tak* অন্তর্ভুক্ত করে।
এই ডেটাসেটটি সূক্ষ্ম-টিউনিংয়ের জন্য একটি মূল নীতি প্রদর্শন করে: প্রয়োজনীয় ডেটাসেটের আকার পছন্দসই আউটপুটের উপর নির্ভর করে।
- মডেলটিকে এমন একটি ভাষার স্টাইলিস্টিক বৈচিত্র শেখানোর জন্য যা এটি ইতিমধ্যেই জানে, যেমন মার্টিনের উচ্চারণ, 10 থেকে 20টি উদাহরণ সহ একটি ছোট ডেটাসেট যথেষ্ট হতে পারে।
- যাইহোক, মডেলটিকে একটি সম্পূর্ণ নতুন বা মিশ্র এলিয়েন ভাষা শেখাতে, একটি উল্লেখযোগ্যভাবে বড় ডেটাসেটের প্রয়োজন হবে।
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
TRL এবং SFTTtrainer ব্যবহার করে Gemma ফাইন-টিউন করুন
আপনি এখন আপনার মডেল সূক্ষ্ম-টিউন করতে প্রস্তুত. আলিঙ্গন ফেস TRL SFTTrainer সূক্ষ্ম-টিউন ওপেন LLM তত্ত্বাবধান করা সহজ করে তোলে। SFTTrainer হল transformers লাইব্রেরি থেকে Trainer একটি সাবক্লাস এবং সমস্ত একই বৈশিষ্ট্য সমর্থন করে,
নিচের কোডটি হ্যাগিং ফেস থেকে জেমা মডেল এবং টোকেনাইজার লোড করে।
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
ফাইন-টিউন করার আগে
নীচের আউটপুট দেখায় যে এই ব্যবহারের ক্ষেত্রে বাক্সের বাইরের ক্ষমতাগুলি যথেষ্ট ভাল নাও হতে পারে৷
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
উপরের উদাহরণটি ইন-গেম সংলাপ তৈরি করার মডেলের প্রাথমিক ফাংশন পরীক্ষা করে, পরবর্তী উদাহরণটি চরিত্রের সামঞ্জস্য পরীক্ষা করার জন্য ডিজাইন করা হয়েছে। আমরা একটি অফ-টপিক প্রম্পট সহ মডেলটিকে চ্যালেঞ্জ করি। উদাহরণস্বরূপ, Sorry, you are a game NPC. , যা চরিত্রের জ্ঞানের ভিত্তির বাইরে পড়ে।
লক্ষ্য হল প্রেক্ষাপটের বাইরের প্রশ্নের উত্তর দেওয়ার পরিবর্তে মডেল চরিত্রে থাকতে পারে কিনা তা দেখা। সূক্ষ্ম সুর প্রক্রিয়াটি কতটা কার্যকরভাবে কাঙ্খিত ব্যক্তিত্ব তৈরি করেছে তা মূল্যায়ন করার জন্য এটি একটি বেসলাইন হিসাবে কাজ করবে।
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
এবং যখন আমরা প্রম্পট ইঞ্জিনিয়ারিং ব্যবহার করতে পারি তার টোন বাড়ানোর জন্য, ফলাফলগুলি অপ্রত্যাশিত হতে পারে এবং সবসময় আমাদের পছন্দের ব্যক্তিত্বের সাথে সারিবদ্ধ নাও হতে পারে।
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
প্রশিক্ষণ
আপনি আপনার প্রশিক্ষণ শুরু করার আগে, আপনি একটি SFTConfig উদাহরণে ব্যবহার করতে চান এমন হাইপারপ্যারামিটারগুলিকে সংজ্ঞায়িত করতে হবে।
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
আপনার মডেলের প্রশিক্ষণ শুরু করার জন্য আপনার SFTTrainer তৈরি করতে আপনার প্রয়োজনীয় প্রতিটি বিল্ডিং ব্লক রয়েছে।
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
train() পদ্ধতিতে কল করে প্রশিক্ষণ শুরু করুন।
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
প্রশিক্ষণ এবং বৈধতা ক্ষতির প্লট করতে, আপনি সাধারণত TrainerState অবজেক্ট বা প্রশিক্ষণের সময় উত্পন্ন লগগুলি থেকে এই মানগুলি বের করবেন।
ম্যাটপ্লটলিবের মতো লাইব্রেরিগুলিকে প্রশিক্ষণের ধাপ বা যুগের উপর এই মানগুলি কল্পনা করতে ব্যবহার করা যেতে পারে। এক্স-অ্যাসিস প্রশিক্ষণের ধাপ বা যুগের প্রতিনিধিত্ব করবে, এবং y-অক্ষ সংশ্লিষ্ট ক্ষতির মানগুলিকে প্রতিনিধিত্ব করবে।
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
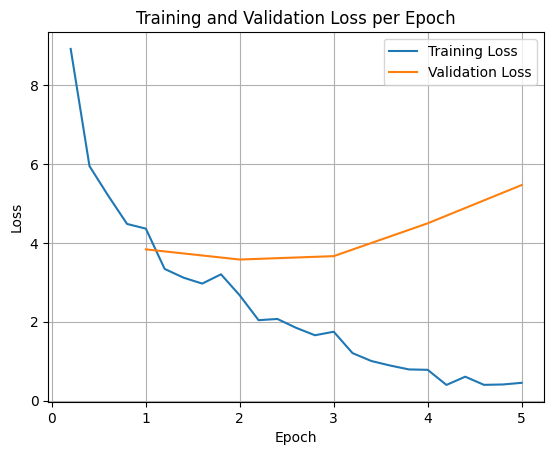
এই ভিজ্যুয়ালাইজেশন প্রশিক্ষণ প্রক্রিয়া নিরীক্ষণ এবং হাইপারপ্যারামিটার টিউনিং বা তাড়াতাড়ি বন্ধ করার বিষয়ে জ্ঞাত সিদ্ধান্ত নিতে সাহায্য করে।
ট্রেনিং লস মডেলটিকে যে ডেটাতে প্রশিক্ষিত করা হয়েছিল তার ত্রুটি পরিমাপ করে, যখন বৈধতা ক্ষতি একটি পৃথক ডেটাসেটে ত্রুটি পরিমাপ করে যা মডেলটি আগে দেখেনি৷ উভয়ই পর্যবেক্ষণ করা ওভারফিটিং সনাক্ত করতে সহায়তা করে (যখন মডেল প্রশিক্ষণ ডেটাতে ভাল পারফর্ম করে তবে অদেখা ডেটাতে খারাপভাবে)।
- বৈধতা ক্ষতি >> প্রশিক্ষণ ক্ষতি: অতিরিক্ত ফিটিং
- বৈধতা ক্ষতি > প্রশিক্ষণ ক্ষতি: কিছু অতিরিক্ত ফিটিং
- বৈধতা ক্ষতি < প্রশিক্ষণ ক্ষতি: কিছু আন্ডারফিটিং
- বৈধতা ক্ষতি << প্রশিক্ষণ ক্ষতি: আন্ডারফিটিং
টেস্ট মডেল ইনফারেন্স
প্রশিক্ষণ শেষ হওয়ার পরে, আপনি আপনার মডেলের মূল্যায়ন এবং পরীক্ষা করতে চাইবেন। আপনি পরীক্ষার ডেটাসেট থেকে বিভিন্ন নমুনা লোড করতে পারেন এবং সেই নমুনাগুলিতে মডেলটির মূল্যায়ন করতে পারেন।
এই বিশেষ ব্যবহারের ক্ষেত্রে, সেরা মডেলটি পছন্দের বিষয়। মজার বিষয় হল, আমরা যাকে সাধারণত 'ওভারফিটিং' বলি তা একটি গেম এনপিসি-র জন্য খুব কার্যকর হতে পারে। এটি মডেলটিকে সাধারণ তথ্য ভুলে যেতে বাধ্য করে এবং এর পরিবর্তে এটি যে নির্দিষ্ট ব্যক্তিত্ব এবং বৈশিষ্ট্যগুলির উপর প্রশিক্ষিত হয়েছিল তা লক করে, এটি নিশ্চিত করে যে এটি চরিত্রে ধারাবাহিকভাবে থাকে।
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
আসুন পরীক্ষার ডেটাসেট থেকে সমস্ত প্রশ্ন লোড করি এবং আউটপুট তৈরি করি।
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
আপনি যদি আমাদের আসল জেনারেলিস্ট প্রম্পটটি চেষ্টা করেন, আপনি দেখতে পাবেন যে মডেলটি এখনও প্রশিক্ষিত শৈলীতে উত্তর দেওয়ার চেষ্টা করে। এই উদাহরণে অতিরিক্ত ফিটিং এবং বিপর্যয়কর ভুলে যাওয়া আসলে NPC গেমের জন্য উপকারী কারণ এটি সাধারণ জ্ঞান ভুলে যাওয়া শুরু করবে যা প্রযোজ্য নাও হতে পারে। এটি অন্যান্য ধরণের সম্পূর্ণ ফাইন-টিউনিংয়ের ক্ষেত্রেও সত্য যেখানে লক্ষ্য নির্দিষ্ট ডেটা ফর্ম্যাটে আউটপুট সীমাবদ্ধ করা।
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
সারাংশ এবং পরবর্তী পদক্ষেপ
এই টিউটোরিয়ালে টিআরএল ব্যবহার করে কিভাবে সম্পূর্ণ মডেল ফাইন-টিউন করা যায় তা কভার করা হয়েছে। পরবর্তীতে নিম্নলিখিত নথিগুলি দেখুন: