
Este guia fornece instruções para converter modelos do Gemma no formato Safetensors do Hugging Face (.safetensors) para o formato de arquivo de tarefa do MediaPipe (.task). Essa conversão é essencial para implantar modelos do Gemma pré-treinados ou ajustados para inferência no dispositivo em Android e iOS usando a API MediaPipe LLM Inference e o tempo de execução do LiteRT.

Para criar o pacote de tarefas necessário (.task), use o
LiteRT Torch. Essa ferramenta exporta modelos do PyTorch para modelos LiteRT (.tflite) de várias assinaturas, que são compatíveis com a API MediaPipe LLM Inference e adequados para execução em back-ends de CPU em aplicativos móveis.
O arquivo .task final é um pacote independente exigido pelo MediaPipe,
que agrupa o modelo LiteRT, o modelo de tokenização e os metadados essenciais. Esse pacote é necessário porque o tokenizador (que converte comandos de texto em embeddings de token para o modelo) precisa ser empacotado com o modelo LiteRT para ativar a inferência de ponta a ponta.
Confira um detalhamento do processo:
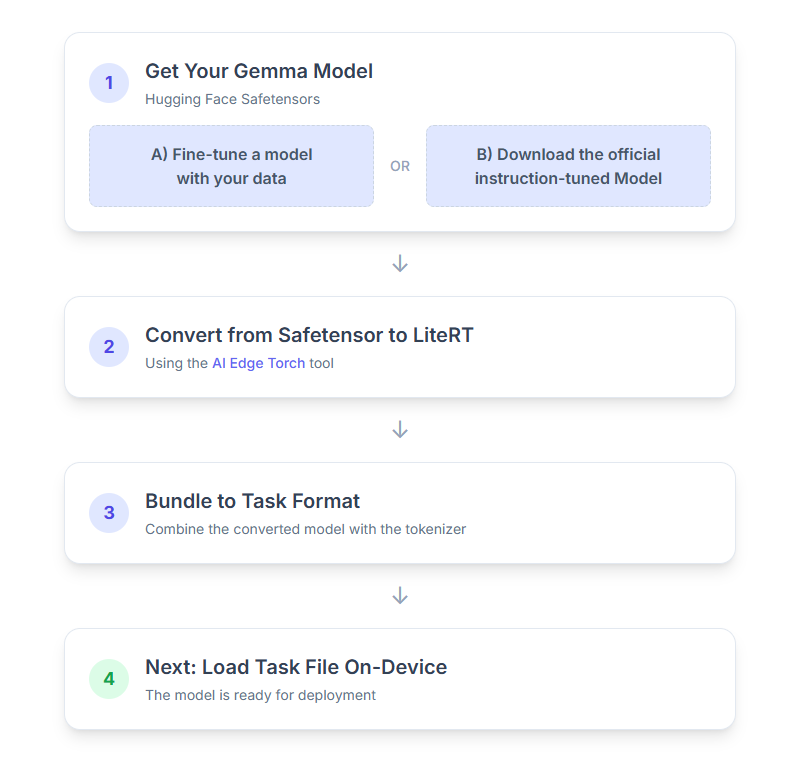
1. Receber seu modelo Gemma
Você tem duas opções para começar.
Opção A. Usar um modelo ajustado
Se você tiver um modelo da Gemma refinado, siga para a próxima etapa.
Opção B. Baixar o modelo oficial ajustado por instruções
Se você precisar de um modelo, baixe um Gemma ajustado com instruções do Hugging Face Hub.
Configurar as ferramentas necessárias:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
Faça o download do modelo:
Os modelos no Hugging Face Hub são identificados por um ID, geralmente no formato <organization_or_username>/<model_name>. Por exemplo, para fazer o download do modelo oficial do Google Gemma 3 270M ajustado com instruções, use:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. Converter e quantizar o modelo para LiteRT
Configure um ambiente virtual Python e instale a versão estável mais recente do pacote LiteRT Torch:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
Use o script a seguir para converter o Safetensor em um modelo LiteRT.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
Esse processo é demorado e depende da velocidade de processamento do seu computador. Para referência, em uma CPU de 8 núcleos de 2025, um modelo de 270 milhões leva mais de 5 a 10 minutos, enquanto um modelo de 1 bilhão pode levar de 10 a 30 minutos.
A saída final, um modelo LiteRT, será salva no OUTPUT_DIR_PATH especificado.
Ajuste os valores a seguir com base nas restrições de memória e desempenho do dispositivo de destino.
kv_cache_max_len: define o tamanho total alocado da memória de trabalho do modelo (o cache KV). Essa capacidade é um limite fixo e precisa ser suficiente para armazenar a soma combinada dos tokens do comando (o preenchimento automático) e todos os tokens gerados posteriormente (a decodificação).prefill_seq_len: especifica a contagem de tokens do comando de entrada para o agrupamento de preenchimento automático. Ao processar o comando de entrada usando o agrupamento de pré-preenchimento, toda a sequência (por exemplo, 50.000 tokens) não é calculado de uma só vez. Em vez disso, ele é dividido em segmentos gerenciáveis (por exemplo, blocos de 2.048 tokens) que são carregados sequencialmente no cache para evitar um erro de falta de memória.quantize: string para os esquemas de quantização selecionados. Confira a seguir a lista de receitas de quantização disponíveis para o Gemma 3.none: sem quantizaçãofp16: pesos FP16, ativações FP32 e computação de ponto flutuante para todas as operações.dynamic_int8: ativações FP32, pesos INT8 e computação de números inteirosweight_only_int8: ativações FP32, pesos INT8 e computação de ponto flutuante.
3. Criar um pacote de tarefas usando o LiteRT e o tokenizador
Configure um ambiente virtual do Python e instale o pacote do Python mediapipe:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
Use a biblioteca genai.bundler para agrupar o modelo:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
A função bundler.create_bundle cria um arquivo .task que contém todas as informações necessárias para executar o modelo.
4. Inferência com o MediaPipe no Android
Inicialize a tarefa com opções de configuração básicas:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
Use o método generateResponse() para gerar uma resposta de texto.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
Para fazer streaming da resposta, use o método generateResponseAsync().
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
Consulte o guia de inferência de LLM para Android para mais informações.
Próximas etapas
Crie e descubra mais com os modelos do Gemma: