
|
|
|
|
|
 Ver código-fonte no GitHub Ver código-fonte no GitHub
|
Neste guia, mostramos como ajustar o Gemma em um conjunto de dados de NPCs de jogos para dispositivos móveis usando as bibliotecas Transformers e TRL do Hugging Face. Você vai aprender:
- Configurar o ambiente de desenvolvimento
- Preparar o conjunto de dados de ajuste refinado
- Ajuste completo do modelo Gemma usando TRL e SFTTrainer
- Teste a inferência de modelo e as verificações de vibe
Configurar o ambiente de desenvolvimento
A primeira etapa é instalar as bibliotecas do Hugging Face, incluindo TRL e conjuntos de dados, para ajustar o modelo aberto, incluindo diferentes técnicas de RLHF e alinhamento.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
Observação: se você estiver usando uma GPU com arquitetura Ampere (como NVIDIA L4) ou mais recente, poderá usar a atenção rápida. O Flash Attention é um método que acelera significativamente os cálculos e reduz o uso de memória de quadrático para linear no comprimento da sequência, acelerando o treinamento em até 3 vezes. Saiba mais em FlashAttention.
Antes de começar o treinamento, verifique se você aceitou os Termos de Uso da Gemma. Para aceitar a licença no Hugging Face, clique no botão "Concordar e acessar o repositório" na página do modelo em: http://huggingface.co/google/gemma-3-270m-it
Depois de aceitar a licença, você vai precisar de um token do Hugging Face válido para acessar o modelo. Se você estiver executando em um Google Colab, use seu token do Hugging Face com segurança usando os secrets do Colab. Caso contrário, defina o token diretamente no método login. Verifique se o token também tem acesso de gravação, já que você vai enviar o modelo para o Hub durante o treinamento.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
Você pode manter os resultados na máquina virtual local do Colab. No entanto, recomendamos salvar os resultados intermediários no Google Drive. Isso garante que os resultados do treinamento estejam seguros e permite comparar e selecionar o melhor modelo com facilidade.
from google.colab import drive
drive.mount('/content/drive')
Selecione o modelo de base para ajuste fino, ajuste o diretório de checkpoint e a taxa de aprendizado.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
Criar e preparar o conjunto de dados de ajuste refinado
O conjunto de dados bebechien/MobileGameNPC oferece uma pequena amostra de conversas entre um jogador e dois NPCs alienígenas (um marciano e um venusiano), cada um com um estilo de fala exclusivo. Por exemplo, o NPC marciano fala com um sotaque que substitui os sons de "s" por "z", usa "da" em vez de "the", "diz" em vez de "this" e inclui cliques ocasionais como *k'tak*.
Esse conjunto de dados demonstra um princípio fundamental para o ajuste fino: o tamanho necessário do conjunto de dados depende da saída desejada.
- Para ensinar ao modelo uma variação estilística de um idioma que ele já conhece, como o sotaque marciano, um pequeno conjunto de dados com apenas 10 a 20 exemplos pode ser suficiente.
- No entanto, para ensinar ao modelo uma linguagem alienígena completamente nova ou mista, seria necessário um conjunto de dados significativamente maior.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
Ajustar o Gemma usando a TRL e o SFTTrainer
Agora está tudo pronto para ajustar seu modelo. O SFTTrainer da TRL do Hugging Face facilita a supervisão do ajuste fino de LLMs abertos. O SFTTrainer é uma subclasse do Trainer da biblioteca transformers e oferece suporte a todos os mesmos recursos.
O código a seguir carrega o modelo e o tokenizador do Gemma da Hugging Face.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
Antes do ajuste refinado
A saída abaixo mostra que os recursos prontos para uso podem não ser adequados para esse caso de uso.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
O exemplo acima verifica a função principal do modelo de gerar diálogos no jogo. O próximo exemplo foi criado para testar a consistência do personagem. Desafiamos o modelo com um comando fora do assunto. Por exemplo, Sorry, you are a game NPC., que está fora da base de conhecimento do personagem.
O objetivo é verificar se o modelo consegue manter o personagem em vez de responder à pergunta fora de contexto. Isso vai servir como um valor de referência para avaliar a eficácia do processo de ajuste fino na criação da persona desejada.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
Embora possamos usar a engenharia de comandos para direcionar o tom, os resultados podem ser imprevisíveis e nem sempre se alinham à persona desejada.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
Treinamento
Antes de iniciar o treinamento, defina os hiperparâmetros que você quer usar em uma instância SFTConfig.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
Agora você tem todos os elementos básicos necessários para criar seu SFTTrainer e iniciar o treinamento do modelo.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
Comece o treinamento chamando o método train().
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
Para representar as perdas de treinamento e validação, normalmente você extrai esses valores do objeto TrainerState ou dos registros gerados durante o treinamento.
Bibliotecas como Matplotlib podem ser usadas para visualizar esses valores em etapas ou épocas de treinamento. O eixo x representa as etapas ou épocas de treinamento, e o eixo y representa os valores de perda correspondentes.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
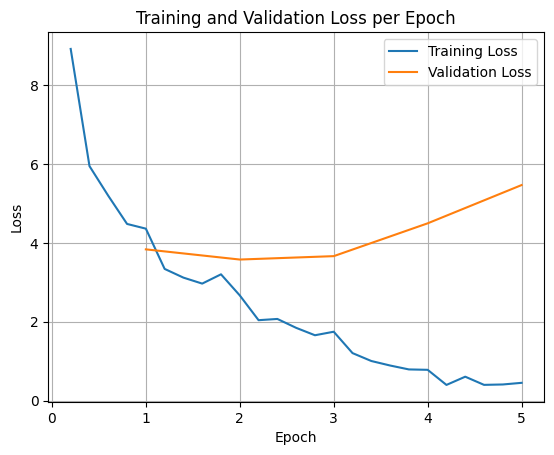
Essa visualização ajuda a monitorar o processo de treinamento e tomar decisões fundamentadas sobre o ajuste de hiperparâmetros ou a interrupção antecipada.
A perda de treinamento mede o erro nos dados em que o modelo foi treinado, enquanto a perda de validação mede o erro em um conjunto de dados separado que o modelo nunca viu antes. O monitoramento dos dois ajuda a detectar o overfitting (quando o modelo tem um bom desempenho com os dados de treinamento, mas ruim com os dados não visualizados).
- perda de validação >> perda de treinamento: overfitting
- perda de validação > perda de treinamento: algum overfitting
- perda de validação < perda de treinamento: algum underfitting
- perda de validação << perda de treinamento: subajuste
Teste da inferência do modelo
Depois do treinamento, avalie e teste o modelo. É possível carregar diferentes amostras do conjunto de dados de teste e avaliar o modelo nelas.
Para esse caso de uso específico, o melhor modelo é uma questão de preferência. Curiosamente, o que normalmente chamamos de "overfitting" pode ser muito útil para um NPC de jogo. Isso força o modelo a esquecer informações gerais e se concentrar na persona e nas características específicas com que foi treinado, garantindo que ele permaneça consistente.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Vamos carregar todas as perguntas do conjunto de dados de teste e gerar saídas.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
Se você testar nosso comando generalista original, vai perceber que o modelo ainda tenta responder no estilo treinado. Neste exemplo, o overfitting e o esquecimento catastrófico são benéficos para o NPC do jogo, porque ele começa a esquecer o conhecimento geral, que pode não ser aplicável. Isso também vale para outros tipos de ajuste fino completo em que o objetivo é restringir a saída a formatos de dados específicos.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
Resumo e próximas etapas
Este tutorial abordou como fazer o ajuste fino completo do modelo usando a TRL. Confira os seguintes documentos: