
คู่มือนี้มีวิธีการแปลงโมเดล Gemma ในรูปแบบ Safetensors ของ Hugging Face (.safetensors) เป็นรูปแบบไฟล์ของ MediaPipe Tasks
(.task) การแปลงนี้จำเป็นอย่างยิ่งสำหรับการติดตั้งใช้งานโมเดล Gemma ที่ผ่านการฝึกมาก่อนหรือ
การปรับแต่งอย่างละเอียดสำหรับการอนุมานในอุปกรณ์บน Android และ iOS โดยใช้
MediaPipe LLM Inference API และรันไทม์ LiteRT
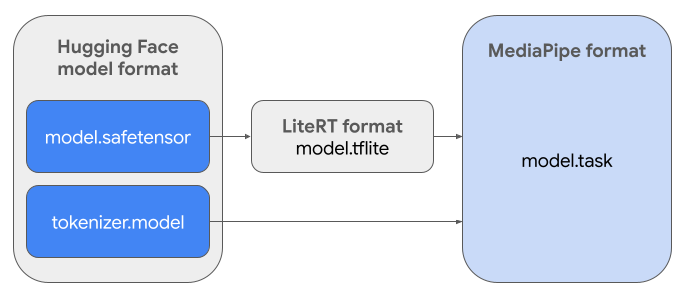
หากต้องการสร้าง Task Bundle (.task) ที่จำเป็น คุณจะต้องใช้
LiteRT Torch เครื่องมือนี้จะส่งออกโมเดล PyTorch เป็นโมเดล LiteRT (.tflite) แบบหลายลายเซ็น ซึ่งเข้ากันได้กับ
MediaPipe LLM Inference API และเหมาะสำหรับการเรียกใช้ในแบ็กเอนด์ CPU ในแอปพลิเคชันบนอุปกรณ์เคลื่อนที่
ไฟล์ .task สุดท้ายคือแพ็กเกจแบบสแตนด์อโลนที่ MediaPipe ต้องการ
ซึ่งรวมโมเดล LiteRT, โมเดลโทเค็นไนเซอร์ และข้อมูลเมตาที่จำเป็น ชุดนี้จำเป็นเนื่องจากต้องรวมโทเค็นไนเซอร์ (ซึ่งแปลงพรอมต์ข้อความเป็น
การฝังโทเค็นสำหรับโมเดล) ไว้กับโมเดล LiteRT เพื่อ
เปิดใช้การอนุมานแบบครบวงจร
รายละเอียดขั้นตอนการดำเนินการมีดังนี้
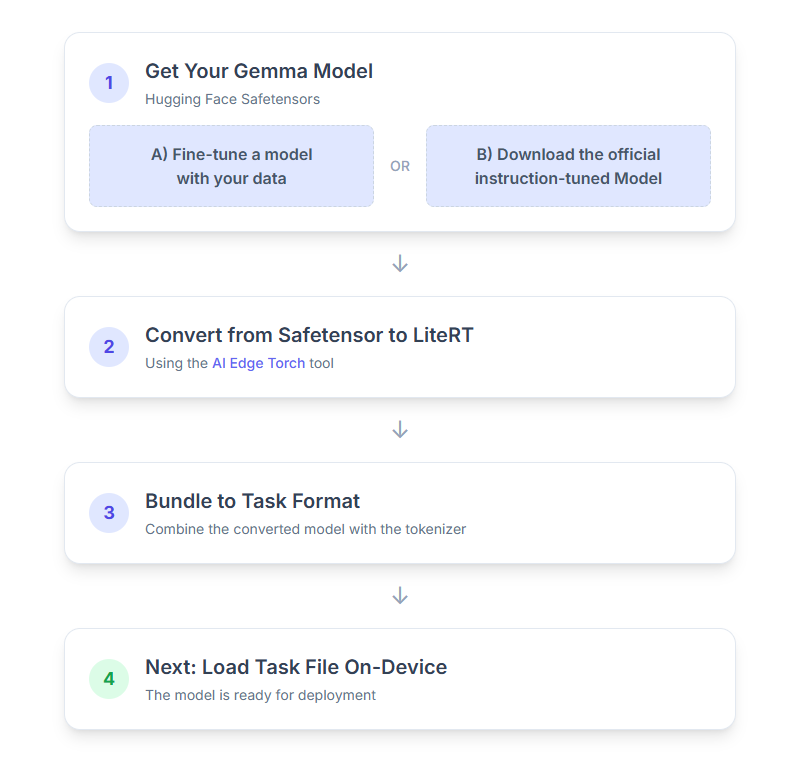
1. รับโมเดล Gemma
คุณมี 2 ตัวเลือกในการเริ่มต้นใช้งาน
ตัวเลือก ก ใช้โมเดลที่ปรับแต่งแล้วที่มีอยู่
หากคุณมีโมเดล Gemma ที่ปรับแต่งแล้ว ก็ให้ไปยัง ขั้นตอนถัดไปได้เลย
ตัวเลือก ข ดาวน์โหลดโมเดลที่ได้รับการปรับแต่งตามคำสั่งอย่างเป็นทางการ
หากต้องการโมเดล คุณสามารถดาวน์โหลด Gemma ที่ปรับแต่งตามคำสั่งได้จาก Hugging Face Hub
ตั้งค่าเครื่องมือที่จำเป็น
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
ดาวน์โหลดโมเดล
โมเดลใน Hugging Face Hub จะระบุด้วยรหัสโมเดล ซึ่งมักอยู่ในรูปแบบ <organization_or_username>/<model_name> ตัวอย่างเช่น หากต้องการดาวน์โหลดโมเดล Gemma 3 270M อย่างเป็นทางการของ Google ที่ได้รับการปรับแต่งตามคำสั่ง ให้ใช้คำสั่งต่อไปนี้
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. แปลงและลดขนาดโมเดลเป็น LiteRT
ตั้งค่าสภาพแวดล้อมเสมือนของ Python และติดตั้งรุ่นเสถียรล่าสุดของ แพ็กเกจ LiteRT Torch โดยทำดังนี้
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
ใช้สคริปต์ต่อไปนี้เพื่อแปลง Safetensor เป็นโมเดล LiteRT
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
โปรดทราบว่ากระบวนการนี้ใช้เวลานานและขึ้นอยู่กับความเร็วในการประมวลผลของคอมพิวเตอร์ โดยอ้างอิงจาก CPU 8 คอร์ปี 2025 โมเดล 270 ล้านพารามิเตอร์จะใช้เวลามากกว่า 5-10 นาที ส่วนโมเดล 1 พันล้านพารามิเตอร์อาจใช้เวลาประมาณ 10-30 นาที
ระบบจะบันทึกเอาต์พุตสุดท้ายซึ่งเป็นโมเดล LiteRT ไว้ในOUTPUT_DIR_PATHที่คุณระบุ
ปรับค่าต่อไปนี้ตามข้อจำกัดด้านหน่วยความจำและประสิทธิภาพของ อุปกรณ์เป้าหมาย
kv_cache_max_len: กำหนดขนาดที่จัดสรรทั้งหมดของหน่วยความจำที่ใช้ทำงานของโมเดล (แคช KV) ความจุนี้เป็นขีดจำกัดที่แน่นอนและต้องเพียงพอ ต่อการจัดเก็บผลรวมของโทเค็นของพรอมต์ (การเติมข้อความล่วงหน้า) และโทเค็นทั้งหมด ที่สร้างขึ้นในภายหลัง (การถอดรหัส)prefill_seq_len: ระบุจำนวนโทเค็นของพรอมต์อินพุตสำหรับการแบ่งกลุ่มการเติมล่วงหน้า เมื่อประมวลผลพรอมต์อินพุตโดยใช้การแบ่งกลุ่มการเติมข้อความล่วงหน้า ลำดับทั้งหมด (เช่น 50,000 โทเค็น) จะไม่ได้รับการประมวลผลพร้อมกัน แต่จะแบ่งออกเป็นส่วนที่จัดการได้ (เช่น กลุ่มโทเค็น 2,048 รายการ) ซึ่งจะโหลดตามลำดับลงในแคชเพื่อป้องกันข้อผิดพลาดหน่วยความจำไม่พอquantize: สตริงสำหรับรูปแบบการหาปริมาณที่เลือก ต่อไปนี้คือ รายการสูตรการหาปริมาณที่ใช้ได้สำหรับ Gemma 3none: ไม่มีการหาปริมาณfp16: น้ำหนัก FP16, การเปิดใช้งาน FP32 และการคำนวณแบบจุดลอยสำหรับ การดำเนินการทั้งหมดdynamic_int8: การเปิดใช้งาน FP32, น้ำหนัก INT8 และการคำนวณจำนวนเต็มweight_only_int8: การเปิดใช้งาน FP32, น้ำหนัก INT8 และการคำนวณแบบจุดลอยตัว
3. สร้างชุดงานจาก LiteRT และโทเค็นไนเซอร์
ตั้งค่าสภาพแวดล้อมเสมือนของ Python และติดตั้งแพ็กเกจ Python ของ MediaPipe โดยทำดังนี้
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
ใช้ไลบรารี genai.bundler เพื่อรวมโมเดล
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
ฟังก์ชัน bundler.create_bundle จะสร้างไฟล์ .task ที่มีข้อมูลที่จำเป็นทั้งหมด
ในการเรียกใช้โมเดล
4. การอนุมานด้วย MediaPipe ใน Android
เริ่มต้นงานด้วยตัวเลือกการกำหนดค่าพื้นฐาน
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
ใช้เมธอด generateResponse() เพื่อสร้างคำตอบเป็นข้อความ
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
หากต้องการสตรีมคำตอบ ให้ใช้วิธี generateResponseAsync()
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
ดูข้อมูลเพิ่มเติมได้ที่คู่มือการอนุมาน LLM สำหรับ Android
ขั้นตอนถัดไป
สร้างและสำรวจเพิ่มเติมด้วยโมเดล Gemma