
|
|
|
|
|
 ดูแหล่งข้อมูลใน GitHub ดูแหล่งข้อมูลใน GitHub
|
คู่มือนี้จะแนะนำวิธีปรับแต่ง Gemma ในชุดข้อมูล NPC ของเกมมือถือโดยใช้ Transformers ของ Hugging Face และ TRL คุณจะได้เรียนรู้:
- ตั้งค่าสภาพแวดล้อมในการพัฒนาซอฟต์แวร์
- เตรียมชุดข้อมูลการปรับแต่ง
- การปรับแต่งโมเดล Gemma แบบเต็มโดยใช้ TRL และ SFTTrainer
- ทดสอบการอนุมานโมเดลและการตรวจสอบบรรยากาศ
ตั้งค่าสภาพแวดล้อมในการพัฒนาซอฟต์แวร์
ขั้นตอนแรกคือการติดตั้งไลบรารี Hugging Face ซึ่งรวมถึง TRL และชุดข้อมูลเพื่อปรับแต่งโมเดลแบบเปิด ซึ่งรวมถึงเทคนิค RLHF และการจัดแนวต่างๆ
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
หมายเหตุ: หากใช้ GPU ที่มีสถาปัตยกรรม Ampere (เช่น NVIDIA L4) หรือใหม่กว่า คุณจะใช้ Flash Attention ได้ Flash Attention เป็นวิธีที่ช่วยเร่งการคำนวณได้อย่างมากและลดการใช้หน่วยความจำจากกำลังสองเป็นเชิงเส้นในความยาวของลำดับ ซึ่งช่วยเร่งการฝึกได้สูงสุด 3 เท่า ดูข้อมูลเพิ่มเติมได้ที่ FlashAttention
ก่อนเริ่มฝึก คุณต้องตรวจสอบว่าได้ยอมรับข้อกำหนดในการใช้งาน Gemma แล้ว คุณยอมรับใบอนุญาตใน Hugging Face ได้โดยคลิกปุ่ม "ยอมรับและเข้าถึงที่เก็บ" ในหน้าโมเดลที่ http://huggingface.co/google/gemma-3-270m-it
หลังจากยอมรับใบอนุญาตแล้ว คุณจะต้องมีโทเค็น Hugging Face ที่ถูกต้องเพื่อเข้าถึงโมเดล หากคุณกำลังเรียกใช้ภายใน Google Colab คุณสามารถใช้โทเค็น Hugging Face ได้อย่างปลอดภัยโดยใช้ความลับของ Colab หรือจะตั้งค่าโทเค็นโดยตรงในloginเมธอดก็ได้ ตรวจสอบว่าโทเค็นมีสิทธิ์เข้าถึงแบบเขียนด้วย เนื่องจากคุณจะพุชโมเดลไปยัง Hub ในระหว่างการฝึก
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
คุณสามารถเก็บผลลัพธ์ไว้ในเครื่องเสมือนในเครื่องของ Colab ได้ อย่างไรก็ตาม เราขอแนะนำให้บันทึกผลลัพธ์ระดับกลางไว้ใน Google ไดรฟ์ ซึ่งจะช่วยให้ผลลัพธ์การฝึกของคุณปลอดภัย และช่วยให้คุณเปรียบเทียบและเลือกโมเดลที่ดีที่สุดได้อย่างง่ายดาย
from google.colab import drive
drive.mount('/content/drive')
เลือกรุ่นพื้นฐานเพื่อปรับแต่ง ปรับไดเรกทอรีจุดตรวจ และอัตราการเรียนรู้
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
สร้างและเตรียมชุดข้อมูลการปรับแต่ง
ชุดข้อมูล bebechien/MobileGameNPC มีตัวอย่างการสนทนาเล็กๆ ระหว่างผู้เล่นกับ NPC เอเลี่ยน 2 ตัว (ชาวดาวอังคารและชาวดาวศุกร์) ซึ่งแต่ละตัวมีสไตล์การพูดที่เป็นเอกลักษณ์ ตัวอย่างเช่น NPC ชาวดาวอังคารจะพูดด้วยสำเนียงที่แทนที่เสียง "s" ด้วย "z" ใช้ "da" แทน "the" ใช้ "diz" แทน "this" และมีเสียงคลิกเป็นครั้งคราว เช่น *k'tak*
ชุดข้อมูลนี้แสดงให้เห็นหลักการสำคัญในการปรับแต่ง นั่นคือขนาดชุดข้อมูลที่จำเป็นจะขึ้นอยู่กับเอาต์พุตที่ต้องการ
- หากต้องการสอนรูปแบบภาษาที่โมเดลรู้จักอยู่แล้ว เช่น สำเนียงของชาวอังคาร ชุดข้อมูลขนาดเล็กที่มีตัวอย่างเพียง 10-20 รายการก็เพียงพอแล้ว
- อย่างไรก็ตาม หากต้องการสอนโมเดลให้เข้าใจภาษาต่างดาวใหม่ทั้งหมดหรือภาษาผสม จะต้องใช้ชุดข้อมูลที่ใหญ่ขึ้นอย่างมาก
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
ปรับแต่ง Gemma โดยใช้ TRL และ SFTTrainer
ตอนนี้คุณพร้อมที่จะปรับแต่งโมเดลแล้ว SFTTrainer ของ TRL จาก Hugging Face ช่วยให้การดูแลการปรับแต่ง LLM แบบเปิดเป็นเรื่องง่าย SFTTrainer เป็นคลาสย่อยของ Trainer จากไลบรารี transformers และรองรับฟีเจอร์เดียวกันทั้งหมด
โค้ดต่อไปนี้จะโหลดโมเดลและโทเค็นไนเซอร์ Gemma จาก Hugging Face
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
ก่อนการปรับแต่ง
เอาต์พุตด้านล่างแสดงให้เห็นว่าความสามารถที่พร้อมใช้งานอาจไม่ดีพอสำหรับกรณีการใช้งานนี้
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
ตัวอย่างด้านบนจะตรวจสอบฟังก์ชันหลักของโมเดลในการสร้างบทสนทนาในเกม ส่วนตัวอย่างถัดไปออกแบบมาเพื่อทดสอบความสอดคล้องของตัวละคร เราท้าทายโมเดลด้วยพรอมต์ที่ไม่เกี่ยวข้อง เช่น Sorry, you are a game NPC. ซึ่งอยู่นอกฐานความรู้ของตัวละคร
เป้าหมายคือการดูว่าโมเดลจะคงลักษณะตัวละครไว้ได้หรือไม่แทนที่จะตอบคำถามที่ไม่อยู่ในบริบท ซึ่งจะเป็นเกณฑ์พื้นฐานในการประเมินว่ากระบวนการปรับแต่งได้สร้างลักษณะตัวตนที่ต้องการได้อย่างมีประสิทธิภาพเพียงใด
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
และแม้ว่าเราจะใช้การออกแบบพรอมต์เพื่อกำหนดโทนของโมเดลได้ แต่ผลลัพธ์ก็คาดเดาไม่ได้และอาจไม่สอดคล้องกับลักษณะตัวตนที่เราต้องการเสมอไป
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
การฝึกอบรม
ก่อนเริ่มการฝึก คุณต้องกำหนดไฮเปอร์พารามิเตอร์ที่ต้องการใช้ในอินสแตนซ์ SFTConfig
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
ตอนนี้คุณมีองค์ประกอบทุกอย่างที่จำเป็นในการสร้าง SFTTrainer เพื่อเริ่มฝึกโมเดลแล้ว
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
เริ่มการฝึกโดยเรียกใช้เมธอด train()
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
หากต้องการพล็อตการสูญเสียการฝึกและชุดข้อมูลที่ใช้ตรวจสอบความถูกต้อง คุณมักจะดึงค่าเหล่านี้จากออบเจ็กต์ TrainerState หรือบันทึกที่สร้างขึ้นระหว่างการฝึก
จากนั้นคุณจะใช้ไลบรารี เช่น Matplotlib เพื่อแสดงค่าเหล่านี้ในขั้นตอนการฝึกหรือ Epoch ได้ แกน X จะแสดงขั้นตอนการฝึกหรือ Epoch และแกน Y จะแสดงค่าการสูญเสียที่สอดคล้องกัน
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
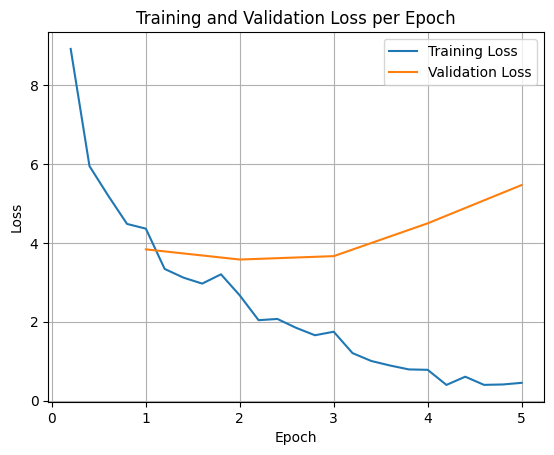
ภาพนี้ช่วยในการตรวจสอบกระบวนการฝึกและตัดสินใจอย่างมีข้อมูลเกี่ยวกับการปรับแต่งไฮเปอร์พารามิเตอร์หรือการหยุดก่อนเวลา
การสูญเสียการฝึกจะวัดข้อผิดพลาดในข้อมูลที่ใช้ฝึกโมเดล ส่วนการสูญเสียการตรวจสอบจะวัดข้อผิดพลาดในชุดข้อมูลแยกต่างหากที่โมเดลไม่เคยเห็นมาก่อน การตรวจสอบทั้ง 2 อย่างจะช่วยตรวจหา Overfitting (เมื่อโมเดลทํางานได้ดีกับข้อมูลการฝึก แต่ทํางานได้ไม่ดีกับข้อมูลที่ไม่เคยเห็น)
- การสูญเสียการตรวจสอบ >> การสูญเสียการฝึก: Overfitting
- การสูญเสียการตรวจสอบ > การสูญเสียการฝึก: การปรับมากเกินไปบางส่วน
- การสูญเสียการตรวจสอบ < การสูญเสียการฝึก: การปรับให้พอดีน้อยเกินไป
- การสูญเสียการตรวจสอบ << การสูญเสียการฝึก: การปรับให้พอดีน้อยเกินไป
ทดสอบการอนุมานของโมเดล
หลังจากฝึกแล้ว คุณจะต้องประเมินและทดสอบโมเดล คุณโหลดตัวอย่างต่างๆ จากชุดข้อมูลทดสอบและประเมินโมเดลในตัวอย่างเหล่านั้นได้
สำหรับกรณีการใช้งานนี้ โมเดลที่ดีที่สุดขึ้นอยู่กับความชอบ ที่น่าสนใจคือ สิ่งที่เรามักเรียกว่า "Overfitting" อาจมีประโยชน์มากสำหรับ NPC ในเกม ซึ่งจะบังคับให้โมเดลลืมข้อมูลทั่วไปและมุ่งเน้นไปที่ลักษณะเฉพาะและคุณลักษณะที่ได้รับการฝึกมาแทน เพื่อให้มั่นใจว่าโมเดลจะคงลักษณะตัวละครได้อย่างสม่ำเสมอ
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
มาโหลดคำถามทั้งหมดจากชุดข้อมูลทดสอบและสร้างเอาต์พุตกัน
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
หากลองใช้พรอมต์แบบทั่วไปดั้งเดิม คุณจะเห็นว่าโมเดลยังคงพยายามตอบในรูปแบบที่ได้รับการฝึกมา ในตัวอย่างนี้ การปรับมากเกินไปและการลืมแบบหายนะเป็นประโยชน์ต่อ NPC ในเกม เนื่องจาก NPC จะเริ่มลืมความรู้ทั่วไปซึ่งอาจไม่เกี่ยวข้อง ซึ่งรวมถึงการปรับแต่งแบบเต็มประเภทอื่นๆ ด้วย โดยมีเป้าหมายเพื่อจำกัดเอาต์พุตให้อยู่ในรูปแบบข้อมูลที่เฉพาะเจาะจง
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
สรุปและขั้นตอนถัดไป
บทแนะนำนี้ครอบคลุมวิธีปรับแต่งโมเดลแบบเต็มโดยใช้ TRL ดูเอกสารต่อไปนี้