
Bu kılavuzda, Hugging Face'teki Gemma modellerini Safetensors biçiminden (.safetensors) MediaPipe Görev dosyası biçimine (.task) dönüştürmeyle ilgili talimatlar verilmektedir. Bu dönüştürme, MediaPipe LLM Inference API ve LiteRT çalışma zamanı kullanılarak Android ve iOS'te cihaz üzerinde çıkarım için önceden eğitilmiş veya ince ayar yapılmış Gemma modellerinin dağıtılması açısından önemlidir.
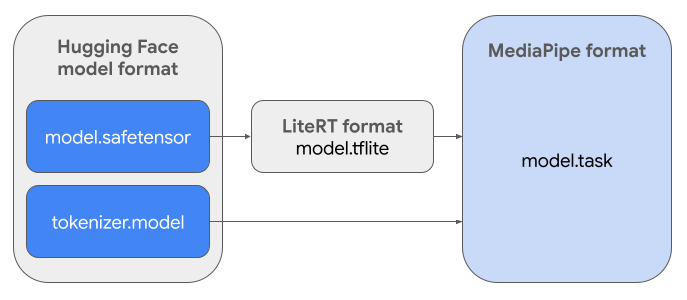
Gerekli görev paketini (.task) oluşturmak için LiteRT Torch'u kullanacaksınız. Bu araç, PyTorch modellerini MediaPipe LLM Inference API ile uyumlu ve mobil uygulamalarda CPU arka uçlarında çalışmaya uygun çok imzalı LiteRT (.tflite) modellerine aktarır.
Son .task dosyası, MediaPipe'ın gerektirdiği bağımsız bir pakettir. Bu paket, LiteRT modelini, belirteç oluşturucu modelini ve temel meta verileri içerir. Bu paket, uçtan uca çıkarım sağlamak için belirteçleştiricinin (metin istemlerini model için belirteç yerleştirmelerine dönüştürür) LiteRT modeliyle birlikte paketlenmesi gerektiğinden zorunludur.
Sürecin adım adım dökümünü aşağıda bulabilirsiniz:
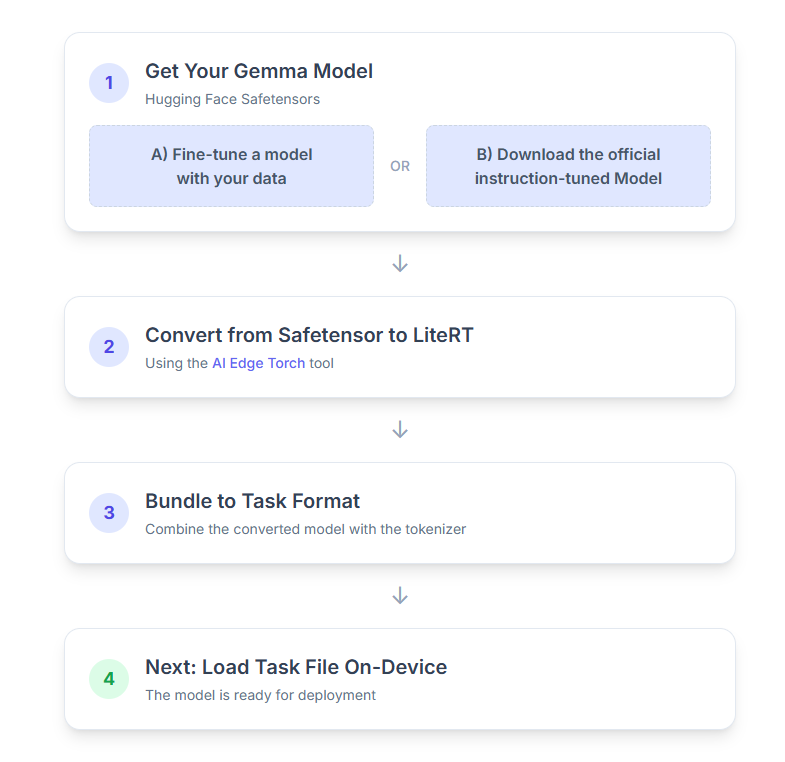
1. Gemma modelinizi edinme
Başlamak için iki seçeneğiniz vardır.
A seçeneği. Mevcut bir ince ayarlı modeli kullanma
İnce ayar yapılmış bir Gemma modeliniz varsa doğrudan sonraki adıma geçebilirsiniz.
B seçeneği. Resmi talimatlara göre ayarlanmış modeli indirin
Bir modele ihtiyacınız varsa Hugging Face Hub'dan talimatlara göre ayarlanmış bir Gemma indirebilirsiniz.
Gerekli araçları kurun:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
Modeli indirme:
Hugging Face Hub'daki modeller, genellikle <organization_or_username>/<model_name> biçiminde bir model kimliğiyle tanımlanır. Örneğin, resmi Google Gemma 3 270M talimat için ayarlanmış modeli indirmek üzere şunu kullanın:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. Modeli LiteRT'ye dönüştürme ve nicemleme
Python sanal ortamı oluşturun ve LiteRT Torch paketinin en son kararlı sürümünü yükleyin:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
Safetensor'u LiteRT modeline dönüştürmek için aşağıdaki komut dosyasını kullanın.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
Bu işlemin zaman alıcı olduğunu ve bilgisayarınızın işlem hızına bağlı olduğunu unutmayın. Örnek olarak, 2025 model 8 çekirdekli bir CPU'da 270 milyon parametreli bir modelin eğitilmesi 5-10 dakikadan uzun sürerken 1 milyar parametreli bir modelin eğitilmesi yaklaşık 10-30 dakika sürebilir.
Son çıktı olan LiteRT modeli, belirttiğiniz OUTPUT_DIR_PATH konumuna kaydedilir.
Aşağıdaki değerleri hedef cihazınızın bellek ve performans kısıtlamalarına göre ayarlayın.
kv_cache_max_len: Modelin çalışma belleğinin (KV önbelleği) toplam ayrılan boyutunu tanımlar. Bu kapasite kesin bir sınırdır ve istem jetonlarının (ön doldurma) ve daha sonra oluşturulan tüm jetonların (kod çözme) toplamını depolamak için yeterli olmalıdır.prefill_seq_len: Önceden doldurma için giriş isteminin jeton sayısını belirtir. Giriş istemi, önceden doldurma parçalama kullanılarak işlenirken tüm sıra (ör. 50.000 jeton) tek seferde hesaplanmaz. Bunun yerine, bellek hatasını önlemek için yönetilebilir segmentlere (ör. 2.048 jetonluk parçalar) bölünür ve sırayla önbelleğe yüklenir.quantize: Seçilen nicemleme şemaları için dize. Aşağıda, Gemma 3 için kullanılabilen nicemleme tariflerinin listesi verilmiştir.none: Kuantizasyon yokfp16: Tüm işlemler için FP16 ağırlıkları, FP32 etkinleştirmeleri ve kayan nokta hesaplamasıdynamic_int8: FP32 etkinleştirmeleri, INT8 ağırlıkları ve tam sayı hesaplamaweight_only_int8: FP32 etkinleştirmeleri, INT8 ağırlıkları ve kayan nokta hesaplaması
3. LiteRT ve belirteçleştiriciden Görev Paketi oluşturma
Python sanal ortamı oluşturun ve mediapipe Python paketini yükleyin:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
Modeli paketlemek için genai.bundler kitaplığını kullanın:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
bundler.create_bundle işlevi, modeli çalıştırmak için gereken tüm bilgileri içeren bir .task dosyası oluşturur.
4. Android'de MediaPipe ile çıkarım
Görevi temel yapılandırma seçenekleriyle başlatın:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
Metin yanıtı oluşturmak için generateResponse() yöntemini kullanın.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
Yanıtı yayınlamak için generateResponseAsync() yöntemini kullanın.
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
Daha fazla bilgi için Android için LLM çıkarım kılavuzuna bakın.
Sonraki adımlar
Gemma modelleriyle daha fazlasını oluşturun ve keşfedin: