
|
|
|
|
|
 Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin
|
Bu kılavuzda, Hugging Face Transformers ve TRL kullanarak Gemma'yı bir mobil oyun NPC veri kümesinde nasıl ince ayarlayacağınız açıklanmaktadır. Öğrenecekleriniz:
- Geliştirme ortamını kurma
- İnce ayar veri kümesini hazırlama
- TRL ve SFTTrainer kullanarak Gemma'da tam model ince ayarı yapma
- Model çıkarımı ve vibe check'leri test etme
Geliştirme ortamını kurma
İlk adım, farklı RLHF ve hizalama teknikleri de dahil olmak üzere açık modeli ince ayarlamak için TRL ve veri kümeleri gibi Hugging Face kitaplıklarını yüklemektir.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
Not: Ampere mimarisine (ör. NVIDIA L4) veya daha yeni bir mimariye sahip bir GPU kullanıyorsanız Flash dikkat mekanizmasını kullanabilirsiniz. Flash Attention, hesaplamaları önemli ölçüde hızlandıran ve bellek kullanımını sıra uzunluğunda kareselden doğrusal hale getiren bir yöntemdir. Bu sayede eğitim 3 kata kadar hızlandırılabilir. Daha fazla bilgiyi FlashAttention sayfasında bulabilirsiniz.
Eğitime başlamadan önce Gemma'nın kullanım şartlarını kabul ettiğinizden emin olmanız gerekir. Lisansı Hugging Face'te kabul etmek için http://huggingface.co/google/gemma-3-270m-it adresindeki model sayfasında Kabul et ve depoya eriş düğmesini tıklayın.
Lisansı kabul ettikten sonra modele erişmek için geçerli bir Hugging Face jetonuna ihtiyacınız vardır. Google Colab'de çalışıyorsanız Colab sırlarını kullanarak Hugging Face jetonunuzu güvenli bir şekilde kullanabilirsiniz. Aksi takdirde, jetonu doğrudan login yönteminde ayarlayabilirsiniz. Eğitim sırasında modelinizi Hub'a aktaracağınız için jetonunuzun yazma erişimine de sahip olduğundan emin olun.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
Sonuçları Colab'in yerel sanal makinesinde saklayabilirsiniz. Ancak ara sonuçlarınızı Google Drive'ınıza kaydetmenizi önemle tavsiye ederiz. Bu sayede eğitim sonuçlarınız güvende kalır ve en iyi modeli kolayca karşılaştırıp seçebilirsiniz.
from google.colab import drive
drive.mount('/content/drive')
İnce ayar yapılacak temel modeli seçin, kontrol noktası dizinini ve öğrenme hızını ayarlayın.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
İnce ayar veri kümesini oluşturma ve hazırlama
bebechien/MobileGameNPC veri kümesi, her biri benzersiz bir konuşma tarzına sahip olan bir oyuncu ile iki Alien NPC (bir Marslı ve bir Venüslü) arasındaki küçük bir örnek sohbet sunar. Örneğin, Marslı NPC, "s" seslerini "z" ile değiştiren, "the" yerine "da", "this" yerine "diz" kelimesini kullanan ve ara sıra *k'tak* gibi tıklamalar içeren bir aksanla konuşuyor.
Bu veri kümesi, ince ayar için önemli bir ilkeyi gösterir: Gerekli veri kümesi boyutu, istenen çıkışa bağlıdır.
- Modele, bildiği bir dilin stilistik varyasyonunu (ör. Marslı aksanı) öğretmek için 10-20 örnek içeren küçük bir veri kümesi yeterli olabilir.
- Ancak modele tamamen yeni veya karışık bir uzaylı dili öğretmek için çok daha büyük bir veri kümesi gerekir.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
TRL ve SFTTrainer kullanarak Gemma'yı ince ayarlama
Artık modelinizde ince ayar yapmaya hazırsınız. Hugging Face TRL SFTTrainer, açık LLM'lerin ince ayarını denetlemeyi kolaylaştırır. SFTTrainer, transformers kitaplığındaki Trainer öğesinin bir alt sınıfıdır ve aynı özelliklerin tümünü destekler.
Aşağıdaki kod, Gemma modelini ve tokenizer'ı Hugging Face'den yükler.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
İnce ayardan önce
Aşağıdaki çıktı, kullanıma hazır özelliklerin bu kullanım alanı için yeterli olmayabileceğini gösteriyor.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
Yukarıdaki örnekte, modelin oyun içi diyalog oluşturma gibi birincil işlevi kontrol ediliyor. Bir sonraki örnek ise karakter tutarlılığını test etmek için tasarlanmıştır. Modele konu dışı bir istemle meydan okuyoruz. Örneğin, Sorry, you are a game NPC. karakterin bilgi bankasının dışında kalır.
Amaç, modelin bağlam dışı soruyu yanıtlamak yerine karakterine uygun davranıp davranmadığını görmektir. Bu, ince ayar sürecinin istenen karakteri ne kadar etkili bir şekilde yerleştirdiğini değerlendirmek için bir referans noktası olarak kullanılır.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
Tonunu yönlendirmek için istem mühendisliğini kullanabiliriz ancak sonuçlar tahmin edilemez olabilir ve her zaman istediğimiz karakterle uyumlu olmayabilir.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
Eğitim
Eğitiminize başlamadan önce, SFTConfig örneğinde kullanmak istediğiniz hiperparametreleri tanımlamanız gerekir.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
Artık modelinizin eğitimine başlamak için SFTTrainer oluşturmanız gereken tüm yapı taşlarına sahipsiniz.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
train() yöntemini çağırarak eğitime başlayın.
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
Eğitim ve doğrulama kayıplarını çizmek için genellikle bu değerleri TrainerState nesnesinden veya eğitim sırasında oluşturulan günlüklerden çıkarırsınız.
Ardından, Matplotlib gibi kitaplıklar bu değerleri eğitim adımları veya dönemler boyunca görselleştirmek için kullanılabilir. X ekseni eğitim adımlarını veya dönemlerini, Y ekseni ise ilgili kayıp değerlerini temsil eder.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
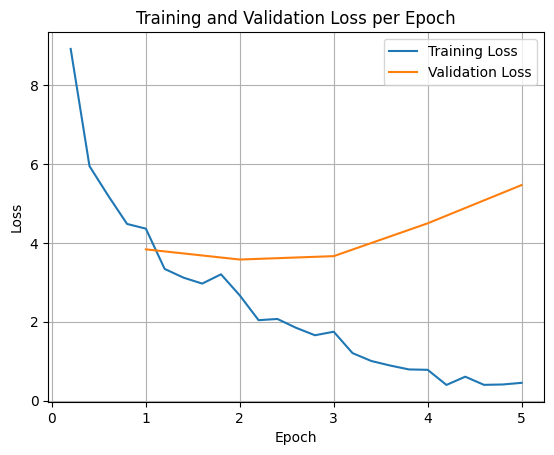
Bu görselleştirme, eğitim sürecinin izlenmesine ve hiperparametre ayarlama veya erken durdurma hakkında bilinçli kararlar verilmesine yardımcı olur.
Eğitim kaybı, modelin eğitildiği verilerdeki hatayı ölçerken doğrulama kaybı, modelin daha önce görmediği ayrı bir veri kümesindeki hatayı ölçer. Her ikisinin de izlenmesi, aşırı uyumu (modelin eğitim verilerinde iyi performans gösterip görülmemiş verilerde kötü performans göstermesi) tespit etmeye yardımcı olur.
- Doğrulama kaybı >> eğitim kaybı: aşırı uyum
- doğrulama kaybı > eğitim kaybı: biraz fazla uyum
- doğrulama kaybı < eğitim kaybı: biraz eksik uyum
- doğrulama kaybı << eğitim kaybı: eksik uyum (underfitting)
Model Çıkarımını Test Etme
Eğitim tamamlandıktan sonra modelinizi değerlendirip test etmeniz gerekir. Test veri kümesinden farklı örnekler yükleyebilir ve modeli bu örnekler üzerinde değerlendirebilirsiniz.
Bu kullanım alanında en iyi model, tercihe bağlıdır. İlginç bir şekilde, normalde "aşırı uyum" olarak adlandırdığımız şey, bir oyun NPC'si için çok faydalı olabilir. Bu sayede model, genel bilgileri unutmaya zorlanır ve bunun yerine eğitildiği belirli kişiliğe ve özelliklere odaklanarak karakterini tutarlı bir şekilde korur.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Test veri kümesindeki tüm soruları yükleyip çıkış oluşturalım.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
Orijinal genel amaçlı istemimizi denerseniz modelin, eğitildiği tarzda yanıt vermeye çalıştığını görebilirsiniz. Bu örnekte, aşırı uyum ve yıkıcı unutma, oyun NPC'si için aslında faydalıdır. Çünkü bu durumda, geçerli olmayabilecek genel bilgileri unutmaya başlar. Bu durum, amacın çıktıyı belirli veri biçimleriyle sınırlamak olduğu diğer tam ince ayar türleri için de geçerlidir.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
Özet ve sonraki adımlar
Bu eğiticide, TRL kullanarak tam modelde ince ayar yapma konusu ele alınmıştır. Ardından aşağıdaki dokümanlara göz atın: