
|
|
|
|
|
 Lihat sumber di GitHub Lihat sumber di GitHub
|
Panduan ini akan memandu Anda cara menyempurnakan Gemma pada set data NPC game seluler menggunakan Transformers dan TRL Hugging Face. Anda akan mempelajari:
- Menyiapkan lingkungan pengembangan
- Menyiapkan set data fine-tuning
- Penyesuaian model penuh Gemma menggunakan TRL dan SFTTrainer
- Menguji Inferensi Model dan pemeriksaan suasana
Menyiapkan lingkungan pengembangan
Langkah pertama adalah menginstal Hugging Face Libraries, termasuk TRL, dan set data untuk menyempurnakan model terbuka, termasuk berbagai teknik RLHF dan penyelarasan.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
Catatan: Jika Anda menggunakan GPU dengan arsitektur Ampere (seperti NVIDIA L4) atau yang lebih baru, Anda dapat menggunakan Flash attention. Flash Attention adalah metode yang secara signifikan mempercepat komputasi dan mengurangi penggunaan memori dari kuadratik menjadi linear dalam panjang urutan, sehingga mempercepat pelatihan hingga 3x. Pelajari lebih lanjut di FlashAttention.
Sebelum dapat memulai pelatihan, Anda harus memastikan bahwa Anda telah menyetujui persyaratan penggunaan Gemma. Anda dapat menyetujui lisensi di Hugging Face dengan mengklik tombol Setuju dan akses repositori di halaman model di: http://huggingface.co/google/gemma-3-270m-it
Setelah menyetujui lisensi, Anda memerlukan Token Hugging Face yang valid untuk mengakses model. Jika Anda menjalankan di dalam Google Colab, Anda dapat menggunakan Token Hugging Face Anda secara aman menggunakan rahasia Colab. Jika tidak, Anda dapat menetapkan token secara langsung dalam metode login. Pastikan token Anda juga memiliki akses tulis, saat Anda mengirimkan model ke Hub selama pelatihan.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
Anda dapat menyimpan hasilnya di virtual machine lokal Colab. Namun, sebaiknya simpan hasil sementara Anda ke Google Drive. Hal ini memastikan hasil pelatihan Anda aman dan memungkinkan Anda membandingkan serta memilih model terbaik dengan mudah.
from google.colab import drive
drive.mount('/content/drive')
Pilih model dasar yang akan di-fine-tune, sesuaikan direktori titik pemeriksaan dan kecepatan pemelajaran.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
Membuat dan menyiapkan set data penyesuaian
Set data bebechien/MobileGameNPC menyediakan contoh kecil percakapan antara pemain dan dua NPC Alien (Mars dan Venus), yang masing-masing memiliki gaya bicara yang unik. Misalnya, NPC Martian berbicara dengan aksen yang mengganti bunyi 's' dengan 'z', menggunakan 'da' untuk 'the', 'diz' untuk 'this', dan terkadang menyertakan bunyi klik seperti *k'tak*.
Set data ini menunjukkan prinsip utama untuk penyesuaian: ukuran set data yang diperlukan bergantung pada output yang diinginkan.
- Untuk mengajari model variasi gaya bahasa yang sudah diketahuinya, seperti aksen Mars, set data kecil dengan 10 hingga 20 contoh saja sudah cukup.
- Namun, untuk mengajari model bahasa alien yang benar-benar baru atau campuran, diperlukan set data yang jauh lebih besar.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
Menyesuaikan Gemma menggunakan TRL dan SFTTrainer
Sekarang Anda siap menyetel model. SFTTrainer Hugging Face TRL memudahkan pengawasan penyesuaian LLM terbuka. SFTTrainer adalah subclass Trainer dari library transformers dan mendukung semua fitur yang sama,
Kode berikut memuat model dan tokenizer Gemma dari Hugging Face.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
Sebelum penyesuaian
Output di bawah menunjukkan bahwa kemampuan bawaan mungkin tidak cukup baik untuk kasus penggunaan ini.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
Contoh di atas memeriksa fungsi utama model dalam membuat dialog dalam game, contoh berikutnya dirancang untuk menguji konsistensi karakter. Kami menguji model dengan perintah di luar topik. Misalnya, Sorry, you are a game NPC., yang berada di luar pusat informasi karakter.
Tujuannya adalah untuk melihat apakah model dapat tetap sesuai karakter, bukan menjawab pertanyaan di luar konteks. Hal ini akan berfungsi sebagai dasar pengukuran untuk mengevaluasi seberapa efektif proses penyesuaian telah menanamkan persona yang diinginkan.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
Meskipun kita dapat menggunakan rekayasa perintah untuk mengarahkan nadanya, hasilnya bisa tidak dapat diprediksi dan mungkin tidak selalu sesuai dengan persona yang kita inginkan.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
Pelatihan
Sebelum dapat memulai pelatihan, Anda perlu menentukan hyperparameter yang ingin digunakan dalam instance SFTConfig.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
Sekarang Anda memiliki setiap elemen penyusun yang diperlukan untuk membuat SFTTrainer guna memulai pelatihan model.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
Mulai pelatihan dengan memanggil metode train().
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
Untuk memetakan kerugian pelatihan dan validasi, Anda biasanya akan mengekstrak nilai ini dari objek TrainerState atau log yang dihasilkan selama pelatihan.
Library seperti Matplotlib kemudian dapat digunakan untuk memvisualisasikan nilai ini selama langkah atau epoch pelatihan. Sumbu x akan merepresentasikan langkah-langkah atau iterasi pelatihan, dan sumbu y akan merepresentasikan nilai kerugian yang sesuai.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
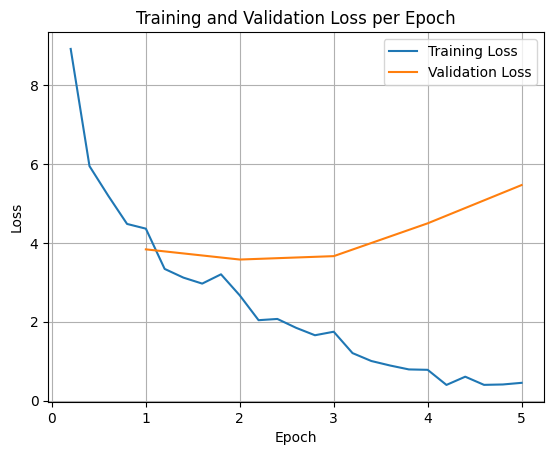
Visualisasi ini membantu memantau proses pelatihan dan membuat keputusan yang tepat tentang penyesuaian hyperparameter atau penghentian awal.
Kerugian pelatihan mengukur error pada data yang digunakan untuk melatih model, sedangkan kerugian validasi mengukur error pada set data terpisah yang belum pernah dilihat model sebelumnya. Memantau keduanya membantu mendeteksi overfitting (saat model berperforma baik pada data pelatihan, tetapi buruk pada data yang belum pernah dilihat).
- kerugian validasi >> kerugian pelatihan: overfitting
- kerugian validasi > kerugian pelatihan: beberapa overfitting
- kerugian validasi < kerugian pelatihan: beberapa kekurangan yang tidak sesuai
- kerugian validasi << kerugian pelatihan: kurang sesuai (underfitting)
Inferensi Model Pengujian
Setelah pelatihan selesai, Anda harus mengevaluasi dan menguji model. Anda dapat memuat berbagai sampel dari set data pengujian dan mengevaluasi model pada sampel tersebut.
Untuk kasus penggunaan khusus ini, model terbaik adalah masalah preferensi. Menariknya, apa yang biasanya kita sebut 'overfitting' dapat sangat berguna untuk NPC game. Hal ini memaksa model untuk melupakan informasi umum dan berfokus pada persona dan karakteristik spesifik yang digunakan untuk melatihnya, sehingga memastikan model tetap konsisten dalam karakternya.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Mari kita muat semua pertanyaan dari set data pengujian dan buat output.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
Jika Anda mencoba perintah generalis asli kami, Anda dapat melihat bahwa model masih mencoba menjawab dengan gaya yang dilatih. Dalam contoh ini, overfitting dan catastrophic forgetting sebenarnya bermanfaat bagi NPC game karena NPC akan mulai melupakan pengetahuan umum yang mungkin tidak berlaku. Hal ini juga berlaku untuk jenis penyesuaian penuh lainnya yang tujuannya adalah membatasi output ke format data tertentu.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
Ringkasan dan langkah selanjutnya
Tutorial ini membahas cara menyempurnakan model secara penuh menggunakan TRL. Selanjutnya, lihat dokumen berikut:
- Pelajari cara menyesuaikan Gemma untuk tugas teks menggunakan Hugging Face Transformers.
- Pelajari cara menyesuaikan Gemma untuk tugas visi menggunakan Hugging Face Transformers.
- Pelajari cara men-deploy ke Cloud Run