
DiffusionGemma को समझने के लिए, स्टैंडर्ड लैंग्वेज मॉडल की मुख्य सीमाओं और टेक्स्ट-आधारित डिफ़्यूज़न में अंतर को समझना ज़रूरी है.
ऑटोरिग्रेसिव मॉडल से जुड़ी समस्या
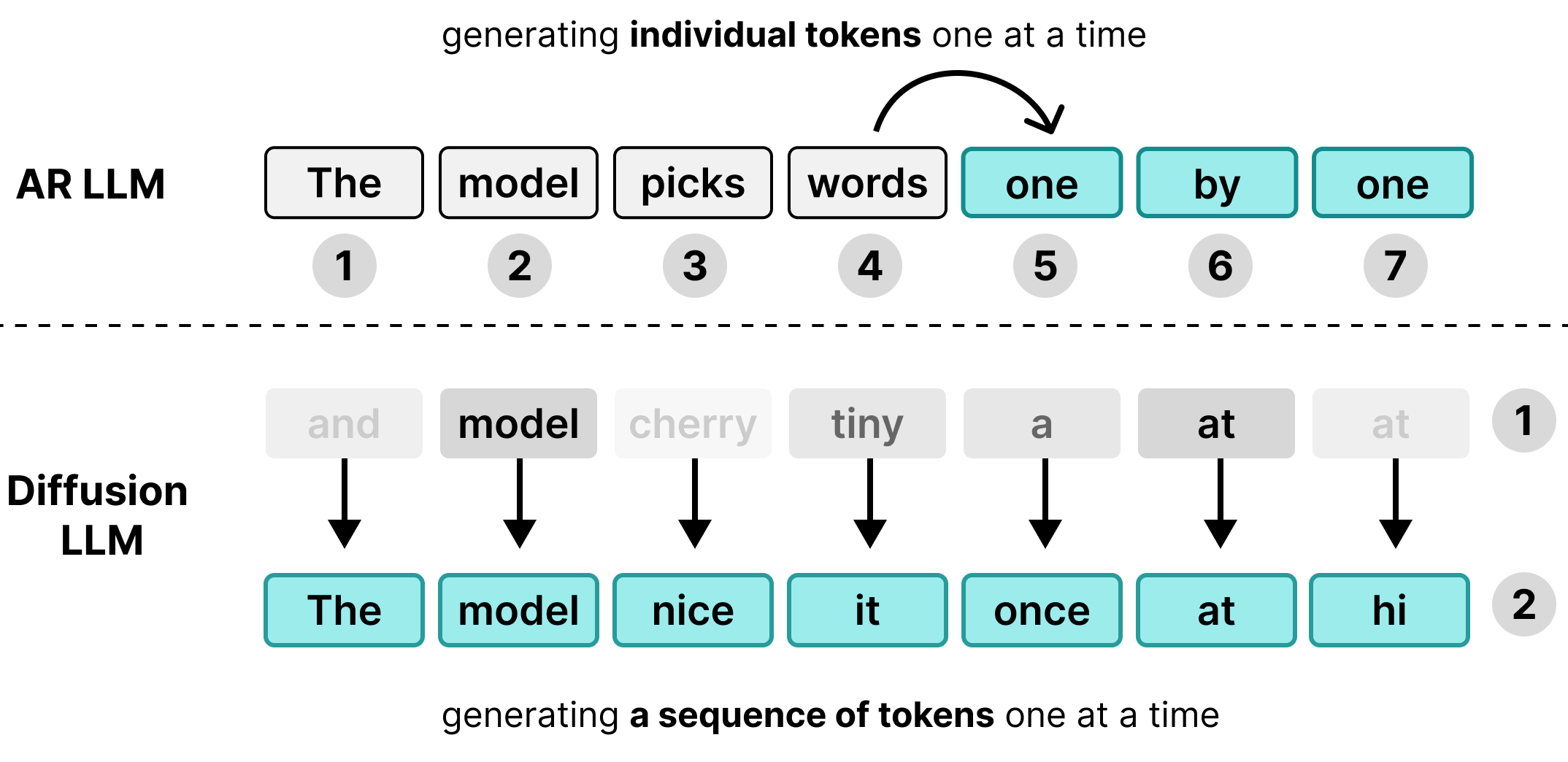
कई लार्ज लैंग्वेज मॉडल (एलएलएम) ऑटोरिग्रेसिव होते हैं. इसका मतलब है कि वे टेक्स्ट एक बार में सिर्फ़ एक टोकन जनरेट करते हैं. बैचिंग की मदद से, एक साथ कई उपयोगकर्ताओं को सेवा देने के लिए यह तरीका बेहतर है. हालांकि, इससे अलग-अलग उपयोगकर्ताओं के लिए इंतज़ार के समय का बॉटलनेक बन जाता है.
डिकोडिंग के दौरान, स्टैंडर्ड ट्रांसफ़ॉर्मर मॉडल, कंप्यूट-बाउंड के बजाय मेमोरी-बाउंड होते हैं. जनरेट करने में लगने वाला ज़्यादातर समय, मॉडल के वेट को हार्डवेयर मेमोरी से प्रोसेसिंग यूनिट में लोड करने में लगता है. इसके बजाय, असल में गणित के हिसाब से कैलकुलेशन करने में नहीं. वेट को हर चरण में सिर्फ़ एक बार लोड करना होता है. भले ही, बैच का साइज़ कुछ भी हो. इसलिए, एक टोकन जनरेट करने में, एक उपयोगकर्ता के लिए उतना ही समय लगता है जितना 256 उपयोगकर्ताओं के ग्रुप के लिए.
इसलिए, किसी एक उपयोगकर्ता को इंतज़ार के समय में कोई फ़ायदा नहीं मिलता. मेमोरी ट्रांसफ़र का इंतज़ार करते समय, हार्डवेयर की कंप्यूटेशनल क्षमता खाली रहती है.
DiffusionGemma , किसी एक उपयोगकर्ता के लिए, कंप्यूट करने में लगने वाले इस खाली समय का इस्तेमाल करता है. यह 256 अलग-अलग उपयोगकर्ताओं के लिए एक टोकन जनरेट करने के बजाय, किसी एक उपयोगकर्ता के लिए 256 टोकन एक साथ जनरेट करता है.
मॉडल, 256 रैंडम टोकन का एक खाली सीक्वेंस शुरू करता है. इसे कैनवसकहा जाता है. साथ ही, यह पूरे कैनवस का एक साथ आकलन और उसे बेहतर बनाता है. इससे मॉडल, मेमोरी-बाउंड से कंप्यूट-बाउंड में बदल जाता है. इससे कंप्यूटेशनल पावर बढ़ने पर, प्रोसेसिंग की स्पीड को बेहतर तरीके से बढ़ाया जा सकता है.
| आसपेक्ट | टेक्स्ट ऑटोरिग्रेसन | टेक्स्ट डिफ़्यूज़न |
|---|---|---|
| टोकन जनरेट करना | एक बार में एक टोकन | एक बार में टोकन का पूरा कैनवस |
| कदम | हर टोकन के लिए एक चरण | कई टोकन के लिए एक चरण |
| जनरेट करने का क्रम | बाएं-से-दाएं | सभी पोज़िशन एक साथ |
| शुरुआती पॉइंट | खाली सीक्वेंस | शब्दावली से लिए गए रैंडम टोकन |
| गड़बड़ी ठीक करना | स्थिर; पिछले टोकन में बदलाव नहीं किया जा सकता | डाइनैमिक; कैनवस की किसी भी पोज़िशन में बदलाव किया जा सकता है |
| हार्डवेयर की सीमा | मेमोरी-बाउंड | कंप्यूट-बाउंड |
| थ्रूपुट फ़ोकस | एक साथ कई उपयोगकर्ताओं के लिए हाई थ्रूपुट | एक उपयोगकर्ता के लिए इंतज़ार का समय बहुत कम रखना |
टेक्स्ट डिफ़्यूज़न के काम करने का तरीका समझना
इमेज जनरेट करने के लिए, डिफ़्यूज़न मॉडल 100% रैंडम गॉसियन नॉइज़ से शुरू होते हैं. इसके बाद, टेक्स्ट प्रॉम्प्ट की मदद से, कई चरणों में इसे धीरे-धीरे हटाया जाता है (डीनॉइज़िंग). इस लॉजिक को टेक्स्ट में बदलना ज़्यादा मुश्किल है, क्योंकि टेक्स्ट टोकन अलग-अलग इकाइयां होती हैं. वहीं, पिक्सल वैल्यू लगातार बदलती रहती हैं.
DiffusionGemma, टेक्स्ट-आधारित डिफ़्यूज़न को खास तरीकों की मदद से हासिल करता है:
1. मास्क किया गया डिफ़्यूज़न
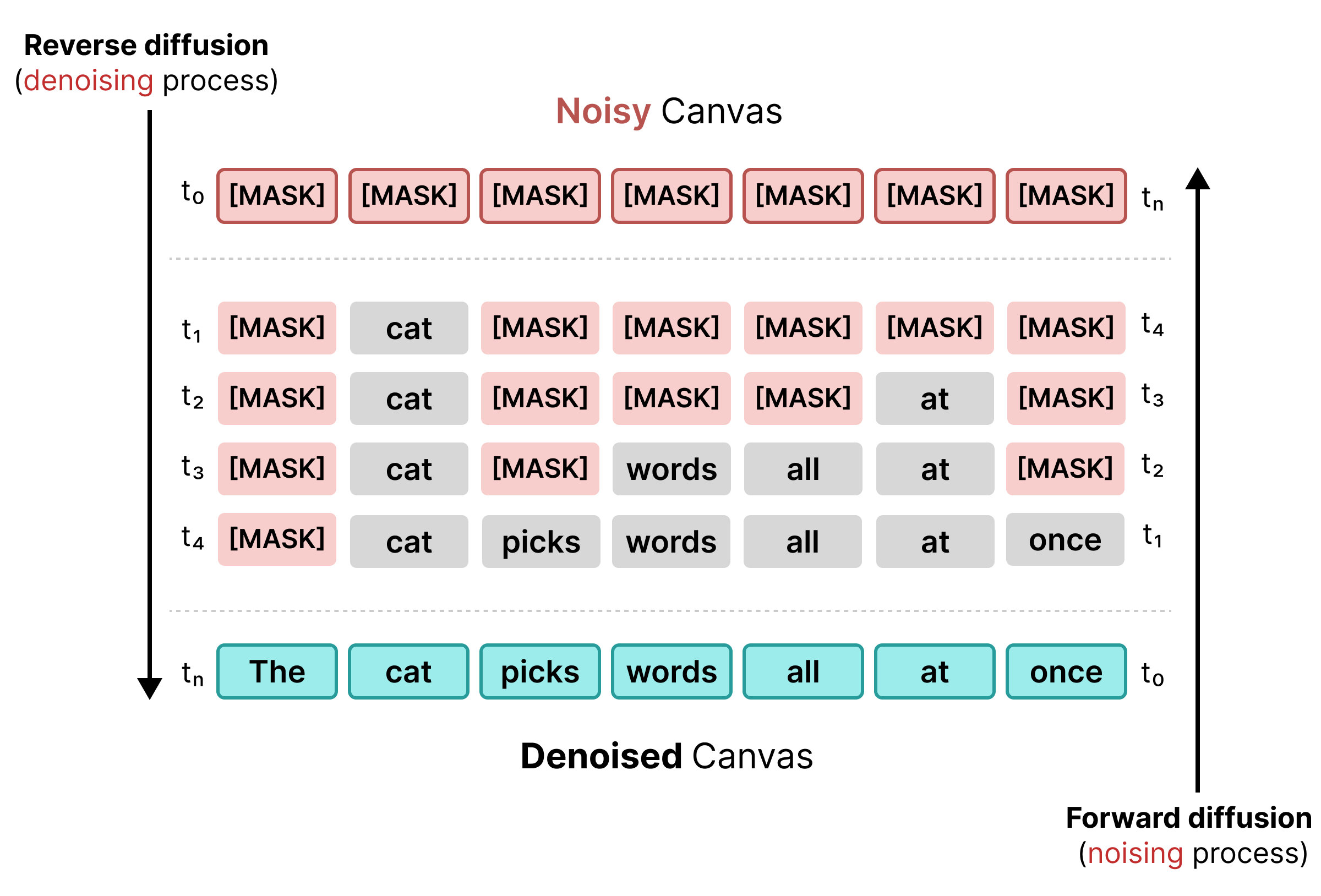
टेक्स्ट डिफ़्यूज़न के शुरुआती दौर में, मास्किंग का इस्तेमाल किया जाता था. यह BERT की ट्रेनिंग की तरह ही है. किसी सीक्वेंस में मौजूद रैंडम टोकन को [MASK] टोकन (जो नॉइज़ को दिखाता है) से बदल दिया जाता है. रिवर्स डिफ़्यूज़न के दौरान, मॉडल मास्क के पीछे मौजूद सही टोकन का अनुमान लगाता है. साथ ही, उन टोकन को बदलता है जहां कॉन्फ़िडेंस, तय सीमा को पूरा करता है.
हालांकि, मास्क किए गए डिफ़्यूज़न में एक समस्या होती है: [MASK] टोकन को किसी शब्द से बदलने के बाद, उसे लॉक कर दिया जाता है. अगर आस-पास का कॉन्टेक्स्ट बदलता है, तो बाद के चरणों में इसे ठीक नहीं किया जा सकता.
2. यूनिफ़ॉर्म स्टेट डिफ़्यूज़न
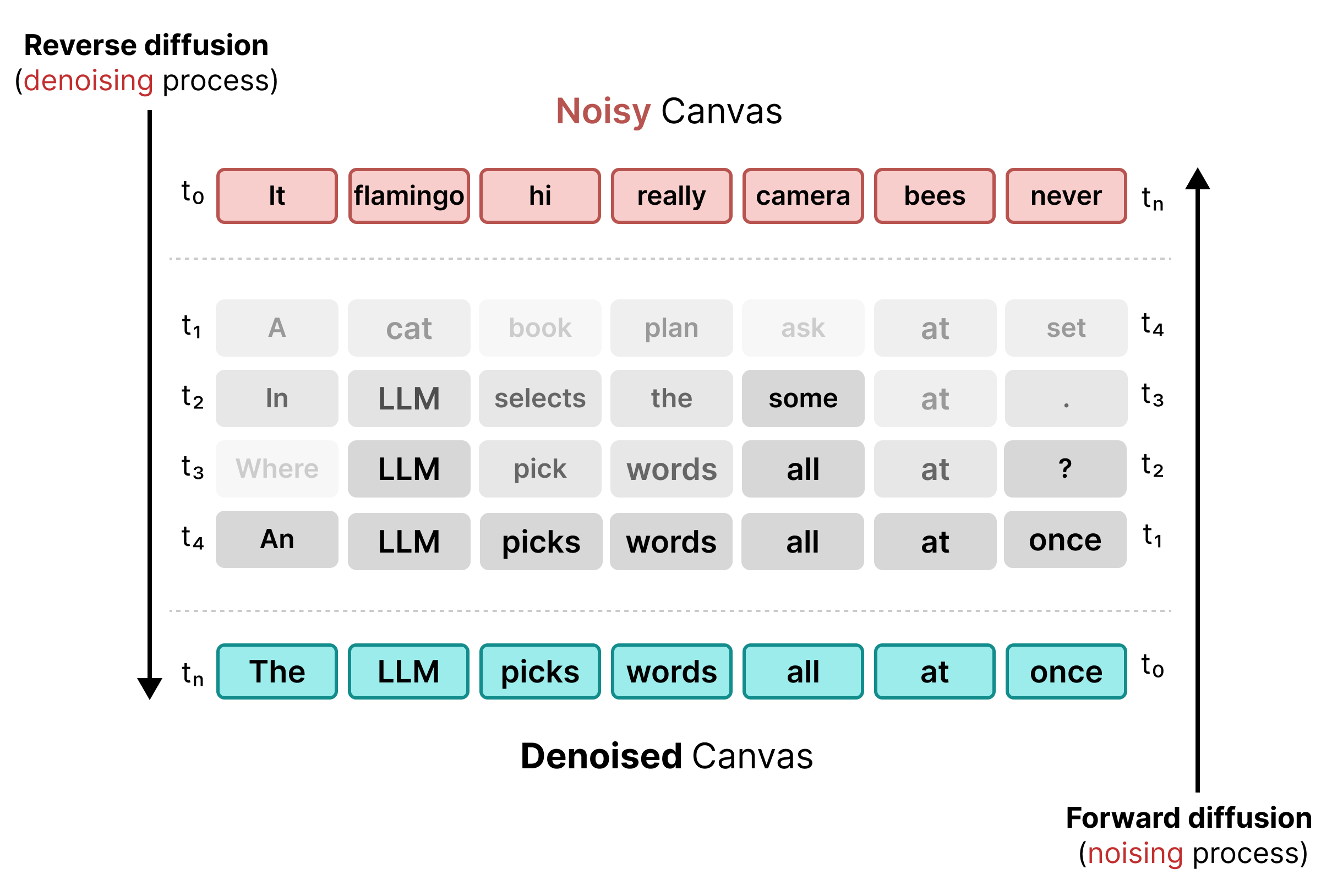
मास्किंग की सीमाओं को हल करने के लिए, DiffusionGemma यूनिफ़ॉर्म स्टेट डिफ़्यूज़न का इस्तेमाल करता है. [MASK] टोकन के बजाय, ओरिजनल शब्दों को शब्दावली से पूरी तरह रैंडम टोकन से बदलकर नॉइज़ जोड़ा जाता है.
डीनॉइज़िंग की प्रोसेस के दौरान, मॉडल पूरे कैनवस का विश्लेषण करके यह पता लगाता है कि कौनसे टोकन कॉन्टेक्चुअल नॉइज़ हैं. इसके बाद, उन्हें अपडेट करता है. अगर कोई टोकन सही है, तो उसकी प्रॉबेबिलिटी ज़्यादा होती है. अगर बाद के चरणों में नया कॉन्टेक्स्ट सामने आने की वजह से, किसी टोकन की प्रॉबेबिलिटी तय सीमा से कम हो जाती है, तो उसे नए रैंडम टोकन के साथ फिर से नॉइज़ किया जाता है. इस साइकल से, गड़बड़ी को लगातार ठीक किया जा सकता है और कैनवस को एक साथ बेहतर बनाया जा सकता है.
आर्किटेक्चर: धीरे-धीरे प्रीफ़िल और डीनॉइज़िंग
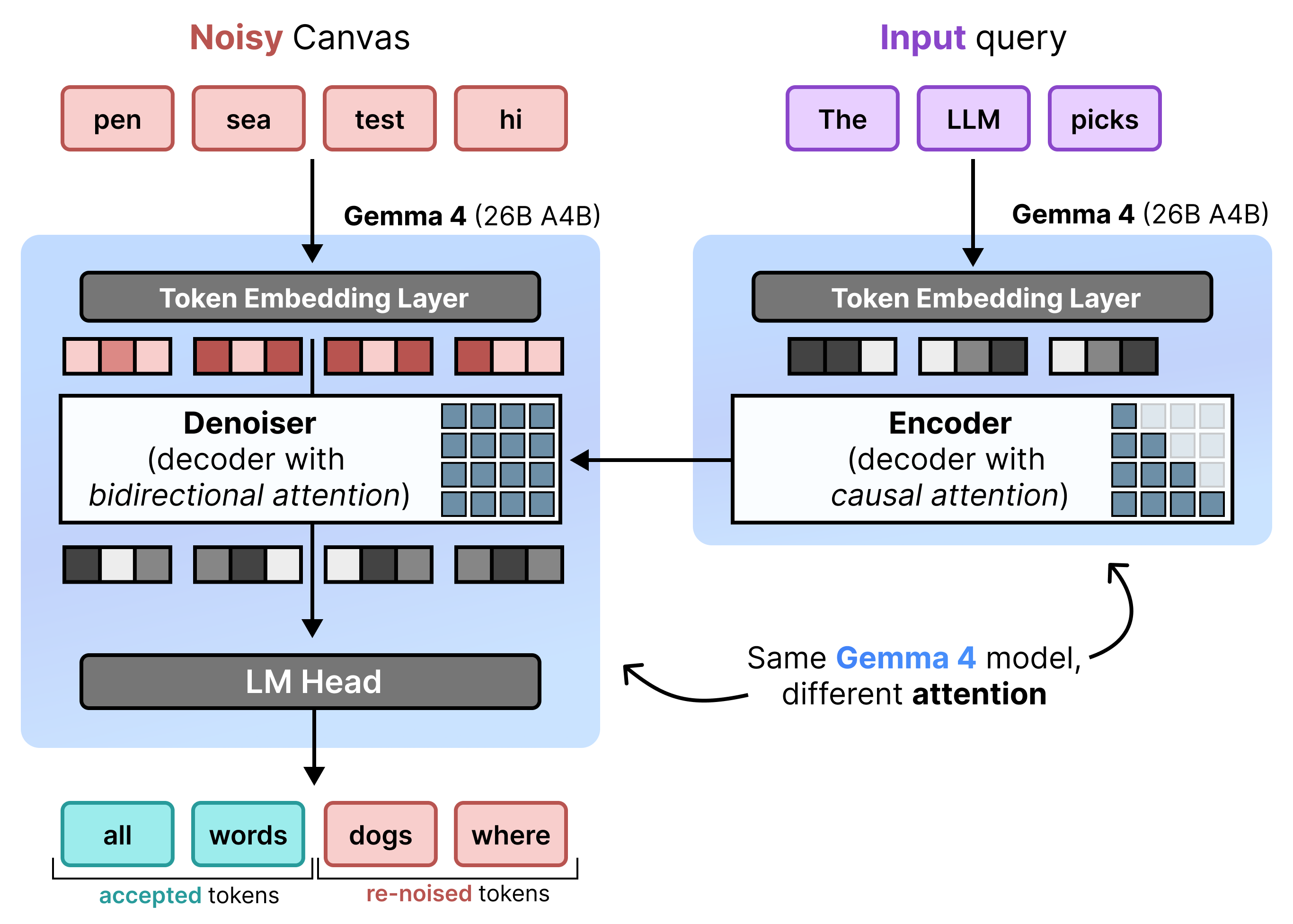
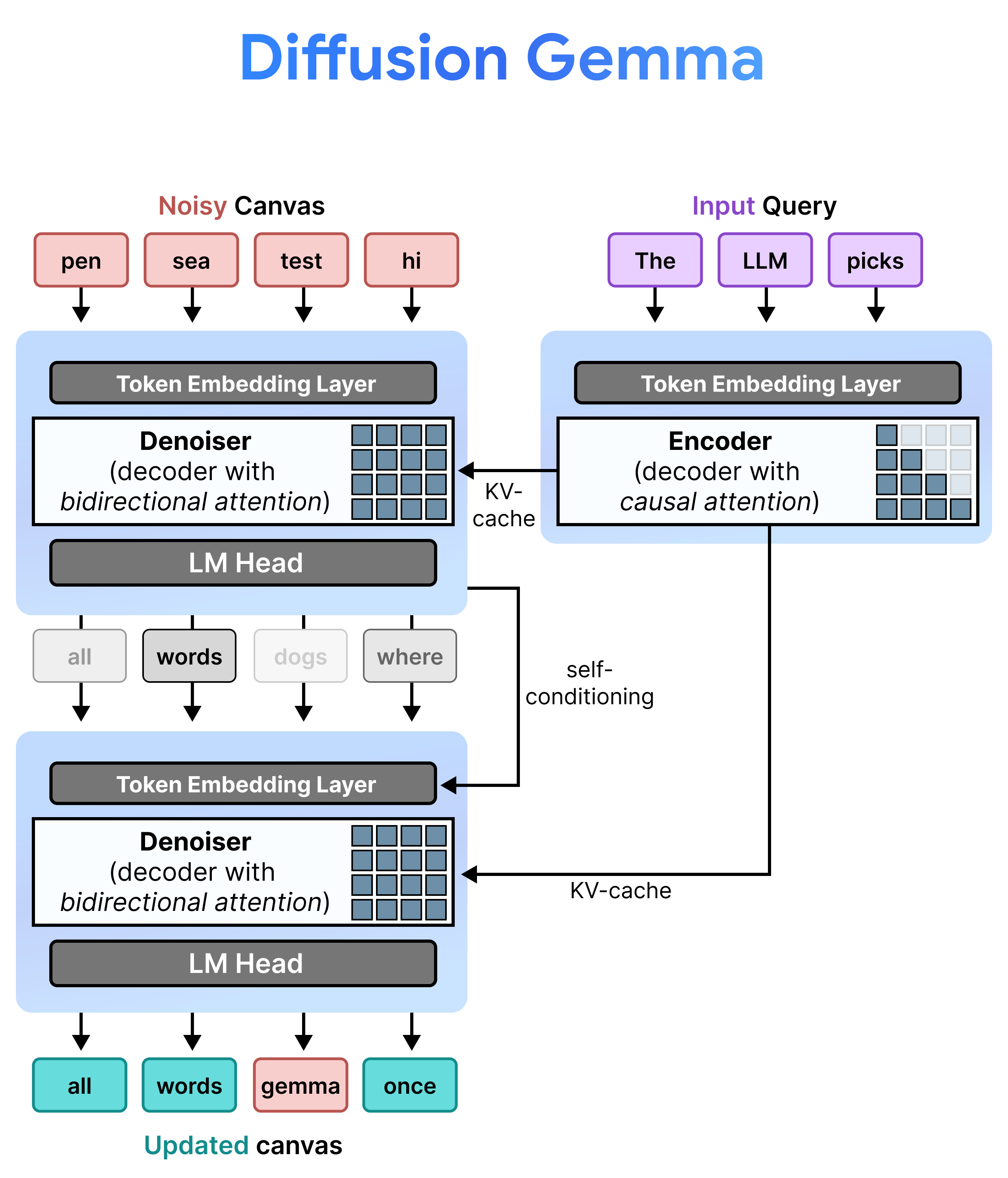
DiffusionGemma, धीरे-धीरे प्रीफ़िल और डीनॉइज़िंग के बीच बारी-बारी से स्विच करके, यूनिफ़ॉर्म स्टेट डिफ़्यूज़न को बेहतर तरीके से लागू करता है. Gemma 4 26B A4B मॉडल का इस्तेमाल, नेटिव तौर पर नहीं किया जाता. हालांकि, इसे डीनॉइज़िंग और एन्कोडिंग के अलग-अलग टास्क के लिए फ़ाइन-ट्यून किया जाता है. अलग-अलग मॉडल इस्तेमाल करने के बजाय, एक ही बैकबोन डाइनैमिक तौर पर दो मोड के बीच टॉगल करती है:
- प्रीफ़िल / धीरे-धीरे प्रीफ़िल (कॉज़ल): प्रॉम्प्ट कॉन्टेक्स्ट को इनजेस्ट करने और केवी कैश में लिखने के लिए, कॉज़ल अटेंशन का इस्तेमाल करता है. यह शुरुआती कॉन्टेक्स्ट को प्रीफ़िल करने के लिए एक बार चलता है. इसके बाद, अगले कैनवस को डीनॉइज़ करने से पहले, फ़ाइनल किए गए हर 256-टोकन कैनवस को केवी कैश में जोड़ने के लिए, हर ब्लॉक के लिए एक बार चलता है.
- डीनॉइज़िंग (बिडायरैक्शनल): कैनवस को धीरे-धीरे डीनॉइज़ करने के लिए, बिडायरैक्शनल अटेंशन का इस्तेमाल करता है. कैनवस पर किसी भी पोज़िशन पर मौजूद क्वेरी टोकन, कैनवस के अन्य सभी टोकन (साथ ही, केवी कैश) पर ध्यान दे सकते हैं. इससे मॉडल, कॉन्टेक्स्ट को बिडायरैक्शनल तरीके से प्रोसेस कर सकता है.
ऐडवांस इन्फ़रेंस फ़्रेमवर्क
DiffusionGemma, कैनवस को पूरी तरह नॉइज़ से फ़ाइनल किए गए टेक्स्ट में बदलने के लिए, डिकोडिंग के अलग-अलग सिस्टम का इस्तेमाल करता है:
सेल्फ़-कंडीशनिंग
इन्फ़रेंस के दौरान, डिकोडर (जिसे डीनॉइज़र भी कहा जाता है) अपनी पिछली स्थिति को बनाए रखता है. डीनॉइज़िंग का चरण पूरा करने के बाद, यह जनरेट किए गए प्रॉबेबिलिटी डिस्ट्रिब्यूशन मैट्रिक्स को टोकन एम्बेडिंग टेबल से गुणा करता है. इससे स्थानीय जगह के मुताबिक वेक्टर रिप्रेजेंटेशन बनता है. इसमें पहले के अनुमानों और कॉन्फ़िडेंस मेट्रिक की मेमोरी होती है. इसे सीधे अगले चरण में पास किया जाता है.
मल्टी-कैनवस सैंपलिंग (ब्लॉक डिफ़्यूज़न)
किसी एक कैनवस में 256 टोकन होते हैं. इसलिए, DiffusionGemma, लंबे फ़ॉर्म वाले टेक्स्ट के लिए डिफ़्यूज़न और ऑटोरिग्रेसन को एक साथ चेन करता है. यह 256-टोकन का पूरा ब्लॉक जनरेट करने के लिए, डिफ़्यूज़न साइकल चलाता है. इसके बाद, उस पूरे ब्लॉक को प्रॉम्प्ट कॉन्टेक्स्ट में जोड़ता है, एन्कोडर के केवी कैश को अपडेट करता है, और 256-टोकन कैनवस डिफ़्यूज़न की नई साइकल शुरू करता है.
खास जानकारी
स्टैंडर्ड ऑटोरिग्रेसिव लैंग्वेज मॉडल, टेक्स्ट को क्रम से जनरेट करते हैं (एक बार में एक टोकन). इससे वे मेमोरी-बाउंड हो जाते हैं और अलग-अलग उपयोगकर्ताओं के लिए इंतज़ार का समय बढ़ जाता है. DiffusionGemma , कंप्यूट-बाउंड मॉडल में बदलकर इस समस्या को हल करता है. यह एक साथ 256-टोकन का "कैनवस" जनरेट करता है.
यूनिफ़ॉर्म स्टेट डिफ़्यूज़न का इस्तेमाल करके, मॉडल टेक्स्ट को रैंडम शब्दावली नॉइज़ से बदलता है. साथ ही, पूरे कैनवस को एक साथ बेहतर बनाता है. यह डीनॉइज़िंग और एन्कोडिंग के अलग-अलग टास्क के लिए, फ़ाइन-ट्यून किए गए Gemma 4 26B A4B का इस्तेमाल करता है. सेल्फ़-कंडीशनिंग और मल्टी-कैनवस ब्लॉक सैंपलिंग जैसे ऐडवांस फ़्रेमवर्क की मदद से, मॉडल डाइनैमिक तौर पर गड़बड़ियों को ठीक कर सकता है, लंबे फ़ॉर्म वाले जनरेशन को हैंडल कर सकता है, और एक उपयोगकर्ता के लिए इंतज़ार का समय बहुत कम रख सकता है.