
Für viele Unternehmen ist es entscheidend, KI-Technologien in einer bestimmten gesprochenen Sprache nutzen zu können. Die Gemma-Modellfamilie bietet einige mehrsprachige Funktionen. Die Verwendung in anderen Sprachen als Englisch führt jedoch häufig zu weniger als idealen Ergebnissen.
Glücklicherweise müssen Sie Gemma nicht eine ganze gesprochene Sprache beibringen, damit sie Aufgaben in dieser Sprache erledigen kann. Außerdem können Sie Gemma-Modelle so optimieren, dass sie bestimmte Aufgaben in einer Sprache mit viel weniger Daten und Aufwand erledigen, als Sie vielleicht denken. Anhand von etwa 20 Beispielen für Anfragen und erwartete Antworten in Ihrer Zielsprache kann Gemma Ihnen helfen, viele verschiedene Geschäftsprobleme in der Sprache zu lösen, die für Sie und Ihre Kunden am besten geeignet ist.
Eine Videoübersicht über das Projekt und Informationen dazu, wie Sie es erweitern können, einschließlich Informationen von den Entwicklern, finden Sie im Video zu Spoken Language AI Assistant Build with Google AI. Sie können sich den Code für dieses Projekt auch im Gemma Cookbook-Code-Repository ansehen. Andernfalls können Sie mit der folgenden Anleitung beginnen, das Projekt zu erweitern.
Übersicht
In dieser Anleitung erfahren Sie, wie Sie eine mit Gemma und Python erstellte Anwendung für Aufgaben mit gesprochener Sprache einrichten, ausführen und erweitern. Die Anwendung bietet eine einfache Weboberfläche, die Sie an Ihre Anforderungen anpassen können. Die Anwendung ist darauf ausgelegt, Antworten auf Kunden-E-Mails für eine fiktive koreanische Bäckerei zu generieren. Die gesamte Spracheingabe und -ausgabe erfolgt vollständig auf Koreanisch. Sie können dieses Anwendungsmuster mit jeder Sprache und jeder geschäftlichen Aufgabe verwenden, bei der Text eingegeben und ausgegeben wird.
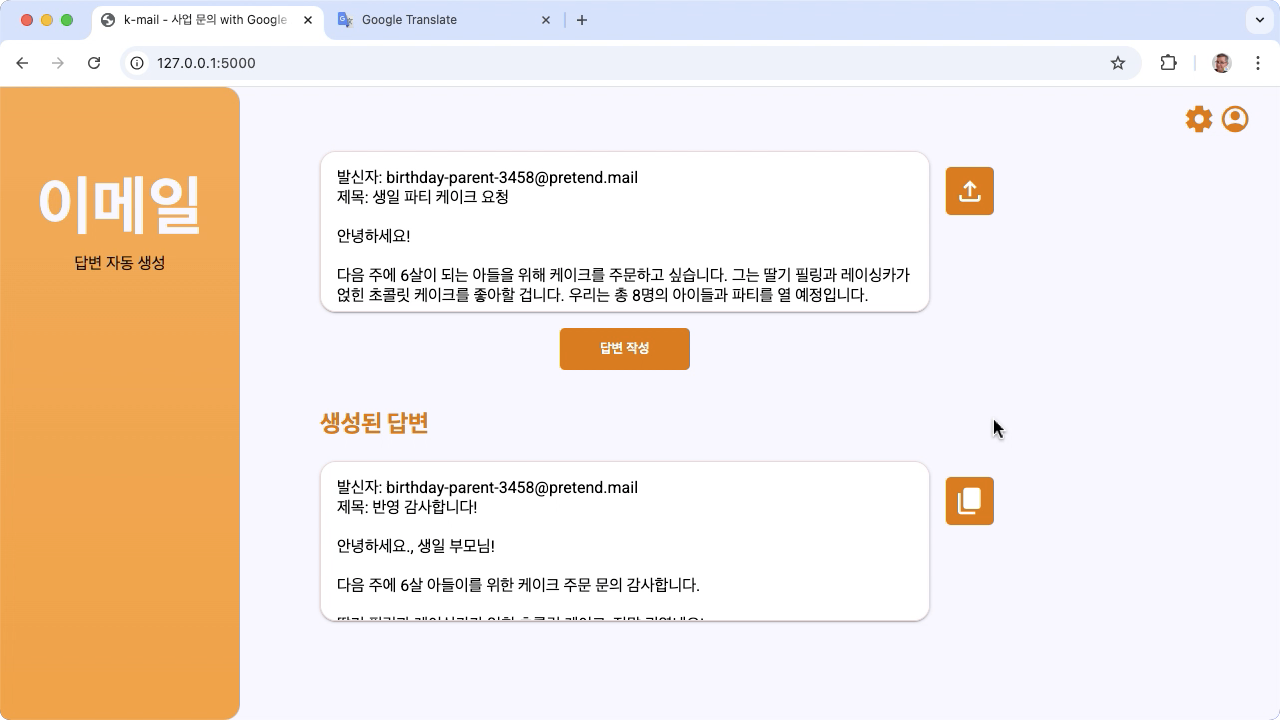
Abbildung 1. Benutzeroberfläche des Projekts für E-Mail-Anfragen an eine koreanische Bäckerei
Hardwareanforderungen
Führen Sie diesen Optimierungsprozess auf einem Computer mit einer Grafikprozessoreinheit (GPU) oder einer Tensor Processing Unit (TPU) und ausreichend Arbeitsspeicher aus, um das vorhandene Modell sowie die Optimierungsdaten zu speichern. Für die Ausführung der Optimierungskonfiguration in diesem Projekt benötigen Sie etwa 16 GB GPU-Speicher, etwa die gleiche Menge an regulärem RAM und mindestens 50 GB Speicherplatz.
Sie können den Abschnitt zur Optimierung des Gemma-Modells in dieser Anleitung in einer Colab-Umgebung mit einer T4-GPU ausführen. Wenn Sie dieses Projekt auf einer VM-Instanz in Google Cloud erstellen, konfigurieren Sie die Instanz gemäß den folgenden Anforderungen:
- GPU-Hardware: Für die Ausführung dieses Projekts ist eine NVIDIA T4 erforderlich. Eine NVIDIA L4 oder höher wird empfohlen.
- Betriebssystem: Wählen Sie eine Option für Deep Learning unter Linux aus, insbesondere die Deep Learning VM mit CUDA 12.3 M124 mit vorinstallierten GPU-Softwaretreibern.
- Bootlaufwerksgröße: Stellen Sie mindestens 50 GB Speicherplatz für Ihre Daten, Modelle und zugehörige Software bereit.
Projekt einrichten
In dieser Anleitung erfahren Sie, wie Sie dieses Projekt für die Entwicklung und Tests vorbereiten. Zu den allgemeinen Einrichtungsschritten gehören die Installation der erforderlichen Software, das Klonen des Projekts aus dem Code-Repository, das Festlegen einiger Umgebungsvariablen, die Installation von Python-Bibliotheken und das Testen der Webanwendung.
Installieren und konfigurieren
Dieses Projekt verwendet Python 3 und virtuelle Umgebungen (venv), um Pakete zu verwalten und die Anwendung auszuführen. Die folgende Installationsanleitung gilt für einen Linux-Hostcomputer.
So installieren Sie die erforderliche Software:
Installieren Sie Python 3 und das virtuelle Umgebungspaket
venvfür Python.sudo apt update sudo apt install git pip python3-venv
Projekt klonen
Laden Sie den Projektcode auf Ihren Entwicklungscomputer herunter. Sie benötigen die Quellcode-Verwaltungssoftware git, um den Quellcode des Projekts abzurufen.
So laden Sie den Projektcode herunter:
Klonen Sie das Git-Repository mit dem folgenden Befehl:
git clone https://github.com/google-gemini/gemma-cookbook.gitOptional können Sie Ihr lokales Git-Repository so konfigurieren, dass eine spärliche Überprüfung verwendet wird, sodass nur die Dateien für das Projekt vorhanden sind.
cd gemma-cookbook/ git sparse-checkout set Demos/spoken-language-tasks/ git sparse-checkout init --cone
Python-Bibliotheken installieren
Installieren Sie die Python-Bibliotheken mit aktivierter venv virtueller Python-Umgebung, um Python-Pakete und ‑Abhängigkeiten zu verwalten. Aktivieren Sie die virtuelle Python-Umgebung vor der Installation von Python-Bibliotheken mit dem pip-Installationsprogramm. Weitere Informationen zur Verwendung virtueller Python-Umgebungen finden Sie in der Python venv-Dokumentation.
So installieren Sie die Python-Bibliotheken:
Wechseln Sie in einem Terminalfenster zum Verzeichnis
spoken-language-tasks:cd Demos/spoken-language-tasks/Konfigurieren und aktivieren Sie die virtuelle Python-Umgebung (venv) für dieses Projekt:
python3 -m venv venv source venv/bin/activateInstallieren Sie die erforderlichen Python-Bibliotheken für dieses Projekt mit dem Script
setup_python../setup_python.sh
Umgebungsvariablen festlegen
Legen Sie einige Umgebungsvariablen fest, die erforderlich sind, damit dieses Codeprojekt ausgeführt werden kann, einschließlich eines Kaggle-Nutzernamens und eines Kaggle-Token-Schlüssels. Sie benötigen ein Kaggle-Konto und müssen Zugriff auf die Gemma-Modelle anfordern, um sie herunterladen zu können. Für dieses Projekt fügen Sie Ihren Kaggle-Nutzernamen und Ihren Kaggle-Tokenschlüssel zwei .env-Dateien hinzu, die von der Webanwendung bzw. dem Abstimmungsprogramm gelesen werden.
So legen Sie die Umgebungsvariablen fest:
- Rufen Sie Ihren Kaggle-Nutzernamen und Ihren Tokenschlüssel ab. Folgen Sie dazu der Anleitung in der Kaggle-Dokumentation.
- Folgen Sie der Anleitung Zugriff auf Gemma erhalten auf der Seite Gemma-Einrichtung, um Zugriff auf das Gemma-Modell zu erhalten.
- Erstellen Sie Umgebungsvariablendateien für das Projekt. Erstellen Sie dazu
.env-Textdateien an allen folgenden Speicherorten in Ihrem Klon des Projekts:k-mail-replier/k_mail_replier/.env k-gemma-it/.env
Nachdem Sie die
.env-Textdateien erstellt haben, fügen Sie beiden Dateien die folgenden Einstellungen hinzu:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
Anwendung ausführen und testen
Nachdem Sie die Installation und Konfiguration des Projekts abgeschlossen haben, führen Sie die Webanwendung aus, um zu prüfen, ob Sie sie richtig konfiguriert haben. Sie sollten dies als Referenzprüfung tun, bevor Sie das Projekt für Ihre eigene Verwendung bearbeiten.
So führen Sie das Projekt aus und testen es:
Rufen Sie in einem Terminalfenster das Verzeichnis
/k_mail_replier/auf:cd spoken-language-tasks/k-mail-replier/Führen Sie die Anwendung mit dem Skript
run_flask_app.shaus:./run_flask_app.shNachdem Sie die Webanwendung gestartet haben, wird im Programmcode eine URL aufgelistet, unter der Sie suchen und testen können. Normalerweise ist dies:
http://127.0.0.1:5000/Drücken Sie in der Weboberfläche unter dem ersten Eingabefeld die Schaltfläche 답변 작성, um eine Antwort vom Modell zu generieren.
Die erste Antwort des Modells nach dem Ausführen der Anwendung dauert länger, da bei der ersten Ausführung der Generation die Initialisierungsschritte abgeschlossen werden müssen. Nachfolgende Promptanfragen und -generierungen in einer bereits laufenden Webanwendung werden in kürzerer Zeit abgeschlossen.
Anwendung erweitern
Sobald die Anwendung ausgeführt wird, können Sie sie erweitern, indem Sie die Benutzeroberfläche und die Geschäftslogik ändern, damit sie für Aufgaben eingesetzt werden kann, die für Sie oder Ihr Unternehmen relevant sind. Sie können auch das Verhalten des Gemma-Modells mithilfe des Anwendungscodes ändern. Dazu ändern Sie die Komponenten des Prompts, den die App an das Generative-AI-Modell sendet.
Die Anwendung stellt dem Modell zusammen mit den Eingabedaten des Nutzers eine vollständige Prompt-Anleitung zur Verfügung. Sie können diese Anweisungen ändern, um das Verhalten des Modells zu ändern. Sie können beispielsweise angeben, dass das Modell Informationen aus der Anfrage extrahieren und in ein strukturiertes Datenformat wie JSON einfügen soll. Eine einfachere Möglichkeit, das Verhalten des Modells zu ändern, besteht darin, zusätzliche Anweisungen oder Richtlinien für die Antwort des Modells anzugeben, z. B. dass die generierten Antworten in einem höflichen Ton verfasst werden sollen.
So ändern Sie die Promptanleitung:
- Öffnen Sie im Projekt für gesprochene Sprache die Codedatei
k-mail-replier/k_mail_replier/app.py. Fügen Sie im Code von
app.pyder Funktionget_prompt():Anweisungen für Ergänzungen hinzu:def get_prompt(): return "발신자에게 요청에 대한 감사를 전하고, 곧 자세한 내용을 알려드리겠다고 정중하게 답장해 주세요. 정중하게 답변해 주세요!:\n"
In diesem Beispiel wird der Anleitung auf Koreanisch der Satz „Bitte schreiben Sie eine höfliche Antwort.“ hinzugefügt.
Zusätzliche Prompt-Anweisungen können die generierte Ausgabe stark beeinflussen und ihre Implementierung erfordert deutlich weniger Aufwand. Sie sollten diese Methode zuerst ausprobieren, um zu sehen, ob sich das gewünschte Verhalten aus dem Modell ergibt. Die Verwendung von Promptanweisungen zur Änderung des Verhaltens eines Gemma-Modells hat jedoch Grenzen. Insbesondere müssen Sie das Gesamtlimit für Eingabetokens des Modells, das für Gemma 2 8.192 Tokens beträgt, beachten. Sie müssen also die detaillierten Promptanweisungen mit der Größe der von Ihnen bereitgestellten neuen Daten in Einklang bringen, damit Sie dieses Limit nicht überschreiten.
Wenn Sie möchten, dass Gemma Aufgaben in einer anderen Sprache als Englisch ausführt, ist es unwahrscheinlich, dass Sie mit dem Basismodell zuverlässig nützliche Ergebnisse erzielen. Stattdessen sollten Sie das Modell mit Beispielen in der Zielsprache optimieren und dann die Promptanweisungen ändern, um kleinere Anpassungen an der Ausgabe des optimierten Modells vorzunehmen.
Modell abstimmen
Die Feinabstimmung eines Gemma-Modells ist die empfohlene Methode, um es dazu zu bringen, effektiv in einer anderen Sprache als Englisch zu antworten. Sie müssen Ihre Zielsprache jedoch nicht vollständig beherrschen, damit das Modell Aufgaben in dieser Sprache ausführen kann. Mit etwa 20 Beispielen können Sie die grundlegenden Funktionen in Ihrer Zielsprache für eine Aufgabe erreichen. In diesem Abschnitt des Tutorials wird erläutert, wie Sie die Feinabstimmung eines Gemma-Modells für eine bestimmte Aufgabe in einer bestimmten Sprache einrichten und ausführen.
In der folgenden Anleitung wird erläutert, wie die Abstimmung in einer VM-Umgebung durchgeführt wird. Sie können diesen Abstimmungsvorgang jedoch auch mit dem zugehörigen Colab-Notebook für dieses Projekt ausführen.
Hardwareanforderungen
Die Rechenanforderungen für die Feinabstimmung stimmen mit den Hardwareanforderungen für den Rest des Projekts überein. Sie können die Optimierung in einer Colab-Umgebung mit einer T4-GPU-Laufzeit ausführen, wenn Sie die Eingabetokens auf 256 und die Batchgröße auf 1 begrenzen.
Daten vorbereiten
Bevor Sie mit der Optimierung eines Gemma-Modells beginnen, müssen Sie Daten für die Optimierung vorbereiten. Wenn Sie ein Modell für eine bestimmte Aufgabe und Sprache optimieren, benötigen Sie eine Reihe von Anfrage- und Antwortbeispielen in dieser Zielsprache. Diese Beispiele sollten den Anfragetext ohne Anleitung und den erwarteten Antworttext enthalten. Zuerst sollten Sie ein Dataset mit etwa 20 Beispielen vorbereiten. Diese Beispiele sollten eine Vielzahl von Anfragen und die idealen Antworten darstellen. Achten Sie darauf, dass die Anfragen und Antworten nicht repetitiv sind, da dies dazu führen kann, dass die Antworten des Modells repetitiv sind und sich nicht angemessen an Abweichungen bei den Anfragen anpassen. Die folgende Tabelle zeigt einige Beispieldatensätze aus dem Dataset dieses Codebeispiels:
| Anfrage | Antwort |
|---|---|
| 안녕니프요, 2주 뒤에 있welt 아이 생일기 위해 3호 케이크 3개를 주문시고 싶은데 전능할요? | 고객님, 안녕하세요. 2주 뒤 아이 생일을 위한 3호 케이크 2개 주문 문의 감사합니다. ( 아이 생일 케이크인 만큼 더욱 신경 써서 인성껏 준인겠습니니. 혹시 원인시파 전자인이파 특별한 요청 사항이 있으시면 편시게 말씀해주정요. 픽업 날짜와 시간을 알려주시면 더욱 자세한 안내를 도와드리겠습니다. 다시 한번 문의 감사드리며, 아이 생일 진심으로 축하합니다! [가게 이름] 드림 |
| 안녕하세요, 9월 15일에 있을 아들의 돌잔치를 위해 케이크를 주문하고 싶습니다. - 케이크 종류: 생크림 케이크 - 크기: 2호 - 디자인: 아기자기한 동물 디자인 - 문구: "첫 생일 축하해, 사랑하는 아들!" - 픽업 날짜 및 시간: 9월 14일 오후 3시 가격 및 주문 가능 여부를 알려주시면 감사하겠습니다. 감사합니다. 김민지 드림 | 안녕하세요, 김민지 님, 9월 15일 아드님의 돌잔치를 위한 케이크 주문 문의 감사합니다. - 생크림 케이크 2호, 아기자기한 동물 디자인, "첫 생일 축하해, 사랑하는 아들!" 문구, 9월 14bro - 가격은 5만원입니다. 주문을 원하시면 연락 주세요 감사합니다. [가게 이름] 드림 |
Tabelle 1. Teilliste des Tuning-Datasets für die E-Mail-Antworten der koreanischen Bäckerei.
Datenformat und -ladevorgang
Sie können Ihre Abstimmungsdaten in jedem beliebigen Format speichern, einschließlich Datenbankeinträgen, JSON-Dateien, CSV- oder Nur-Text-Dateien, sofern Sie die Datensätze mit Python-Code abrufen können. Im Beispiel-Optimierungsprogramm werden die Einträge zur besseren Übersicht aus einem Online-Repository abgerufen.
In diesem Beispiel für ein Drehprogramm wird der Tuning-Datensatz mit der Funktion prepare_tuning_dataset() in das Modul k-gemma-it/main.py geladen:
def prepare_tuning_dataset():
tokenizer = keras_nlp.models.GemmaTokenizer.from_preset(model_id)
# load data from repository (or local directory)
from datasets import load_dataset
ds = load_dataset(
# Dataset : https://huggingface.co/datasets/bebechien/korean_cake_boss
"bebechien/korean_cake_boss",
split="train",
)
...
Wie bereits erwähnt, können Sie den Datensatz in einem beliebigen Format speichern, solange Sie die Anfragen mit den zugehörigen Antworten abrufen und in einen Textstring zusammenstellen können, der als Tuning-Eintrag verwendet wird.
Abstimmungsdatensätze zusammenstellen
Für den eigentlichen Tuning-Prozess werden jede Anfrage und Antwort in einem einzigen String mit den Prompt-Anweisungen und Tags zusammengestellt, um den Inhalt der Anfrage und der Antwort anzugeben. Dieses Tuning-Programm tokenisiert dann den String für die Verwendung durch das Modell. Der Code zum Zusammenstellen eines Tuning-Eintrags befindet sich in der Funktion prepare_tuning_dataset() des Moduls k-gemma-it/main.py:
def prepare_tuning_dataset():
...
prompt_instruction = "다음에 대한 이메일 답장을 작성해줘."
for x in data:
item = f"<start_of_turn>user\n{prompt_instruction}\n\"{x['input']}\"<end_of_turn>\n<start_of_turn>model\n{x['output']}<end_of_turn>"
length = len(tokenizer(item))
# skip data if the token length is longer than our limit
if length < token_limit:
tuning_dataset.append(item)
if(len(tuning_dataset)>=num_data_limit):
break
...
Diese Funktion liest die Daten ein und formatiert sie durch Hinzufügen von start_of_turn- und end_of_turn-Tags. Das ist das erforderliche Format, wenn Sie Daten zur Optimierung eines Gemma-Modells angeben. Mit diesem Code wird außerdem für jede Anfrage ein prompt_instruction eingefügt, das Sie entsprechend Ihrer Anwendung bearbeiten sollten.
Modellgewichtungen generieren
Sobald die Abstimmungsdaten vorhanden sind und geladen wurden, können Sie das Abstimmungsprogramm ausführen. Bei der Optimierung dieser Beispielanwendung wird die Keras-NLP-Bibliothek verwendet, um das Modell mithilfe der Low-Rank-Adaption (LoRA) zu optimieren und neue Modellgewichte zu generieren. Im Vergleich zur vollständigen Tuning-Genauigkeit ist die Verwendung von LoRA deutlich speichereffizienter, da die Änderungen an den Modellgewichten angenähert werden. Sie können diese geschätzten Gewichtungen dann auf die vorhandenen Modellgewichte legen, um das Modellverhalten zu ändern.
So führen Sie die Abstimmung durch und berechnen neue Gewichtungen:
Rufen Sie in einem Terminalfenster das Verzeichnis
k-gemma-it/auf.cd spoken-language-tasks/k-gemma-it/Führen Sie die Optimierung mit dem Skript
tune_modelaus:./tune_model.sh
Die Optimierung dauert je nach verfügbaren Rechenressourcen einige Minuten. Nach erfolgreichem Abschluss schreibt das Abstimmungsprogramm neue *.h5-Gewichtungsdateien im folgenden Format in das Verzeichnis k-gemma-it/weights:
gemma2-2b_k-tuned_4_epoch##.lora.h5
Fehlerbehebung
Wenn die Abstimmung nicht erfolgreich abgeschlossen wird, gibt es zwei mögliche Gründe:
- Nicht genügend Arbeitsspeicher / Ressourcen erschöpft: Diese Fehler treten auf, wenn der Abstimmungsprozess Arbeitsspeicher anfordert, der den verfügbaren GPU-Arbeitsspeicher oder CPU-Arbeitsspeicher überschreitet. Die Webanwendung darf während des Optimierungsprozesses nicht ausgeführt werden. Wenn Sie die Optimierung auf einem Gerät mit 16 GB GPU-Speicher vornehmen, müssen Sie
token_limitauf 256 undbatch_sizeauf 1 festlegen. - GPU-Treiber nicht installiert oder nicht mit JAX kompatibel: Für die Umwandlung müssen auf dem Rechengerät Hardwaretreiber installiert sein, die mit der Version der JAX-Bibliotheken kompatibel sind. Weitere Informationen finden Sie in der Dokumentation zur JAX-Installation.
Abgestimmtes Modell bereitstellen
Bei der Optimierung werden anhand der Optimierungsdaten und der in der Optimierungsanwendung festgelegten Gesamtzahl der Epochen mehrere Gewichte generiert. Standardmäßig generiert das Optimierungsprogramm 20 Modellgewichtsdateien, eine für jede Optimierungsepoche. Mit jeder nachfolgenden Tuning-Epoche werden Gewichte generiert, die die Ergebnisse der Tuning-Daten genauer reproduzieren. Die Genauigkeitsraten für jede Epoche werden in der Terminalausgabe des Abstimmungsprozesses so angezeigt:
...
Epoch 14/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 567ms/step - loss: 0.4026 - sparse_categorical_accuracy: 0.8235
Epoch 15/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 569ms/step - loss: 0.3659 - sparse_categorical_accuracy: 0.8382
Epoch 16/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 571ms/step - loss: 0.3314 - sparse_categorical_accuracy: 0.8538
Epoch 17/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 572ms/step - loss: 0.2996 - sparse_categorical_accuracy: 0.8686
Epoch 18/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 574ms/step - loss: 0.2710 - sparse_categorical_accuracy: 0.8801
Epoch 19/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2451 - sparse_categorical_accuracy: 0.8903
Epoch 20/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2212 - sparse_categorical_accuracy: 0.9021
Die Genauigkeitsrate sollte relativ hoch sein, etwa 0,80 bis 0,90. Sie sollte jedoch nicht zu hoch oder sehr nah an 1,00 liegen, da dies bedeutet, dass die Gewichte fast zu einer Überanpassung der Tuning-Daten geführt haben. In diesem Fall funktioniert das Modell bei Anfragen, die sich deutlich von den Beispielen für die Optimierung unterscheiden, nicht gut. Standardmäßig werden im Bereitstellungsskript die Gewichte der Epoche 17 ausgewählt, die in der Regel eine Genauigkeitsrate von etwa 0,90 haben.
So stellen Sie die generierten Gewichtungen für die Webanwendung bereit:
Rufen Sie in einem Terminalfenster das Verzeichnis
k-gemma-it/auf.cd spoken-language-tasks/k-gemma-it/Führen Sie die Optimierung mit dem Skript
deploy_weightsaus:./deploy_weights.sh
Nachdem Sie das Skript ausgeführt haben, sollte im Verzeichnis k-mail-replier/k_mail_replier/weights/ eine neue *.h5-Datei angezeigt werden.
Neues Modell testen
Nachdem Sie die neuen Gewichte in der Anwendung bereitgestellt haben, können Sie das neu optimierte Modell testen. Dazu müssen Sie die Webanwendung noch einmal ausführen und eine Antwort generieren.
So führen Sie das Projekt aus und testen es:
Wechseln Sie in einem Terminalfenster zum Verzeichnis
/k_mail_replier/.cd spoken-language-tasks/k-mail-replier/Führen Sie die Anwendung mit dem Skript
run_flask_app.shaus:./run_flask_app.shNachdem Sie die Webanwendung gestartet haben, wird im Programmcode eine URL aufgeführt, unter der Sie die Anwendung aufrufen und testen können. Normalerweise lautet diese Adresse:
http://127.0.0.1:5000/Klicken Sie in der Weboberfläche unter dem ersten Eingabefeld auf die Schaltfläche 답변 작성, um eine Antwort vom Modell zu generieren.
Sie haben jetzt ein Gemma-Modell optimiert und in einer Anwendung bereitgestellt. Experimentieren Sie mit der Anwendung und versuchen Sie, die Grenzen der Generierungsfunktion des optimierten Modells für Ihre Aufgabe zu ermitteln. Wenn Sie Szenarien finden, in denen das Modell nicht gut abschneidet, können Sie einige dieser Anfragen der Liste der Beispieldaten für die Optimierung hinzufügen. Fügen Sie dazu die Anfrage hinzu und geben Sie eine ideale Antwort an. Führen Sie dann den Optimierungsprozess noch einmal aus, stellen Sie die neuen Gewichte wieder bereit und testen Sie die Ausgabe.
Zusätzliche Ressourcen
Weitere Informationen zu diesem Projekt finden Sie im Code-Repository von Gemma Cookbook. Wenn Sie Hilfe beim Erstellen der Anwendung benötigen oder mit anderen Entwicklern zusammenarbeiten möchten, besuchen Sie den Discord-Server der Google Developers Community. Weitere „Build with Google AI“-Projekte finden Sie in der Videoplaylist.