โมเดลปัญญาประดิษฐ์แบบ Generative เป็นเครื่องมือที่มีประสิทธิภาพ แต่ก็มีข้อจำกัดเช่นกัน ความสามารถรอบด้านและความสามารถในการนำไปใช้บางครั้งอาจทำให้เกิดเอาต์พุตที่ไม่คาดคิด เช่น เอาต์พุตที่ไม่ถูกต้อง มีอคติ หรือไม่เหมาะสม การประมวลผลภายหลังและการประเมินด้วยตนเองอย่างเข้มงวดจึงเป็นสิ่งจำเป็นเพื่อจำกัดความเสี่ยงที่จะเกิดอันตรายจากเอาต์พุตดังกล่าว
โมเดลที่ Gemini API มีให้สามารถใช้กับแอปพลิเคชัน Generative AI และการประมวลผลภาษาธรรมชาติ (NLP) ได้หลากหลาย การใช้ฟังก์ชันเหล่านี้จะใช้ได้ผ่าน Gemini API หรือเว็บแอป Google AI Studio เท่านั้น การใช้ Gemini API ของคุณยังเป็นไปตามนโยบายการใช้งานที่ไม่อนุญาตของ Generative AI และข้อกำหนดในการให้บริการของ Gemini API ด้วย
ส่วนหนึ่งที่ทำให้โมเดลภาษาขนาดใหญ่ (LLM) มีประโยชน์มากก็คือเป็น เครื่องมือสร้างสรรค์ที่สามารถจัดการงานด้านภาษาที่แตกต่างกันได้มากมาย อย่างไรก็ตาม นั่นหมายความว่าโมเดลภาษาขนาดใหญ่สามารถสร้างเอาต์พุตที่คุณไม่ คาดคิดได้ รวมถึงข้อความที่ไม่เหมาะสม ไม่คำนึงถึงความรู้สึก หรือไม่ถูกต้องตามข้อเท็จจริง นอกจากนี้ ความสามารถที่หลากหลายอย่างน่าทึ่งของโมเดลเหล่านี้ยังทำให้คาดเดาได้ยากว่าโมเดลอาจสร้างเอาต์พุตที่ไม่พึงประสงค์ประเภทใด แม้ว่า Gemini API จะได้รับการออกแบบโดยคำนึงถึงหลักการด้าน AI ของ Google แต่ภาระหน้าที่ในการ ใช้โมเดลเหล่านี้อย่างมีความรับผิดชอบก็ยังคงเป็นของนักพัฒนาแอป Gemini API มีการกรองเนื้อหาในตัว รวมถึงการตั้งค่าความปลอดภัยที่ปรับได้ใน 4 มิติของอันตราย เพื่อช่วยนักพัฒนาแอปในการสร้างแอปพลิเคชันที่ปลอดภัยและมีความรับผิดชอบ ดูข้อมูลเพิ่มเติมได้ที่คู่มือการตั้งค่าความปลอดภัย นอกจากนี้ยังมีการเปิดใช้ Grounding with Google Search เพื่อปรับปรุงความถูกต้องของข้อเท็จจริงด้วย แม้ว่าอาจปิดใช้ได้ สำหรับนักพัฒนาแอปที่มีกรณีการใช้งานที่สร้างสรรค์มากกว่าและไม่ได้มุ่งเน้นการค้นหาข้อมูล
เอกสารนี้มีจุดประสงค์เพื่อแนะนำความเสี่ยงด้านความปลอดภัยบางอย่างที่อาจเกิดขึ้นเมื่อ ใช้ LLM และแนะนำการออกแบบและการพัฒนาด้านความปลอดภัยที่เกิดขึ้นใหม่ (โปรดทราบว่ากฎหมายและกฎระเบียบอาจกำหนดข้อจำกัดด้วย แต่การพิจารณาดังกล่าวอยู่นอกขอบเขตของคู่มือนี้)
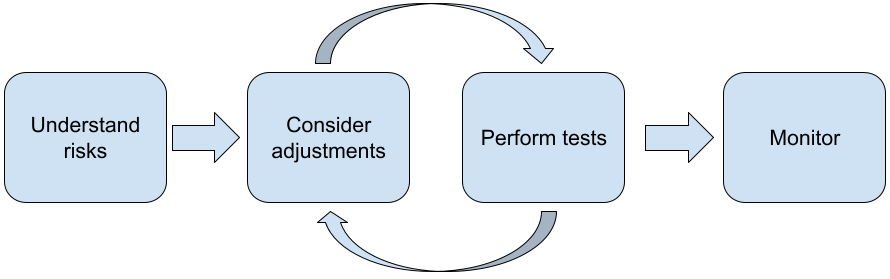
เราขอแนะนำให้ทำตามขั้นตอนต่อไปนี้เมื่อสร้างแอปพลิเคชันด้วย LLM
- ทำความเข้าใจความเสี่ยงด้านความปลอดภัยของแอปพลิเคชัน
- พิจารณาการปรับเพื่อลดความเสี่ยงด้านความปลอดภัย
- ทำการทดสอบความปลอดภัยที่เหมาะสมกับกรณีการใช้งานของคุณ
- ขอความคิดเห็นจากผู้ใช้และตรวจสอบการใช้งาน
ระยะการปรับและการทดสอบควรทำซ้ำจนกว่าคุณจะได้รับ ประสิทธิภาพที่เหมาะสมกับแอปพลิเคชัน
ทำความเข้าใจความเสี่ยงด้านความปลอดภัยของแอปพลิเคชัน
ในบริบทนี้ ความปลอดภัยหมายถึงความสามารถของ LLM ในการหลีกเลี่ยง การก่อให้เกิดอันตรายต่อผู้ใช้ เช่น การสร้างภาษาหรือเนื้อหาที่เป็นพิษ ซึ่งส่งเสริมภาพเหมารวม โมเดลที่พร้อมใช้งานผ่าน Gemini API ได้รับการออกแบบโดยคำนึงถึงหลักการเกี่ยวกับ AI ของ Google และการใช้งานโมเดลดังกล่าวเป็นไปตามนโยบายการใช้งานที่ไม่อนุญาตสำหรับ Generative AI API มีตัวกรองความปลอดภัยในตัวเพื่อช่วยแก้ปัญหาที่พบบ่อยเกี่ยวกับโมเดลภาษา เช่น ภาษาที่ไม่เหมาะสมและคำพูดที่สร้างความเกลียดชัง รวมถึงมุ่งมั่นที่จะครอบคลุม และหลีกเลี่ยงการเหมารวม อย่างไรก็ตาม แอปพลิเคชันแต่ละรายการอาจก่อให้เกิดความเสี่ยงที่แตกต่างกันต่อผู้ใช้ ดังนั้นในฐานะเจ้าของแอปพลิเคชัน คุณจึงมีหน้าที่ ทำความรู้จักผู้ใช้และอันตรายที่อาจเกิดขึ้นจากแอปพลิเคชันของคุณ และ ตรวจสอบว่าแอปพลิเคชันใช้ LLM อย่างปลอดภัยและมีความรับผิดชอบ
ในการประเมินนี้ คุณควรพิจารณาความเป็นไปได้ที่จะเกิดอันตราย รวมถึงพิจารณาความร้ายแรงและขั้นตอนการลดความเสี่ยง ตัวอย่างเช่น แอปที่สร้างเรียงความโดยอิงตามเหตุการณ์จริงจะต้องระมัดระวังเรื่องการหลีกเลี่ยงข้อมูลที่ไม่ถูกต้องมากกว่าแอปที่สร้างเรื่องราวสมมติเพื่อความบันเทิง วิธีที่ดีในการเริ่มสำรวจความเสี่ยงด้านความปลอดภัยที่อาจเกิดขึ้นคือการวิจัยผู้ใช้ปลายทางและบุคคลอื่นๆ ที่อาจได้รับผลกระทบจากผลลัพธ์ของแอปพลิเคชันของคุณ ซึ่งอาจทำได้หลายรูปแบบ เช่น การวิจัยการศึกษาที่ทันสมัยในโดเมนแอปของคุณ การสังเกตวิธีที่ผู้คนใช้แอปที่คล้ายกัน หรือการศึกษาผู้ใช้ การสำรวจ หรือการสัมภาษณ์แบบไม่เป็นทางการกับผู้ใช้ที่มีศักยภาพ
เคล็ดลับขั้นสูง
- พูดคุยกับผู้ใช้ที่มีโอกาสเป็นลูกค้าหลากหลายกลุ่มภายในกลุ่มเป้าหมายเกี่ยวกับแอปพลิเคชันและวัตถุประสงค์ที่ตั้งใจไว้ เพื่อให้ได้มุมมองที่กว้างขึ้นเกี่ยวกับความเสี่ยงที่อาจเกิดขึ้น และปรับเกณฑ์ความหลากหลายตามความจำเป็น
- กรอบการจัดการความเสี่ยงของ AI ที่เผยแพร่โดยสถาบันมาตรฐานและเทคโนโลยีแห่งชาติ (NIST) ของรัฐบาลสหรัฐอเมริกาให้คำแนะนำโดยละเอียดเพิ่มเติม และแหล่งข้อมูลการเรียนรู้เพิ่มเติมสำหรับการจัดการความเสี่ยงของ AI
- สิ่งพิมพ์ของ DeepMind เกี่ยวกับ ความเสี่ยงด้านจริยธรรมและสังคมที่เกิดจากอันตรายจากโมเดลภาษา อธิบายโดยละเอียดถึงวิธีที่แอปพลิเคชันโมเดลภาษา อาจก่อให้เกิดอันตราย
พิจารณาการปรับเพื่อลดความเสี่ยงด้านความปลอดภัยและความถูกต้อง
ตอนนี้คุณเข้าใจความเสี่ยงแล้ว คุณสามารถตัดสินใจวิธีลดความเสี่ยงได้ การพิจารณาว่าควรจัดลำดับความสำคัญของความเสี่ยงใดและควรทำมากน้อยเพียงใดเพื่อพยายามป้องกันความเสี่ยงเหล่านั้นถือเป็นการตัดสินใจที่สำคัญ เช่นเดียวกับการจัดลำดับความสำคัญของข้อบกพร่องในโปรเจ็กต์ซอฟต์แวร์ เมื่อกำหนดลำดับความสำคัญแล้ว คุณจะเริ่มคิดถึงประเภทของการลดความเสี่ยงที่เหมาะสมที่สุดได้ การเปลี่ยนแปลงง่ายๆ มักจะสร้างความแตกต่างและลดความเสี่ยงได้
ตัวอย่างเช่น เมื่อออกแบบแอปพลิเคชัน ให้พิจารณาสิ่งต่อไปนี้
- การปรับเอาต์พุตโมเดลให้สะท้อนถึงสิ่งที่ยอมรับได้ในบริบทของแอปพลิเคชันของคุณได้ดียิ่งขึ้น การปรับแต่งจะช่วยให้เอาต์พุตโมเดลคาดการณ์ได้มากขึ้นและสอดคล้องกันมากขึ้น จึงช่วยลดความเสี่ยงบางอย่างได้
- จัดหาวิธีการป้อนข้อมูลที่ช่วยให้ได้ผลลัพธ์ที่ปลอดภัยยิ่งขึ้น อินพุตที่แน่นอนที่คุณป้อนให้กับ LLM อาจส่งผลต่อคุณภาพของเอาต์พุตได้ การทดลองใช้พรอมต์อินพุตเพื่อค้นหาสิ่งที่ทำงานได้อย่างปลอดภัยที่สุดในกรณีการใช้งานของคุณนั้นคุ้มค่ากับความพยายาม เนื่องจากคุณจะสามารถมอบ UX ที่อำนวยความสะดวกได้ ตัวอย่างเช่น คุณอาจจำกัดให้ผู้ใช้เลือกได้เฉพาะจากรายการพรอมต์อินพุตแบบเลื่อนลง หรือเสนอคำแนะนำแบบป๊อปอัปพร้อมวลีอธิบายที่คุณพบว่าทำงานได้อย่างปลอดภัยในบริบทของแอปพลิเคชัน
การบล็อกอินพุตที่ไม่ปลอดภัยและการกรองเอาต์พุตก่อนที่จะแสดงต่อผู้ใช้ ในสถานการณ์ที่ไม่ซับซ้อน คุณสามารถใช้รายการที่ถูกบล็อกเพื่อระบุและบล็อกคำหรือวลีที่ไม่ปลอดภัยในพรอมต์หรือคำตอบ หรือกำหนดให้ผู้ตรวจสอบที่เป็นมนุษย์แก้ไขหรือบล็อกเนื้อหาดังกล่าวด้วยตนเอง
ใช้ตัวแยกประเภทที่ได้รับการฝึกมาเพื่อติดป้ายกำกับแต่ละพรอมต์ด้วยอันตรายที่อาจเกิดขึ้นหรือ สัญญาณที่เป็นการต่อต้าน จากนั้นจึงใช้กลยุทธ์ต่างๆ เกี่ยวกับวิธี จัดการคำขอตามประเภทของอันตรายที่ตรวจพบได้ ตัวอย่างเช่น หาก อินพุตเป็นการต่อต้านหรือเป็นการละเมิดอย่างโจ่งแจ้ง ระบบอาจบล็อกอินพุตนั้นและ แสดงผลการตอบกลับที่เขียนสคริปต์ไว้ล่วงหน้าแทน เคล็ดลับขั้นสูง: หากสัญญาณระบุว่าเอาต์พุตเป็นอันตราย แอปพลิเคชันจะใช้ตัวเลือกต่อไปนี้ได้
- ระบุข้อความแสดงข้อผิดพลาดหรือเอาต์พุตที่เขียนสคริปต์ไว้ล่วงหน้า
- ลองใช้พรอมต์อีกครั้งในกรณีที่ระบบสร้างเอาต์พุตที่ปลอดภัยอื่น เนื่องจากบางครั้งพรอมต์เดียวกันจะทำให้เกิดเอาต์พุตที่แตกต่างกัน
การใช้มาตรการป้องกันการละเมิดโดยเจตนา เช่น การกำหนดรหัสที่ไม่ซ้ำกันให้ผู้ใช้แต่ละรายและการกำหนดขีดจำกัดปริมาณคำค้นหาของผู้ใช้ ที่ส่งได้ในช่วงเวลาที่กำหนด มาตรการป้องกันอีกอย่างคือการพยายาม ป้องกันการแทรกพรอมต์ที่อาจเกิดขึ้น การแทรกพรอมต์ก็เหมือนกับการแทรก SQL ตรงที่ผู้ใช้ที่เป็นอันตรายสามารถออกแบบพรอมต์อินพุตที่ บิดเบือนเอาต์พุตของโมเดลได้ เช่น โดยการส่งพรอมต์อินพุต ที่สั่งให้โมเดลไม่สนใจตัวอย่างก่อนหน้า ดูรายละเอียดเกี่ยวกับการละเมิดโดยเจตนาได้ที่นโยบายการใช้งานที่ไม่อนุญาตสำหรับ Generative AI
ปรับฟังก์ชันการทำงานให้มีความเสี่ยงต่ำโดยธรรมชาติ โดยทั่วไปแล้ว งานที่มีขอบเขตแคบกว่า (เช่น การแยกคีย์เวิร์ดจากข้อความ) หรือมีการกำกับดูแลจากมนุษย์มากกว่า (เช่น การสร้างเนื้อหาสั้นที่จะได้รับการตรวจสอบจากมนุษย์) มักมีความเสี่ยงต่ำกว่า เช่น แทนที่จะสร้างแอปพลิเคชันเพื่อเขียนการตอบอีเมลตั้งแต่ต้น คุณอาจจำกัดให้แอปพลิเคชันขยายโครงร่างหรือแนะนำการเรียบเรียงคำใหม่แทน
การปรับการตั้งค่าความปลอดภัยของเนื้อหาที่เป็นอันตรายเพื่อลดโอกาสที่คุณจะเห็นคำตอบที่อาจเป็นอันตราย Gemini API มีการตั้งค่าความปลอดภัยที่คุณปรับได้ในขั้นตอนการสร้างต้นแบบเพื่อพิจารณาว่าแอปพลิเคชันของคุณต้องมีการกำหนดค่าความปลอดภัยที่เข้มงวดมากขึ้นหรือน้อยลง คุณสามารถปรับการตั้งค่าเหล่านี้ในหมวดหมู่ตัวกรอง 5 หมวดหมู่เพื่อจำกัดหรืออนุญาตเนื้อหาบางประเภท โปรดดูคู่มือการตั้งค่าความปลอดภัยเพื่อดูข้อมูลเกี่ยวกับการตั้งค่าความปลอดภัยที่ปรับได้ซึ่งพร้อมใช้งานผ่าน Gemini API
ลดโอกาสที่อาจเกิดข้อเท็จจริงที่ไม่ถูกต้องหรืออาการหลอนของ AI โดยการเปิดใช้การเชื่อมต่อแหล่งข้อมูลกับ Google Search โปรดทราบว่าโมเดล AI หลายๆ โมเดลยังอยู่ในขั้นทดลองและอาจแสดงข้อมูลที่ไม่ถูกต้องตามข้อเท็จจริง เกิดอาการหลอน หรือสร้างผลลัพธ์ที่อาจเป็นปัญหา ฟีเจอร์การเชื่อมต่อแหล่งข้อมูลกับ Google Search จะเชื่อมต่อโมเดล Gemini กับเนื้อหาเว็บแบบเรียลไทม์และจะใช้งานได้กับทุกภาษาที่มี ซึ่งจะช่วยให้ Gemini สามารถให้คำตอบที่แม่นยำยิ่งขึ้นและอ้างอิงแหล่งที่มาที่ตรวจสอบได้นอกเหนือจากขีดจำกัดความรู้ของโมเดล
ทำการทดสอบความปลอดภัยที่เหมาะสมกับกรณีการใช้งานของคุณ
การทดสอบเป็นส่วนสำคัญในการสร้างแอปพลิเคชันที่แข็งแกร่งและปลอดภัย แต่ขอบเขต และกลยุทธ์ในการทดสอบจะแตกต่างกันไป ตัวอย่างเช่น ไฮกุที่สร้างขึ้นเพื่อความสนุกสนาน อาจมีความเสี่ยงน้อยกว่าแอปพลิเคชันที่ออกแบบมา สำหรับบริษัทกฎหมายเพื่อสรุปเอกสารทางกฎหมายและช่วยร่างสัญญา แต่ผู้ใช้จำนวนมากขึ้นอาจใช้โปรแกรมสร้างไฮกุ ซึ่งหมายความว่าอาจมีโอกาสมากขึ้นที่จะเกิดความพยายามที่เป็นการต่อต้านหรือแม้แต่การป้อนข้อมูลที่เป็นอันตรายโดยไม่ตั้งใจ บริบทของการติดตั้งใช้งานก็มีความสำคัญเช่นกัน เช่น แอปพลิเคชัน ที่มีเอาต์พุตซึ่งได้รับการตรวจสอบจากผู้เชี่ยวชาญก่อนที่จะมีการดำเนินการใดๆ อาจถือว่ามีแนวโน้มที่จะสร้างเอาต์พุตที่เป็นอันตรายน้อยกว่าแอปพลิเคชัน ที่เหมือนกันแต่ไม่มีการกำกับดูแลดังกล่าว
การเปลี่ยนแปลงและการทดสอบหลายครั้งก่อนที่จะมั่นใจว่าพร้อมเปิดตัวเป็นเรื่องปกติ แม้แต่สำหรับแอปพลิเคชันที่มีความเสี่ยงค่อนข้างต่ำ การทดสอบ 2 ประเภทมีประโยชน์อย่างยิ่งสำหรับแอปพลิเคชัน AI
การเปรียบเทียบความปลอดภัยเกี่ยวข้องกับการออกแบบเมตริกความปลอดภัยที่แสดงถึง วิธีที่แอปพลิเคชันของคุณอาจไม่ปลอดภัยในบริบทของวิธีที่น่าจะ มีการใช้งาน จากนั้นทดสอบประสิทธิภาพของแอปพลิเคชันในเมตริก โดยใช้ชุดข้อมูลการประเมิน แนวทางปฏิบัติแนะนำคือการพิจารณาระดับต่ำสุดที่ยอมรับได้ของเมตริกความปลอดภัยก่อนทำการทดสอบ เพื่อให้ 1) คุณประเมินผลการทดสอบเทียบกับความคาดหวังเหล่านั้นได้ และ 2) คุณรวบรวมชุดข้อมูลการประเมินตามการทดสอบที่ประเมินเมตริกที่คุณสนใจมากที่สุดได้
เคล็ดลับขั้นสูง:
- โปรดระวังการพึ่งพาแนวทาง "สำเร็จรูป" มากเกินไป เนื่องจากคุณอาจต้องสร้างชุดข้อมูลการทดสอบของคุณเองโดยใช้ผู้ให้คะแนนที่เป็นมนุษย์เพื่อให้เหมาะกับบริบทของแอปพลิเคชันอย่างเต็มที่
- หากมีเมตริกมากกว่า 1 รายการ คุณจะต้องตัดสินใจว่าจะ แลกเปลี่ยนอย่างไรหากการเปลี่ยนแปลงทําให้เมตริกหนึ่งดีขึ้น แต่ทําให้เมตริกอื่นแย่ลง เช่นเดียวกับการเพิ่มประสิทธิภาพอื่นๆ คุณอาจต้องการมุ่งเน้นที่ประสิทธิภาพในกรณีที่แย่ที่สุดในชุด การประเมินมากกว่าประสิทธิภาพโดยเฉลี่ย
การทดสอบแบบ Adversarial เกี่ยวข้องกับการพยายามทำลายแอปพลิเคชันของคุณอย่างเชิงรุก เป้าหมายคือการระบุจุดอ่อนเพื่อให้คุณสามารถดำเนินการแก้ไขได้ตามความเหมาะสม การทดสอบแบบ Adversarial อาจต้องใช้เวลา/ความพยายามอย่างมากจากผู้ประเมินที่มีความเชี่ยวชาญในแอปพลิเคชันของคุณ แต่ยิ่งคุณทำมากเท่าใด โอกาสในการพบปัญหาจะยิ่งมากขึ้น โดยเฉพาะปัญหาที่เกิดขึ้นไม่บ่อยนักหรือเกิดขึ้นหลังจากเรียกใช้แอปพลิเคชันซ้ำๆ เท่านั้น
- การทดสอบการจำลองปัญหาเป็นวิธีการประเมินโมเดล ML อย่างเป็นระบบโดยมีจุดประสงค์เพื่อเรียนรู้ลักษณะการทำงานของโมเดลเมื่อได้รับอินพุตที่เป็นอันตรายหรือก่อให้เกิดอันตรายโดยไม่ตั้งใจ
- อินพุตอาจเป็นอันตรายเมื่อได้รับการออกแบบอย่างชัดเจนเพื่อ สร้างเอาต์พุตที่ไม่ปลอดภัยหรือเป็นอันตราย เช่น การขอให้โมเดล การสร้างข้อความสร้างข้อความระบายความเกลียดชังเกี่ยวกับศาสนาใดศาสนาหนึ่ง
- อินพุตที่ก่อให้เกิดอันตรายโดยไม่ตั้งใจคืออินพุตที่อาจดู ไม่เป็นอันตราย แต่สร้างเอาต์พุตที่เป็นอันตราย เช่น การขอให้โมเดล การสร้างข้อความอธิบายบุคคลที่มีเชื้อชาติหนึ่งๆ แล้ว ได้รับเอาต์พุตที่เหยียดเชื้อชาติ
สิ่งที่ทำให้การทดสอบแบบ Adversarial แตกต่างจากการประเมินมาตรฐานคือองค์ประกอบของข้อมูลที่ใช้ในการทดสอบ สำหรับการทดสอบแบบ Adversarial ให้เลือกข้อมูลทดสอบที่มีแนวโน้มมากที่สุดที่จะกระตุ้นให้โมเดลแสดงผลลัพธ์ที่เป็นปัญหา ซึ่งหมายถึงการตรวจสอบลักษณะการทำงานของโมเดลสำหรับความเสี่ยงทุกประเภทที่อาจเกิดขึ้น รวมถึงตัวอย่างที่หายากหรือผิดปกติ และกรณีที่ขอบที่เกี่ยวข้องกับนโยบายด้านความปลอดภัย นอกจากนี้ ควรมีการพิจารณาความหลากหลายในมิติต่างๆ ของประโยค เช่น โครงสร้าง ความหมาย และความยาว คุณสามารถดูรายละเอียดเพิ่มเติมเกี่ยวกับสิ่งที่ควรพิจารณาเมื่อสร้างชุดข้อมูลทดสอบได้ในแนวทางปฏิบัติเกี่ยวกับ AI อย่างมีความรับผิดชอบของ Google ในเรื่องความเป็นธรรม เคล็ดลับขั้นสูง:
ใช้การทดสอบอัตโนมัติ แทนวิธีการแบบเดิมที่ต้องขอให้ผู้คนใน "ทีมสีแดง" มาลองเจาะแอปพลิเคชันของคุณ ในการทดสอบอัตโนมัติ "ทีมสีแดง" คือโมเดลภาษาอีกโมเดลหนึ่งที่ค้นหาข้อความอินพุต ซึ่งกระตุ้นให้โมเดลที่กำลังทดสอบสร้างเอาต์พุตที่เป็นอันตราย
- การทดสอบการจำลองปัญหาเป็นวิธีการประเมินโมเดล ML อย่างเป็นระบบโดยมีจุดประสงค์เพื่อเรียนรู้ลักษณะการทำงานของโมเดลเมื่อได้รับอินพุตที่เป็นอันตรายหรือก่อให้เกิดอันตรายโดยไม่ตั้งใจ
ตรวจสอบปัญหา
ไม่ว่าคุณจะทดสอบและลดความเสี่ยงมากเพียงใด ก็ไม่สามารถรับประกันได้ว่าจะไม่มีข้อบกพร่อง ดังนั้น โปรดวางแผนล่วงหน้าว่าจะระบุและจัดการกับปัญหาที่เกิดขึ้นอย่างไร แนวทางที่ใช้กันโดยทั่วไป ได้แก่ การตั้งค่าช่องที่ตรวจสอบเพื่อให้ผู้ใช้แชร์ความคิดเห็น (เช่น การให้คะแนนด้วยการกดชอบ/ไม่ชอบ) และการทําการศึกษาวิจัยผู้ใช้เพื่อขอความคิดเห็น จากผู้ใช้ที่หลากหลายอย่างเชิงรุก ซึ่งจะมีประโยชน์อย่างยิ่งหากรูปแบบการใช้งาน แตกต่างจากที่คาดไว้
เคล็ดลับขั้นสูง
- เมื่อผู้ใช้แสดงความคิดเห็นเกี่ยวกับผลิตภัณฑ์ AI ก็จะช่วยปรับปรุงประสิทธิภาพของ AI และประสบการณ์การใช้งานของผู้ใช้ได้อย่างมากเมื่อเวลาผ่านไป เช่น ช่วยคุณเลือกตัวอย่างที่ดีขึ้นสำหรับการปรับพรอมต์ บทที่ว่าด้วยความคิดเห็นและการควบคุม ในคู่มือเกี่ยวกับผู้คนและ AI ของ Google เน้นย้ำข้อควรพิจารณาที่สำคัญเมื่อออกแบบ กลไกการแสดงความคิดเห็น
ขั้นตอนถัดไป
- โปรดดูคู่มือการตั้งค่าความปลอดภัยเพื่อดูข้อมูลเกี่ยวกับการตั้งค่าความปลอดภัยที่ปรับได้ ซึ่งมีให้ใช้งานผ่าน Gemini API
- ดูข้อมูลเบื้องต้นเกี่ยวกับการแจ้งเพื่อเริ่มเขียนพรอมต์แรก