
Zadanie MediaPipe Gesture Recognizer umożliwia rozpoznawanie gestów dłoni w czasie rzeczywistym. Wyniki rozpoznawania gestów dłoni oraz punkty orientacyjne dłoni wykrywanych dłoni. Z tych instrukcji dowiesz się, jak używać rozpoznawania gestów w przypadku aplikacji w Pythonie.
Aby zobaczyć, jak to zadanie działa w praktyce, obejrzyj prezentację internetową. Więcej informacji o możliwościach, modelach i opcjach konfiguracji tego zadania znajdziesz w omówieniu.
Przykładowy kod
Przykładowy kod dla usługi rozpoznawania gestów zawiera kompletną implementację tego zadania w języku Python. Ten kod pomoże Ci przetestować to zadanie i zacząć tworzyć własny rozpoznawacz gestów dłoni. Możesz wyświetlać, uruchamiać i edytować przykładowy kod rozpoznawania gestów, korzystając tylko z przeglądarki.
Jeśli wdrażasz rozpoznawanie gestów na Raspberry Pi, zapoznaj się z przykładową aplikacją na Raspberry Pi.
Konfiguracja
W tej sekcji opisaliśmy kluczowe kroki konfigurowania środowiska programistycznego i projektów kodu w celu używania rozpoznawania gestów. Ogólne informacje o konfigurowaniu środowiska programistycznego na potrzeby korzystania z zadań MediaPipe, w tym wymagania dotyczące wersji platformy, znajdziesz w przewodniku po konfigurowaniu Pythona.
Pakiety
Zadanie Wykrywanie gestów za pomocą MediaPipe wymaga pakietu mediapipe z PyPI. Te zależności możesz zainstalować i zaimportować za pomocą:
$ python -m pip install mediapipe
Importy
Aby uzyskać dostęp do funkcji zadania rozpoznawania gestów, zaimportuj te klasy:
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
Model
Zadanie MediaPipe Gesture Recognizer wymaga pakietu wytrenowanych modeli, który jest zgodny z tym zadaniem. Więcej informacji o dostępnych wytrenowanych modelach dla rozpoznawania gestów znajdziesz w sekcji Modele w omówieniu zadania.
Wybierz i pobierz model, a potem zapisz go w katalogu lokalnym:
model_path = '/absolute/path/to/gesture_recognizer.task'
W parametrze Nazwa modelu określ ścieżkę do modelu, jak pokazano poniżej:
base_options = BaseOptions(model_asset_path=model_path)
Tworzenie zadania
Do konfiguracji zadania MediaPipe Gesture Recognizer służy funkcja create_from_options. Funkcja create_from_options przyjmuje wartości opcji konfiguracji, które mają być obsługiwane. Więcej informacji o opcjach konfiguracji znajdziesz w artykule Opcje konfiguracji.
Poniższy kod pokazuje, jak skompilować i skonfigurować to zadanie.
Te przykłady pokazują też różne sposoby tworzenia zadań dotyczące obrazów, plików wideo i transmisji wideo na żywo.
Obraz
import mediapipe as mp BaseOptions = mp.tasks.BaseOptions GestureRecognizer = mp.tasks.vision.GestureRecognizer GestureRecognizerOptions = mp.tasks.vision.GestureRecognizerOptions VisionRunningMode = mp.tasks.vision.RunningMode # Create a gesture recognizer instance with the image mode: options = GestureRecognizerOptions( base_options=BaseOptions(model_asset_path='/path/to/model.task'), running_mode=VisionRunningMode.IMAGE) with GestureRecognizer.create_from_options(options) as recognizer: # The detector is initialized. Use it here. # ...
Wideo
import mediapipe as mp BaseOptions = mp.tasks.BaseOptions GestureRecognizer = mp.tasks.vision.GestureRecognizer GestureRecognizerOptions = mp.tasks.vision.GestureRecognizerOptions VisionRunningMode = mp.tasks.vision.RunningMode # Create a gesture recognizer instance with the video mode: options = GestureRecognizerOptions( base_options=BaseOptions(model_asset_path='/path/to/model.task'), running_mode=VisionRunningMode.VIDEO) with GestureRecognizer.create_from_options(options) as recognizer: # The detector is initialized. Use it here. # ...
Transmisja na żywo
import mediapipe as mp BaseOptions = mp.tasks.BaseOptions GestureRecognizer = mp.tasks.vision.GestureRecognizer GestureRecognizerOptions = mp.tasks.vision.GestureRecognizerOptions GestureRecognizerResult = mp.tasks.vision.GestureRecognizerResult VisionRunningMode = mp.tasks.vision.RunningMode # Create a gesture recognizer instance with the live stream mode: def print_result(result: GestureRecognizerResult, output_image: mp.Image, timestamp_ms: int): print('gesture recognition result: {}'.format(result)) options = GestureRecognizerOptions( base_options=BaseOptions(model_asset_path='/path/to/model.task'), running_mode=VisionRunningMode.LIVE_STREAM, result_callback=print_result) with GestureRecognizer.create_from_options(options) as recognizer: # The detector is initialized. Use it here. # ...
Opcje konfiguracji
W tym zadaniu dostępne są te opcje konfiguracji aplikacji Pythona:
| Nazwa opcji | Opis | Zakres wartości | Wartość domyślna | |
|---|---|---|---|---|
running_mode |
Ustawia tryb działania zadania. Dostępne są 3 tryby: OBRAZ: tryb dla pojedynczych obrazów wejściowych. FILM: tryb dekodowanych klatek filmu. LIVE_STREAM: tryb transmisji na żywo danych wejściowych, takich jak dane z kamery. W tym trybie należy wywołać metodę resultListener, aby skonfigurować odbiornik, który będzie asynchronicznie odbierał wyniki. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
|
num_hands |
Maksymalna liczba dłoni, które może wykryć GestureRecognizer, to
|
Any integer > 0 |
1 |
|
min_hand_detection_confidence |
Minimalny wynik ufności wykrywania dłoni, który jest uznawany za udany w przypadku modelu wykrywania dłoni. | 0.0 - 1.0 |
0.5 |
|
min_hand_presence_confidence |
Minimalny wynik ufności obecności ręki w modelu wykrywania punktów orientacyjnych ręki. W trybie wideo i w trybie transmisji na żywo usługi rozpoznawania gestów, jeśli wskaźnik ufności obecności ręki z modelu punktów orientacyjnych ręki jest poniżej tego progu, uruchamia model wykrywania dłoni. W przeciwnym razie do określenia lokalizacji dłoni(dłoni) w celu wykrywania punktów orientacyjnych używany jest lekki algorytm śledzenia dłoni. | 0.0 - 1.0 |
0.5 |
|
min_tracking_confidence |
Minimalny wynik ufności śledzenia dłoni, który jest uznawany za udany. To próg współczynnika podobieństwa ramki ograniczającej między dłońmi w bieżącej i ostatniej ramie. W trybie wideo i strumień w rozpoznawaniu gestów, jeśli śledzenie zawiedzie, rozpoznawanie gestów uruchamia wykrywanie ręki. W przeciwnym razie wykrywanie dłoni zostanie pominięte. | 0.0 - 1.0 |
0.5 |
|
canned_gestures_classifier_options |
Opcje konfiguracji zachowania klasyfikatora gotowych gestów. Gotowe gesty: ["None", "Closed_Fist", "Open_Palm", "Pointing_Up", "Thumb_Down", "Thumb_Up", "Victory", "ILoveYou"] |
|
|
|
custom_gestures_classifier_options |
Opcje konfiguracji zachowania klasyfikatora niestandardowych gestów. |
|
|
|
result_callback |
Ustawia odbiornik wyników w celu asynchronicznego otrzymywania wyników klasyfikacji, gdy rozpoznawacz gestów jest w trybie transmisji na żywo.
Można go używać tylko wtedy, gdy tryb działania ma wartość LIVE_STREAM. |
ResultListener |
Nie dotyczy | Nie dotyczy |
Przygotuj dane
Przygotuj dane wejściowe jako plik obrazu lub tablicę numpy, a potem przekonwertuj je na obiekt mediapipe.Image. Jeśli dane wejściowe to plik wideo lub transmisja na żywo z kamery internetowej, możesz użyć biblioteki zewnętrznej, takiej jak OpenCV, aby załadować ramki wejściowe jako tablice NumPy.
Obraz
import mediapipe as mp # Load the input image from an image file. mp_image = mp.Image.create_from_file('/path/to/image') # Load the input image from a numpy array. mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=numpy_image)
Wideo
import mediapipe as mp # Use OpenCV’s VideoCapture to load the input video. # Load the frame rate of the video using OpenCV’s CV_CAP_PROP_FPS # You’ll need it to calculate the timestamp for each frame. # Loop through each frame in the video using VideoCapture#read() # Convert the frame received from OpenCV to a MediaPipe’s Image object. mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=numpy_frame_from_opencv)
Transmisja na żywo
import mediapipe as mp # Use OpenCV’s VideoCapture to start capturing from the webcam. # Create a loop to read the latest frame from the camera using VideoCapture#read() # Convert the frame received from OpenCV to a MediaPipe’s Image object. mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=numpy_frame_from_opencv)
Uruchamianie zadania
Rozpoznawanie gestów używa funkcji recognize, recognize_for_video i recognize_async do wywoływania wniosków. W przypadku rozpoznawania gestów obejmuje to wstępną obróbkę danych wejściowych, wykrywanie dłoni na obrazie, wykrywanie punktów orientacyjnych dłoni oraz rozpoznawanie gestów na podstawie tych punktów.
Poniższy kod pokazuje, jak wykonać przetwarzanie za pomocą modelu zadania.
Obraz
# Perform gesture recognition on the provided single image. # The gesture recognizer must be created with the image mode. gesture_recognition_result = recognizer.recognize(mp_image)
Wideo
# Perform gesture recognition on the provided single image. # The gesture recognizer must be created with the video mode. gesture_recognition_result = recognizer.recognize_for_video(mp_image, frame_timestamp_ms)
Transmisja na żywo
# Send live image data to perform gesture recognition. # The results are accessible via the `result_callback` provided in # the `GestureRecognizerOptions` object. # The gesture recognizer must be created with the live stream mode. recognizer.recognize_async(mp_image, frame_timestamp_ms)
Pamiętaj:
- W trybie wideo lub transmisji na żywo musisz też przekazać zadaniu rozpoznawania gestów sygnaturę czasową ramki wejściowej.
- Gdy działa w ramach modelu obrazu lub wideo, zadanie rozpoznawania gestów blokuje bieżący wątek, dopóki nie zakończy przetwarzania wejściowego obrazu lub klatki.
- W trybie transmisji na żywo zadanie wykrywania gestów nie blokuje bieżącego wątku, ale zwraca natychmiast. Za każdym razem, gdy zakończy przetwarzanie ramki wejściowej, wywoła swojego słuchacza z wynikiem rozpoznawania. Jeśli funkcja rozpoznawania jest wywoływana, gdy zadanie wykrywania gestów jest zajęte przetwarzaniem innego obrazu, zadanie zignoruje nowy obraz wejściowy.
Pełny przykład uruchomienia rozpoznawania gestów na obrazie znajdziesz w przykładowym kodzie.
Obsługa i wyświetlanie wyników
Moduł rozpoznawania gestów generuje obiekt wyników wykrywania gestów dla każdego przebiegu rozpoznawania. Obiekt wyniku zawiera punkty orientacyjne dłoni w współrzędnych obrazu, punkty orientacyjne dłoni w współrzędnych świata, rękę dominującą(lewa/prawa) oraz kategorie gestów wykrytych rąk.
Poniżej znajdziesz przykład danych wyjściowych z tego zadania:
Wynik GestureRecognizerResult zawiera 4 komponenty, z których każdy jest tablicą, a każdy element zawiera wykryty wynik dla jednej wykrytej ręki.
Ręka dominująca
Ręka określa, czy wykryta ręka jest lewą czy prawą.
Gesty
Kategorie gestów wykryte w wykrytych rękach.
Punkty orientacyjne
Jest 21 punktów orientacyjnych dłoni, z których każdy składa się ze współrzędnych
x,yiz. współrzędnexiysą normalizowane do zakresu [0,0, 1,0] odpowiednio według szerokości i wysokości obrazu; Współrzędnazreprezentuje głębokość punktu orientacyjnego, przy czym punktem wyjścia jest głębokość na wysokości nadgarstka. Im mniejsza wartość, tym obiektyw jest bliżej zabytku. Wielkośćzużywa mniej więcej tej samej skali cox.Punkty orientacyjne na świecie
21 punktów orientacyjnych dłoni jest też przedstawionych w współrzędnych światowych. Każdy punkt orientacyjny składa się z wartości
x,yiz, które reprezentują rzeczywiste współrzędne 3D w metrach z początkiem w geometrycznym środku dłoni.
GestureRecognizerResult:
Handedness:
Categories #0:
index : 0
score : 0.98396
categoryName : Left
Gestures:
Categories #0:
score : 0.76893
categoryName : Thumb_Up
Landmarks:
Landmark #0:
x : 0.638852
y : 0.671197
z : -3.41E-7
Landmark #1:
x : 0.634599
y : 0.536441
z : -0.06984
... (21 landmarks for a hand)
WorldLandmarks:
Landmark #0:
x : 0.067485
y : 0.031084
z : 0.055223
Landmark #1:
x : 0.063209
y : -0.00382
z : 0.020920
... (21 world landmarks for a hand)
Na tych obrazach widać wizualizację danych wyjściowych zadania:
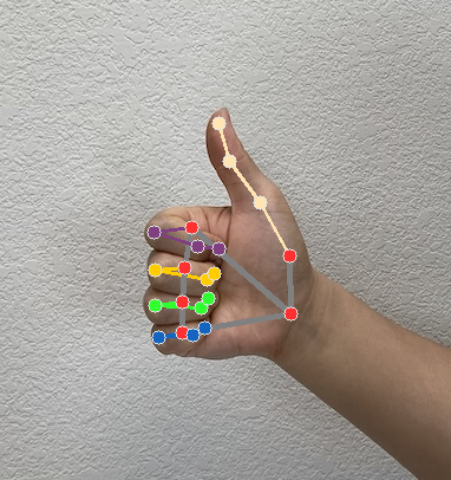
Przykładowy kod usługi rozpoznawania gestów pokazuje, jak wyświetlać wyniki rozpoznawania zwrócone przez zadanie. Więcej informacji znajdziesz w przykładowym kodzie.