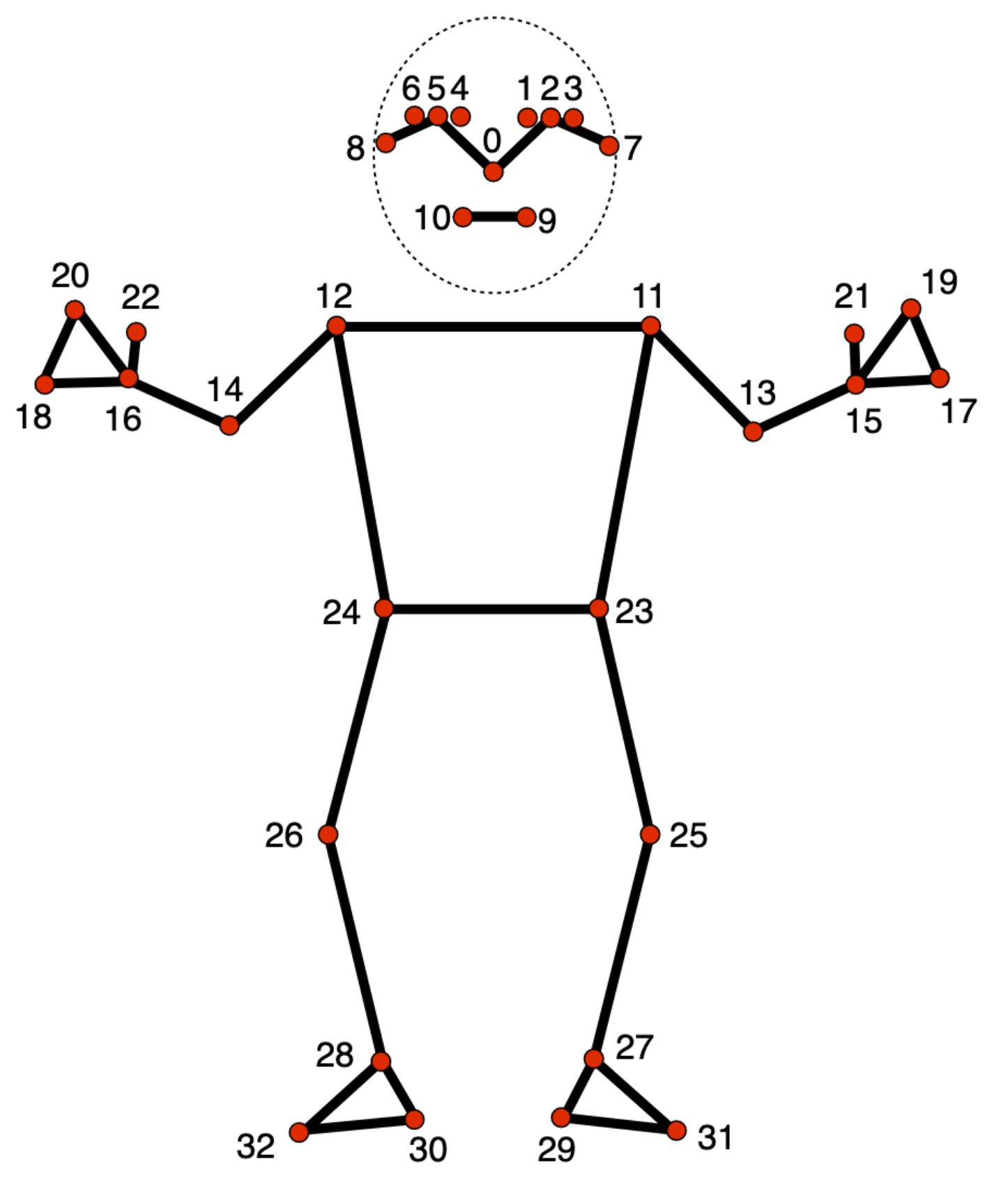
وظیفه MediaPipe Pose Landmarker به شما امکان می دهد نشانه های بدن انسان را در یک تصویر یا ویدیو تشخیص دهید. شما می توانید از این کار برای شناسایی مکان های کلیدی بدن، تجزیه و تحلیل وضعیت بدن و دسته بندی حرکات استفاده کنید. این کار از مدلهای یادگیری ماشینی (ML) استفاده میکند که با تصاویر یا ویدیوهای منفرد کار میکنند. وظیفه خروجی نقاط عطف ژست بدن در مختصات تصویر و در مختصات جهان سه بعدی است.
شروع کنید
استفاده از این کار را با دنبال کردن راهنمای پیاده سازی پلت فرم مورد نظر خود شروع کنید. این راهنماهای مخصوص پلتفرم شما را از طریق اجرای اساسی این کار، از جمله یک مدل توصیه شده، و نمونه کد با گزینه های پیکربندی توصیه شده، راهنمایی می کنند:
جزئیات کار
این بخش قابلیت ها، ورودی ها، خروجی ها و گزینه های پیکربندی این کار را شرح می دهد.
ویژگی ها
- پردازش تصویر ورودی - پردازش شامل چرخش تصویر، تغییر اندازه، عادی سازی و تبدیل فضای رنگی است.
- آستانه امتیاز - نتایج را بر اساس نمرات پیش بینی فیلتر کنید.
| ورودی های وظیفه | خروجی های وظیفه |
|---|---|
Pose Landmarker ورودی یکی از انواع داده های زیر را می پذیرد:
| Pose Landmarker نتایج زیر را به دست می دهد:
|
گزینه های پیکربندی
این کار دارای گزینه های پیکربندی زیر است:
| نام گزینه | توضیحات | محدوده ارزش | مقدار پیش فرض |
|---|---|---|---|
running_mode | حالت اجرا را برای کار تنظیم می کند. سه حالت وجود دارد: IMAGE: حالت برای ورودی های تک تصویر. VIDEO: حالت برای فریم های رمزگشایی شده یک ویدیو. LIVE_STREAM: حالت پخش زنده داده های ورودی، مانند دوربین. در این حالت، resultListener باید فراخوانی شود تا شنونده ای را برای دریافت نتایج به صورت ناهمزمان تنظیم کند. | { IMAGE, VIDEO, LIVE_STREAM } | IMAGE |
num_poses | حداکثر تعداد پوزی که می تواند توسط Pose Landmarker شناسایی شود. | Integer > 0 | 1 |
min_pose_detection_confidence | حداقل امتیاز اطمینان برای تشخیص پوس موفق در نظر گرفته شود. | Float [0.0,1.0] | 0.5 |
min_pose_presence_confidence | حداقل امتیاز اطمینان امتیاز حضور پوز در تشخیص نقطه عطف پوس. | Float [0.0,1.0] | 0.5 |
min_tracking_confidence | حداقل امتیاز اطمینان برای ردیابی ژست موفقیت آمیز در نظر گرفته شود. | Float [0.0,1.0] | 0.5 |
output_segmentation_masks | آیا Pose Landmarker یک ماسک تقسیمبندی را برای ژست شناسایی شده خروجی میدهد یا خیر. | Boolean | False |
result_callback | شنونده نتیجه را طوری تنظیم می کند که وقتی Pose Landmarker در حالت پخش زنده است، نتایج نشانگر را به صورت ناهمزمان دریافت کند. فقط زمانی قابل استفاده است که حالت اجرا روی LIVE_STREAM تنظیم شده باشد | ResultListener | N/A |
مدل ها
Pose Landmarker از مجموعه ای از مدل ها برای پیش بینی نشانه های ژست استفاده می کند. مدل اول حضور اجساد انسان را در یک قاب تصویر تشخیص می دهد و مدل دوم نقاط عطف را بر روی اجساد مشخص می کند.
مدل های زیر با هم در یک بسته مدل قابل دانلود بسته بندی می شوند:
- مدل تشخیص پوس : وجود اجساد را با چند نشانه کلیدی تشخیص می دهد.
- Pose Landmarker Model : یک نقشه کامل از ژست اضافه می کند. این مدل تخمینی از 33 نشانه 3 بعدی را ارائه می دهد.
این بسته از یک شبکه عصبی کانولوشنال مشابه MobileNetV2 استفاده میکند و برای برنامههای تناسب اندام روی دستگاه و در زمان واقعی بهینه شده است. این نوع از مدل BlazePose از GHUM ، یک خط لوله مدلسازی شکل انسان سه بعدی، برای تخمین وضعیت بدن سه بعدی کامل یک فرد در تصاویر یا ویدیوها استفاده میکند.
| بسته مدل | شکل ورودی | نوع داده | کارت های مدل | نسخه ها |
|---|---|---|---|---|
| نشانگر ژست (لایت) | آشکارساز پوس: 224 x 224 x 3 نشانگر ژست: 256 x 256 x 3 | شناور 16 | اطلاعات | آخرین |
| نشانگر ژست (کامل) | آشکارساز پوس: 224 x 224 x 3 نشانگر ژست: 256 x 256 x 3 | شناور 16 | اطلاعات | آخرین |
| نشانگر ژست (سنگین) | آشکارساز پوس: 224 x 224 x 3 نشانگر ژست: 256 x 256 x 3 | شناور 16 | اطلاعات | آخرین |