
En esta guía, se proporcionan instrucciones para convertir modelos de Gemma en formato de Safetensors de Hugging Face (.safetensors) al formato de archivo de tareas de MediaPipe (.task). Esta conversión es fundamental para implementar modelos de Gemma previamente entrenados o ajustados para la inferencia en el dispositivo en Android y iOS con la API de MediaPipe LLM Inference y el tiempo de ejecución de LiteRT.

Para crear el paquete de tareas requerido (.task), usarás LiteRT Torch. Esta herramienta exporta modelos de PyTorch a modelos LiteRT (.tflite) de varias firmas, que son compatibles con la API de MediaPipe LLM Inference y adecuados para ejecutarse en backends de CPU en aplicaciones para dispositivos móviles.
El archivo .task final es un paquete autónomo que requiere MediaPipe y que incluye el modelo LiteRT, el modelo de tokenizador y los metadatos esenciales. Este paquete es necesario porque el tokenizador (que convierte las instrucciones de texto en incorporaciones de tokens para el modelo) debe empaquetarse con el modelo de LiteRT para habilitar la inferencia de extremo a extremo.
A continuación, se muestra un desglose paso a paso del proceso:
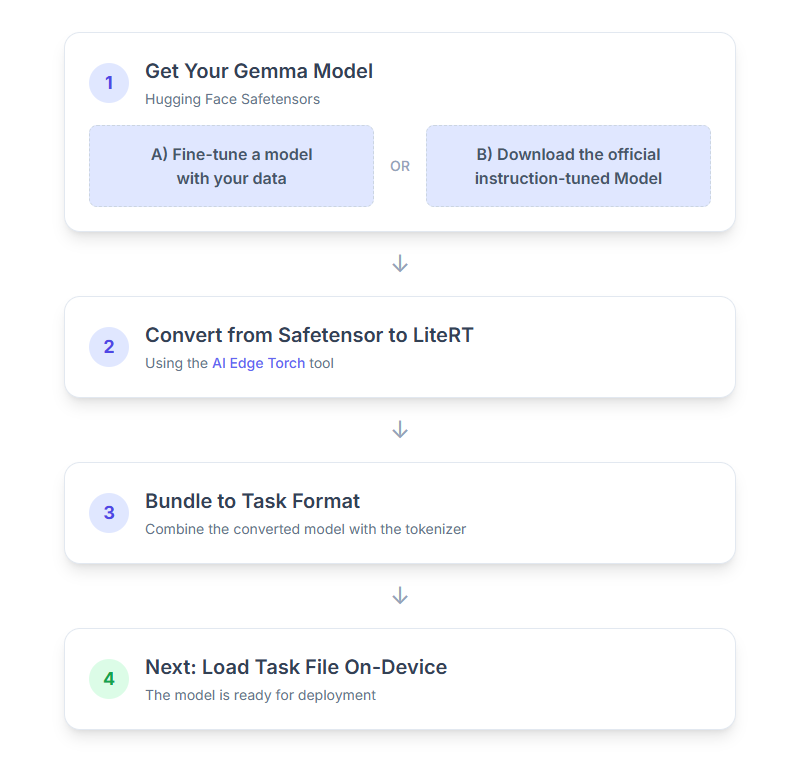
1. Obtén tu modelo de Gemma
Tienes dos opciones para comenzar.
Opción A Usa un modelo existente ajustado
Si tienes un modelo de Gemma ajustado preparado, continúa con el siguiente paso.
Opción B Descarga el modelo oficial ajustado para instrucciones
Si necesitas un modelo, puedes descargar un modelo de Gemma ajustado con instrucciones desde Hugging Face Hub.
Configura las herramientas necesarias:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
Descarga el modelo:
Los modelos en Hugging Face Hub se identifican con un ID de modelo, generalmente en el formato <organization_or_username>/<model_name>. Por ejemplo, para descargar el modelo oficial de Gemma 3 270M ajustado con instrucciones de Google, usa el siguiente comando:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. Convierte y cuantiza el modelo a LiteRT
Configura un entorno virtual de Python y, luego, instala la versión estable más reciente del paquete de LiteRT Torch:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
Usa la siguiente secuencia de comandos para convertir el modelo de Safetensor en LiteRT.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
Ten en cuenta que este proceso lleva tiempo y depende de la velocidad de procesamiento de tu computadora. Como referencia, en una CPU de 8 núcleos del 2025, un modelo de 270 M tarda entre 5 y 10 minutos, mientras que un modelo de 1 B puede tardar entre 10 y 30 minutos.
El resultado final, un modelo de LiteRT, se guardará en el OUTPUT_DIR_PATH que especificaste.
Ajusta los siguientes valores según las restricciones de memoria y rendimiento de tu dispositivo de destino.
kv_cache_max_len: Define el tamaño total asignado de la memoria de trabajo del modelo (la caché KV). Esta capacidad es un límite fijo y debe ser suficiente para almacenar la suma combinada de los tokens de la instrucción (el prellenado) y todos los tokens generados posteriormente (la decodificación).prefill_seq_len: Especifica el recuento de tokens del prompt de entrada para la división en fragmentos de precompletado. Cuando se procesa la instrucción de entrada con la fragmentación de precompletado, se considera toda la secuencia (p.ej., 50,000 tokens) no se calcula de una vez, sino que se divide en segmentos manejables (p.ej., fragmentos de 2,048 tokens) que se cargan de forma secuencial en la caché para evitar un error de memoria insuficiente.quantize: Es una cadena para los esquemas de cuantificación seleccionados. A continuación, se incluye la lista de recetas de cuantización disponibles para Gemma 3.none: Sin cuantizaciónfp16: Pesos en FP16, activaciones en FP32 y procesamiento de punto flotante para todas las operacionesdynamic_int8: Activaciones en FP32, pesos en INT8 y procesamiento de números enterosweight_only_int8: Activaciones en FP32, pesos en INT8 y cálculo de punto flotante
3. Crea un paquete de tareas a partir de LiteRT y del tokenizador
Configura un entorno virtual de Python y, luego, instala el paquete de Python de mediapipe:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
Usa la biblioteca genai.bundler para empaquetar el modelo:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
La función bundler.create_bundle crea un archivo .task que contiene toda la información necesaria para ejecutar el modelo.
4. Inferencia con MediaPipe en Android
Inicializa la tarea con opciones de configuración básicas:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
Usa el método generateResponse() para generar una respuesta de texto.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
Para transmitir la respuesta, usa el método generateResponseAsync().
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
Consulta la guía de inferencia de LLM para Android para obtener más información.
Próximos pasos
Crea y explora más con los modelos de Gemma: