
|
|
|
|
|
 Ver código fuente en GitHub Ver código fuente en GitHub
|
En esta guía, se explica cómo ajustar Gemma en un conjunto de datos de PNJ de juegos para dispositivos móviles con Transformers y TRL de Hugging Face. Aprenderás a hacer lo siguiente:
- Configura el entorno de desarrollo
- Prepara el conjunto de datos de ajuste
- Ajuste completo del modelo Gemma con TRL y SFTTrainer
- Prueba la inferencia del modelo y las verificaciones de ambiente
Configura el entorno de desarrollo
El primer paso es instalar las bibliotecas de Hugging Face, incluidas TRL y los conjuntos de datos para ajustar el modelo abierto, incluidas diferentes técnicas de RLHF y alineación.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
Nota: Si usas una GPU con arquitectura Ampere (como la NVIDIA L4) o una más reciente, puedes usar Flash attention. Flash Attention es un método que acelera significativamente los cálculos y reduce el uso de memoria de cuadrático a lineal en la longitud de la secuencia, lo que acelera el entrenamiento hasta 3 veces. Obtén más información en FlashAttention.
Antes de comenzar el entrenamiento, debes asegurarte de haber aceptado las condiciones de uso de Gemma. Para aceptar la licencia en Hugging Face, haz clic en el botón Agree and access repository en la página del modelo en: http://huggingface.co/google/gemma-3-270m-it
Después de aceptar la licencia, necesitarás un token de Hugging Face válido para acceder al modelo. Si ejecutas el código dentro de Google Colab, puedes usar tu token de Hugging Face de forma segura con los secretos de Colab. De lo contrario, puedes establecer el token directamente en el método login. Asegúrate de que tu token también tenga acceso de escritura, ya que subirás tu modelo al Hub durante el entrenamiento.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
Puedes conservar los resultados en la máquina virtual local de Colab. Sin embargo, te recomendamos que guardes los resultados intermedios en tu unidad de Google Drive. Esto garantiza que los resultados del entrenamiento sean seguros y te permite comparar y seleccionar fácilmente el mejor modelo.
from google.colab import drive
drive.mount('/content/drive')
Selecciona el modelo base para ajustar, y configura el directorio de puntos de control y la tasa de aprendizaje.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
Crea y prepara el conjunto de datos de ajuste
El conjunto de datos bebechien/MobileGameNPC proporciona una pequeña muestra de conversaciones entre un jugador y dos PNJ alienígenas (un marciano y un venusiano), cada uno con un estilo de habla único. Por ejemplo, el PNJ marciano habla con un acento que reemplaza los sonidos de la letra "s" por "z", usa "da" en lugar de "el" o "la", "diz" en lugar de "este" o "esta", y hace clics ocasionales como *k'tak*.
Este conjunto de datos demuestra un principio clave para el ajuste: el tamaño del conjunto de datos requerido depende del resultado deseado.
- Para enseñarle al modelo una variación estilística de un idioma que ya conoce, como el acento marciano, puede ser suficiente un conjunto de datos pequeño con tan solo entre 10 y 20 ejemplos.
- Sin embargo, para enseñarle al modelo un idioma alienígena completamente nuevo o mixto, se requeriría un conjunto de datos significativamente más grande.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
Optimiza Gemma con TRL y SFTTrainer
Ahora ya puedes ajustar tu modelo. El SFTTrainer de Hugging Face TRL facilita la supervisión del ajuste fino de los LLM abiertos. SFTTrainer es una subclase de Trainer de la biblioteca transformers y admite las mismas funciones.
El siguiente código carga el modelo y el tokenizador de Gemma desde Hugging Face.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
Antes del ajuste
El siguiente resultado muestra que las capacidades listas para usar pueden no ser lo suficientemente buenas para este caso de uso.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
En el ejemplo anterior, se verifica la función principal del modelo de generar diálogos en el juego. El siguiente ejemplo está diseñado para probar la coherencia del personaje. Desafiamos al modelo con una instrucción irrelevante. Por ejemplo, Sorry, you are a game NPC., que queda fuera de la base de conocimiento del personaje.
El objetivo es ver si el modelo puede mantener su personaje en lugar de responder la pregunta fuera de contexto. Esto servirá como referencia para evaluar la eficacia con la que el proceso de ajuste fino inculcó el arquetipo deseado.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
Si bien podemos usar la ingeniería de instrucciones para dirigir su tono, los resultados pueden ser impredecibles y no siempre alinearse con el arquetipo que deseamos.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
Capacitación
Antes de comenzar el entrenamiento, debes definir los hiperparámetros que deseas usar en una instancia de SFTConfig.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
Ahora tienes todos los componentes básicos que necesitas para crear tu SFTTrainer y comenzar el entrenamiento de tu modelo.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
Para comenzar el entrenamiento, llama al método train().
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
Para generar un gráfico de las pérdidas de entrenamiento y validación, normalmente extraerías estos valores del objeto TrainerState o de los registros generados durante el entrenamiento.
Luego, se pueden usar bibliotecas como Matplotlib para visualizar estos valores en los pasos o las épocas de entrenamiento. El eje X representaría los pasos o las épocas de entrenamiento, y el eje Y representaría los valores de pérdida correspondientes.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
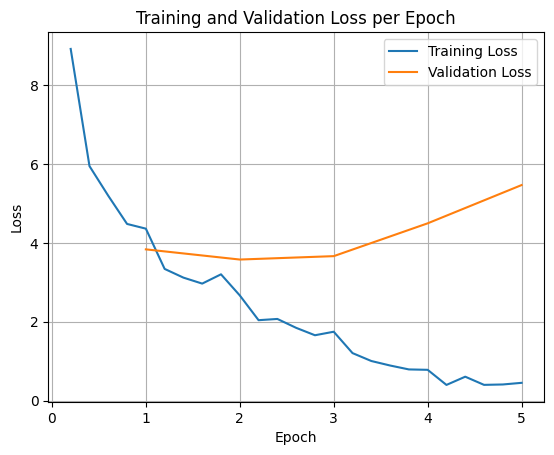
Esta visualización ayuda a supervisar el proceso de entrenamiento y a tomar decisiones fundamentadas sobre el ajuste de hiperparámetros o la detención anticipada.
La pérdida de entrenamiento mide el error en los datos con los que se entrenó el modelo, mientras que la pérdida de validación mide el error en un conjunto de datos separado que el modelo no ha visto antes. La supervisión ayuda a detectar el sobreajuste (cuando el modelo funciona bien con los datos de entrenamiento, pero mal con los datos no vistos).
- Pérdida de validación >> pérdida de entrenamiento: sobreajuste
- Pérdida de validación > pérdida de entrenamiento: Algo de sobreajuste
- Pérdida de validación < pérdida de entrenamiento: Algún subajuste
- Pérdida de validación << pérdida de entrenamiento: Ajuste insuficiente
Prueba la inferencia del modelo
Una vez que finalice el entrenamiento, querrás evaluar y probar tu modelo. Puedes cargar diferentes muestras del conjunto de datos de prueba y evaluar el modelo en esas muestras.
Para este caso de uso en particular, el mejor modelo es una cuestión de preferencia. Curiosamente, lo que normalmente llamaríamos "sobreajuste" puede ser muy útil para un PNJ de un juego. Obliga al modelo a olvidar la información general y, en cambio, enfocarse en el arquetipo y las características específicos con los que se entrenó, lo que garantiza que se mantenga constantemente en el personaje.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Carguemos todas las preguntas del conjunto de datos de prueba y generemos resultados.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
Si pruebas nuestra instrucción generalista original, verás que el modelo sigue intentando responder con el estilo con el que se entrenó. En este ejemplo, el sobreajuste y el olvido catastrófico son beneficiosos para el PNJ del juego, ya que comenzará a olvidar el conocimiento general que podría no ser aplicable. Esto también se aplica a otros tipos de ajuste fino completo en los que el objetivo es restringir el resultado a formatos de datos específicos.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
Resumen y próximos pasos
En este instructivo, se explicó cómo realizar un ajuste de modelos completo con TRL. A continuación, consulta los siguientes documentos: