
במדריך הזה מוסבר איך להמיר מודלים של Gemma בפורמט Safetensors של Hugging Face (.safetensors) לפורמט הקובץ של MediaPipe Task (.task). ההמרה הזו חיונית לפריסת מודלים של Gemma שעברו אימון מראש או כוונון עדין להסקת מסקנות במכשיר ב-Android וב-iOS באמצעות MediaPipe LLM Inference API וזמן הריצה של LiteRT.
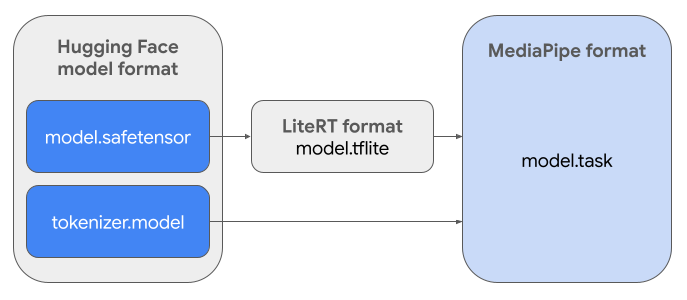
כדי ליצור את חבילת המשימות הנדרשת (.task), תשתמשו ב-LiteRT Torch. הכלי הזה מייצא מודלים של PyTorch למודלים של LiteRT (.tflite) עם חתימה מרובה, שתואמים ל-MediaPipe LLM Inference API ומתאימים להרצה ב-CPU backends באפליקציות לנייד.
קובץ ה-.task הסופי הוא חבילה עצמאית שנדרשת על ידי MediaPipe,
שכוללת את מודל LiteRT, את מודל הטוקנייזר ומטא-נתונים חיוניים. החבילה הזו נחוצה כי צריך לארוז את הטוקנייזר (שממיר הנחיות טקסט להטמעות של טוקנים עבור המודל) עם מודל LiteRT כדי לאפשר הסקה מקצה לקצה.
פירוט שלבי התהליך:
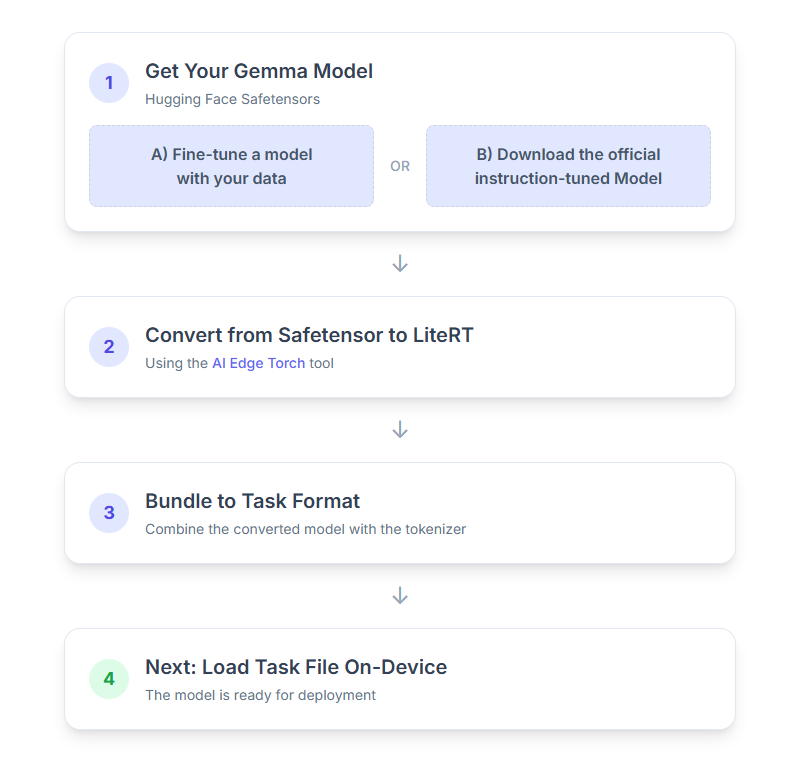
1. קבלת מודל Gemma
יש שתי דרכים להתחיל.
אפשרות א'. שימוש במודל קיים שעבר כוונון עדין
אם יש לכם מודל Gemma שעבר כוונון עדין, פשוט ממשיכים לשלב הבא.
אפשרות ב'. הורדה של מודל רשמי שעבר כוונון לפי הוראות
אם אתם צריכים מודל, אתם יכולים להוריד Gemma שעבר כוונון להוראות מ-Hugging Face Hub.
הגדרת הכלים הנדרשים:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
הורדת המודל:
מודלים ב-Hugging Face Hub מזוהים באמצעות מזהה מודל, בדרך כלל בפורמט <organization_or_username>/<model_name>. לדוגמה, כדי להוריד את המודל הרשמי של Google Gemma 3 270M שעבר כוונון להוראות, משתמשים בפקודה:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. המרת המודל וכימות שלו ל-LiteRT
מגדירים סביבה וירטואלית של Python ומתקינים את הגרסה היציבה העדכנית של חבילת LiteRT Torch:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
אפשר להשתמש בסקריפט הבא כדי להמיר את Safetensor למודל LiteRT.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
חשוב לדעת שהתהליך הזה אורך זמן ותלוי במהירות העיבוד של המחשב. לשם השוואה, במעבד עם 8 ליבות משנת 2025, מודל של 270M לוקח יותר מ-5 עד 10 דקות, ומודל של 1B יכול לקחת בערך 10 עד 30 דקות.
הפלט הסופי, מודל LiteRT, יישמר ב-OUTPUT_DIR_PATH שציינתם.
כדאי לשנות את הערכים הבאים בהתאם למגבלות הזיכרון והביצועים של מכשיר היעד.
-
kv_cache_max_len: הגודל הכולל של זיכרון העבודה שהוקצה למודל (מטמון KV). הקיבולת הזו היא מגבלה קשיחה, והיא צריכה להיות מספיקה לאחסון הסכום המשולב של הטוקנים של ההנחיה (המילוי המוקדם) וכל הטוקנים שנוצרו לאחר מכן (הפענוח). -
prefill_seq_len: מציין את מספר האסימונים בהנחיית הקלט לחלוקה לחלקים של מילוי מראש. כשמעבדים את הנחיית הקלט באמצעות חלוקה לחלקים של מילוי אוטומטי, הרצף כולו (למשל, 50,000 טוקנים) לא מחושב בבת אחת, אלא מחולק לפלחים קטנים יותר (למשל, חלקי טוקנים של 2,048) שנטענים ברצף למטמון כדי למנוע שגיאה של חוסר זיכרון. -
quantize: מחרוזת של סכימות הכימות שנבחרו. בהמשך מופיעה רשימה של מתכוני קוונטיזציה שזמינים ל-Gemma 3.-
none: No quantization -
fp16: משקלים מסוג FP16, הפעלות מסוג FP32 וחישוב נקודה צפה לכל הפעולות -
dynamic_int8: הפעלות FP32, משקלים INT8 וחישוב מספרים שלמים -
weight_only_int8: הפעלות FP32, משקלים INT8 וחישוב נקודה צפה
-
3. יצירת חבילת משימות מ-LiteRT ומ-tokenizer
מגדירים סביבה וירטואלית של Python ומתקינים את חבילת Python mediapipe:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
משתמשים בספריית genai.bundler כדי לארוז את המודל:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
הפונקציה bundler.create_bundle יוצרת קובץ .task שמכיל את כל המידע שנדרש להרצת המודל.
4. הסקת מסקנות באמצעות Mediapipe ב-Android
מאחלים את המשימה באמצעות אפשרויות בסיסיות להגדרת התצורה:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
משתמשים ב-generateResponse() method כדי ליצור תשובת טקסט.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
כדי להזרים את התשובה, משתמשים בשיטה generateResponseAsync().
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
מידע נוסף זמין במדריך בנושא הסקת מסקנות של LLM ב-Android.
השלבים הבאים
אפשר ליצור ולחקור עוד באמצעות מודלים של Gemma: