
このガイドでは、Hugging Face Safetensors 形式(.safetensors)の Gemma モデルを MediaPipe タスク ファイル形式(.task)に変換する手順について説明します。この変換は、MediaPipe LLM 推論 API と LiteRT ランタイムを使用して、Android と iOS でデバイス上の推論用に事前トレーニング済みまたはファインチューニング済みの Gemma モデルをデプロイするために不可欠です。
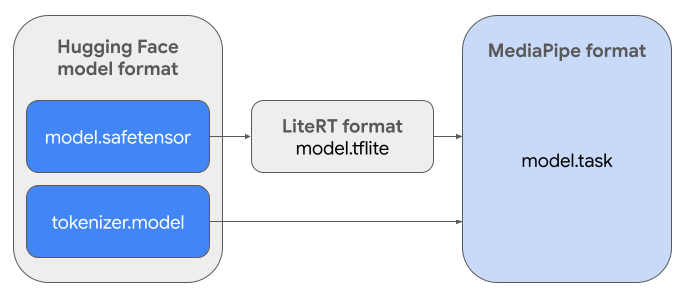
必要なタスク バンドル(.task)を作成するには、LiteRT Torch を使用します。このツールは、PyTorch モデルをマルチシグネチャ LiteRT(.tflite)モデルにエクスポートします。このモデルは MediaPipe LLM 推論 API と互換性があり、モバイル アプリケーションの CPU バックエンドでの実行に適しています。
最終的な .task ファイルは、MediaPipe で必要な自己完結型のパッケージで、LiteRT モデル、トークナイザー モデル、重要なメタデータをバンドルしています。このバンドルが必要なのは、エンドツーエンドの推論を可能にするために、トークナイザー(テキスト プロンプトをモデルのトークン エンベディングに変換する)を LiteRT モデルとともにパッケージ化する必要があるためです。
手順は次のとおりです。
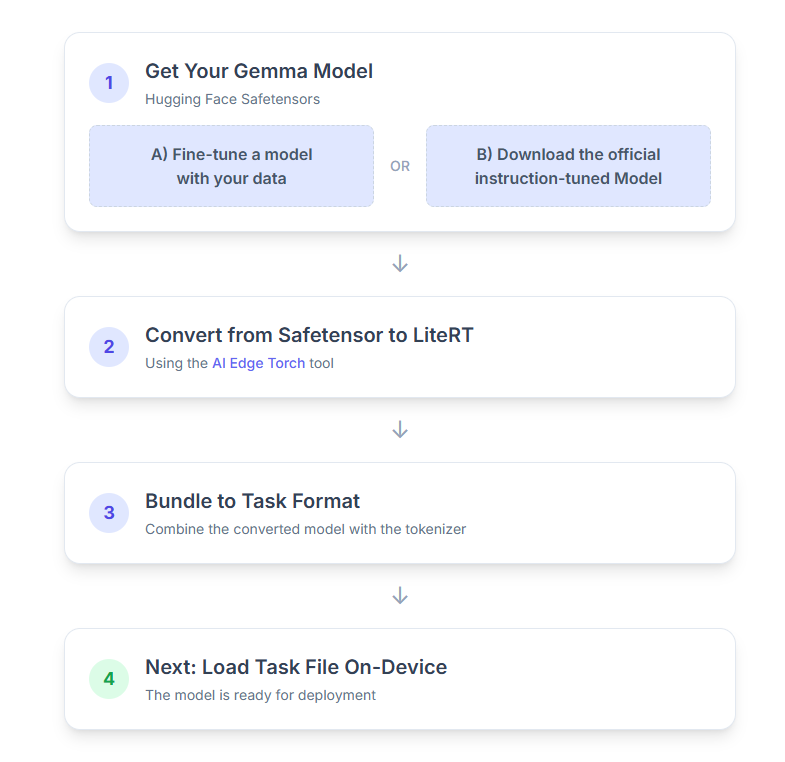
1. Gemma モデルを入手する
開始するには、次の 2 つの方法があります。
オプション A。既存のファインチューニング済みモデルを使用する
ファインチューニングされた Gemma モデルが用意されている場合は、次の手順に進みます。
オプション B。公式の指示用チューニング済みモデルをダウンロードする
モデルが必要な場合は、Hugging Face Hub から指示チューニングされた Gemma をダウンロードできます。
必要なツールをセットアップします。
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
モデルをダウンロードする:
Hugging Face Hub のモデルは、通常 <organization_or_username>/<model_name> 形式のモデル ID で識別されます。たとえば、Google の公式の Gemma 3 270M 指示チューニング済みモデルをダウンロードするには、次のコマンドを使用します。
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. モデルを LiteRT に変換して量子化する
Python 仮想環境を設定し、LiteRT Torch パッケージの最新の安定版をインストールします。
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
次のスクリプトを使用して、Safetensor を LiteRT モデルに変換します。
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
このプロセスには時間がかかり、パソコンの処理速度によって異なります。参考までに、2025 年の 8 コア CPU では、2 億 7,000 万個のモデルに 5 ~ 10 分以上かかり、10 億個のモデルには 10 ~ 30 分ほどかかることがあります。
最終出力である LiteRT モデルは、指定した OUTPUT_DIR_PATH に保存されます。
ターゲット デバイスのメモリとパフォーマンスの制約に基づいて、次の値を調整します。
kv_cache_max_len: モデルのワーキング メモリ(KV キャッシュ)の割り当て済み合計サイズを定義します。この容量はハードリミットであり、プロンプトのトークン(プリフィル)と後続のすべての生成トークン(デコード)の合計を保存するのに十分な容量が必要です。prefill_seq_len: プリフィル チャンク分割の入力プロンプトのトークン数を指定します。プリフィル チャンクを使用して入力プロンプトを処理する場合、シーケンス全体(50,000 個のトークン)は一度に計算されません。代わりに、管理可能なセグメント(2,048 個のトークンのチャンクなど)に分割され、メモリ不足エラーを防ぐために順番にキャッシュに読み込まれます。quantize: 選択した量子化スキームの文字列。Gemma 3 で使用可能な量子化レシピのリストは次のとおりです。none: 量子化なしfp16: すべてのオペレーションで FP16 の重み、FP32 のアクティベーション、浮動小数点計算dynamic_int8: FP32 アクティベーション、INT8 重み、整数計算weight_only_int8: FP32 アクティベーション、INT8 重み、浮動小数点計算
3. LiteRT とトークナイザーからタスクバンドルを作成する
Python 仮想環境を設定し、mediapipe Python パッケージをインストールします。
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
genai.bundler ライブラリを使用してモデルをバンドルします。
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
bundler.create_bundle 関数は、モデルの実行に必要なすべての情報を含む .task ファイルを作成します。
4. Android での Mediapipe を使用した推論
基本的な構成オプションを使用してタスクを初期化します。
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
generateResponse() メソッドを使用してテキスト レスポンスを生成します。
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
レスポンスをストリーミングするには、generateResponseAsync() メソッドを使用します。
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
詳しくは、Android 向け LLM 推論ガイドをご覧ください。
次のステップ
Gemma モデルでさらに構築して探索する: