
|
|
|
|
|
 GitHub でソースを見る GitHub でソースを見る
|
このガイドでは、Hugging Face の Transformers と TRL を使用して、モバイルゲームの NPC データセットで Gemma をファインチューニングする方法について説明します。学習内容:
- 開発環境をセットアップする
- ファインチューニング データセットを準備する
- TRL と SFTTrainer を使用した Gemma のフルモデル ファインチューニング
- モデル推論とバイブチェックをテストする
開発環境をセットアップする
まず、TRL やデータセットなどの Hugging Face ライブラリをインストールして、さまざまな RLHF やアライメント手法を含むオープンモデルをファインチューニングします。
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
注: Ampere アーキテクチャ(NVIDIA L4 など)以降の GPU を使用している場合は、Flash attention を使用できます。Flash Attention は、計算を大幅に高速化し、メモリ使用量をシーケンス長で 2 次から線形に削減する手法です。これにより、トレーニングを最大 3 倍高速化できます。詳しくは、FlashAttention をご覧ください。
トレーニングを開始する前に、Gemma の利用規約に同意していることを確認する必要があります。http://huggingface.co/google/gemma-3-270m-it のモデルページで [Agree and access repository] ボタンをクリックすると、Hugging Face でライセンスに同意できます。
ライセンスに同意したら、モデルにアクセスするための有効な Hugging Face トークンが必要です。Google Colab 内で実行している場合は、Colab シークレットを使用して Hugging Face トークンを安全に使用できます。それ以外の場合は、login メソッドでトークンを直接設定できます。トレーニング中にモデルを Hub に push するため、トークンに書き込みアクセス権があることを確認してください。
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
結果は Colab のローカル仮想マシンに保存できます。ただし、中間結果を Google ドライブに保存することを強くおすすめします。これにより、トレーニング結果の安全性が確保され、最適なモデルを簡単に比較して選択できます。
from google.colab import drive
drive.mount('/content/drive')
ファインチューニングするベースモデルを選択し、チェックポイント ディレクトリと学習率を調整します。
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
ファインチューニング データセットを作成して準備する
bebechien/MobileGameNPC データセットは、プレイヤーと 2 人のエイリアン NPC(火星人と金星人)の会話の小さなサンプルを提供します。各 NPC には独自の話し方があります。たとえば、火星人の NPC は「s」の音を「z」に置き換えるアクセントで話し、「the」を「da」、「this」を「diz」と発音し、*k'tak* のようなクリック音を時折含みます。
このデータセットは、ファインチューニングの重要な原則である「必要なデータセットのサイズは目的の出力によって異なる」ことを示しています。
- モデルに、すでに知っている言語のスタイル バリエーション(火星人のアクセントなど)を教えるには、10 ~ 20 個の例を含む小さなデータセットで十分です。
- ただし、モデルにまったく新しい言語や混合言語を教えるには、はるかに大きなデータセットが必要になります。
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
TRL と SFTTrainer を使用して Gemma をファインチューニングする
これで、モデルをファインチューニングする準備が整いました。Hugging Face TRL の SFTTrainer を使用すると、オープン LLM のファインチューニングを簡単に監督できます。SFTTrainer は transformers ライブラリの Trainer のサブクラスであり、同じ機能がすべてサポートされています。
次のコードは、Hugging Face から Gemma モデルとトークナイザーを読み込みます。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
ファインチューニング前
次の出力は、このユースケースではすぐに使用できる機能では十分でない可能性があることを示しています。
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
上記の例では、ゲーム内での会話を生成するというモデルの主な機能を確認しています。次の例は、キャラクターの一貫性をテストするように設計されています。トピック外のプロンプトを使用してモデルをテストします。たとえば、Sorry, you are a game NPC. はキャラクターのナレッジベースの範囲外です。
このテストの目的は、モデルがコンテキスト外の質問に答えるのではなく、キャラクターを維持できるかどうかを確認することです。これは、ファインチューニング プロセスで目的のペルソナがどの程度効果的に組み込まれたかを評価するためのベースラインとして機能します。
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
プロンプト エンジニアリングを使用してトーンを調整できますが、結果は予測不可能で、常に望ましいペルソナと一致するとは限りません。
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
トレーニング
トレーニングを開始する前に、SFTConfig インスタンスで使用するハイパーパラメータを定義する必要があります。
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
これで、モデルのトレーニングを開始するために SFTTrainer を作成するために必要なすべてのビルディング ブロックが揃いました。
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
train() メソッドを呼び出してトレーニングを開始します。
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
トレーニング損失と検証損失をプロットするには、通常、これらの値を TrainerState オブジェクトまたはトレーニング中に生成されたログから抽出します。
Matplotlib などのライブラリを使用して、これらの値をトレーニング ステップまたはエポックごとに可視化できます。x 軸はトレーニング ステップまたはエポックを表し、y 軸は対応する損失値を表します。
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
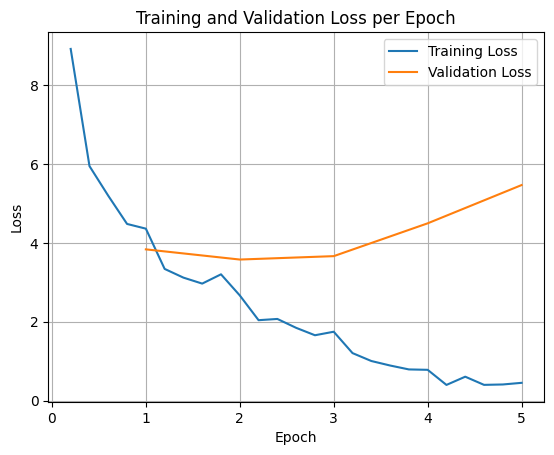
この可視化は、トレーニング プロセスをモニタリングし、ハイパーパラメータのチューニングや早期停止について情報に基づいた意思決定を行うのに役立ちます。
トレーニング損失は、モデルのトレーニングに使用されたデータのエラーを測定しますが、検証損失は、モデルが以前に見たことのない別のデータセットのエラーを測定します。両方をモニタリングすることで、過学習(モデルがトレーニング データでは優れたパフォーマンスを発揮するものの、未知のデータではパフォーマンスが低下する状態)を検出できます。
- 検証の損失 >> トレーニングの損失: 過学習
- 検証の損失 > トレーニングの損失: 過学習の可能性あり
- 検証損失 < トレーニング損失: 過小適合
- 検証の損失 << トレーニングの損失: 過小適合
モデルの推論をテストする
トレーニングが完了したら、モデルを評価してテストします。テスト データセットからさまざまなサンプルを読み込み、それらのサンプルでモデルを評価できます。
この特定のユースケースでは、最適なモデルは好みの問題です。興味深いことに、通常「過剰適合」と呼ばれるものが、ゲームの NPC には非常に役立つことがあります。これにより、モデルは一般的な情報を忘れて、トレーニングされた特定のペルソナと特性にロックオンし、一貫してそのキャラクターを維持します。
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
テスト データセットからすべての質問を読み込み、出力を生成しましょう。
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
元の汎用プロンプトを試すと、モデルはトレーニングされたスタイルで回答しようとします。この例では、過剰適合と壊滅的忘却は、ゲームの NPC にとって実際に有益です。適用できない可能性のある一般的な知識を忘れ始めるためです。これは、出力が特定のデータ形式に制限されることを目的とする他のタイプのフル ファインチューニングにも当てはまります。
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
まとめと次のステップ
このチュートリアルでは、TRL を使用してモデル全体をファインチューニングする方法について説明しました。次のドキュメントもご覧ください。