
Para entender o DiffusionGemma, é útil examinar as limitações principais dos modelos de linguagem padrão e como a difusão baseada em texto é diferente.
O problema com modelos autorregressivos
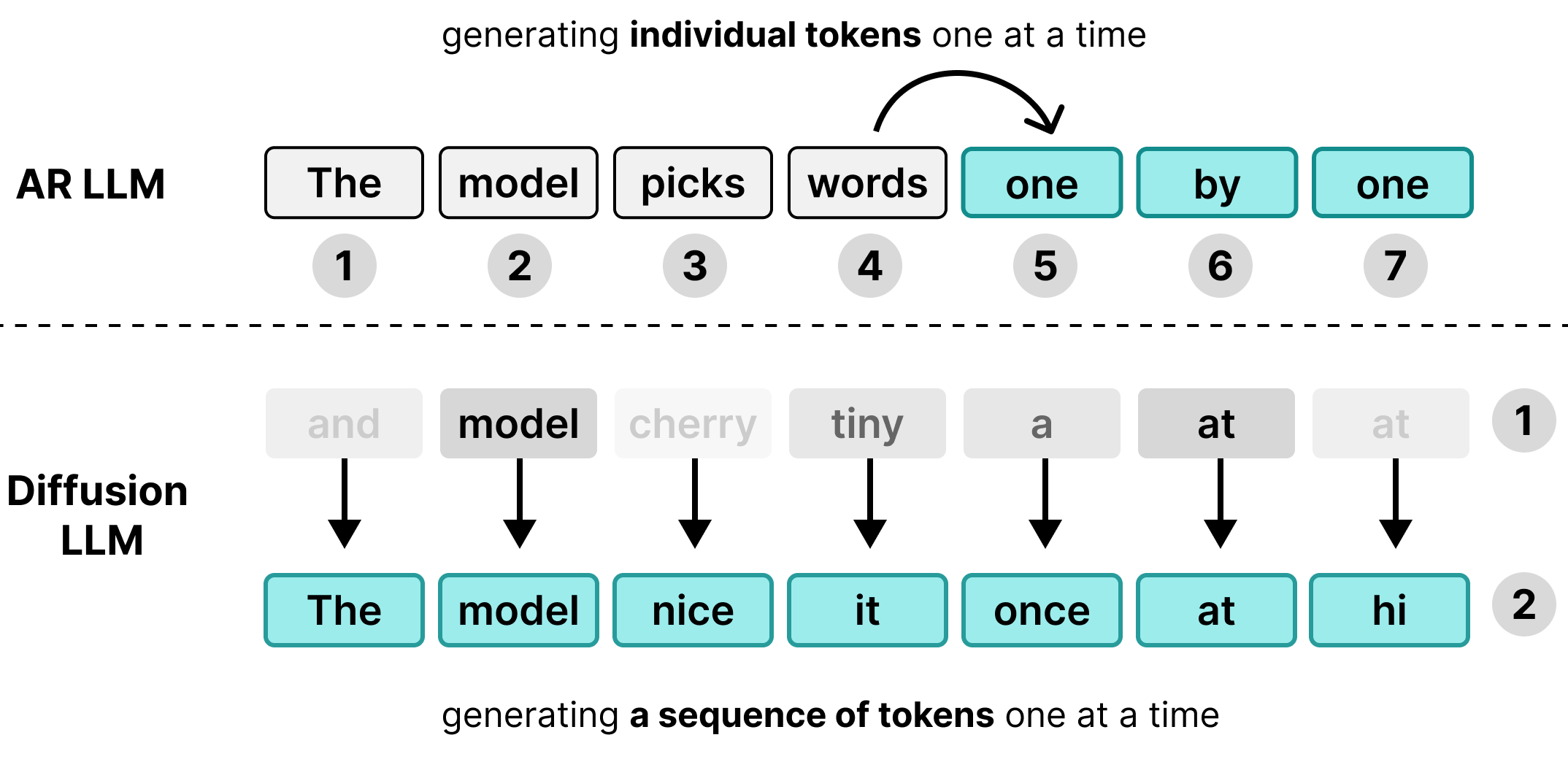
Muitos modelos de linguagem grandes (LLMs) são autorregressivos, ou seja, geram texto um token por vez. Embora essa abordagem funcione bem para atender a muitos usuários simultaneamente por loteamento, ela cria um gargalo de latência para usuários individuais.
Durante a fase de decodificação, os modelos Transformer padrão são limitados pela memória, e não pela computação. A maior parte do tempo de geração é gasta carregando pesos do modelo da memória de hardware para as unidades de processamento, em vez de realizar os cálculos matemáticos reais. Como os pesos só precisam ser carregados uma vez por etapa, independente do tamanho do lote, gerar um token leva quase o mesmo tempo para 1 usuário e para 256 usuários agrupados.
Consequentemente, um usuário individual não tem vantagem de latência, e a capacidade computacional do hardware fica ociosa enquanto aguarda transferências de memória.
O DiffusionGemma usa esse tempo de computação ocioso para o usuário individual. Em vez de gerar um token para 256 usuários separados, ele gera 256 tokens de uma vez para um único usuário.
O modelo inicializa uma sequência em branco de 256 tokens aleatórios, chamada de tela, e avalia e refina iterativamente toda a tela simultaneamente. Isso muda o modelo de limitado pela memória para limitado pela computação, permitindo que ele dimensione as velocidades de processamento de maneira eficiente à medida que a potência computacional aumenta.
| Aspecto | Autorregressão de texto | Difusão de texto |
|---|---|---|
| Geração de tokens | Um token por vez | Uma tela inteira de tokens de uma só vez |
| Etapas | Uma etapa para cada token | Uma etapa para vários tokens |
| Ordem de geração | Da esquerda para a direita | Todas as posições em paralelo |
| Ponto de partida | Sequência vazia | Tokens aleatórios extraídos do vocabulário |
| Correção de erros | Estático; não é possível revisar tokens anteriores | Dinâmica: pode revisar qualquer posição da tela |
| Gargalo de hardware | Limitado pela memória | Vinculado à computação |
| Foco na capacidade | Alta capacidade de processamento multiusuário | Latência ultrabaixa para um único usuário |
Como funciona a difusão de texto
Na geração de imagens, os modelos de difusão começam com ruído gaussiano 100% aleatório e o removem progressivamente (redução de ruído) em várias etapas guiadas por um comando de texto. Traduzir essa lógica para texto é mais desafiador porque os tokens de texto são entidades discretas, ao contrário dos valores de pixels contínuos.
O DiffusionGemma realiza a difusão baseada em texto com uma progressão de metodologias especializadas:
1. Difusão mascarada
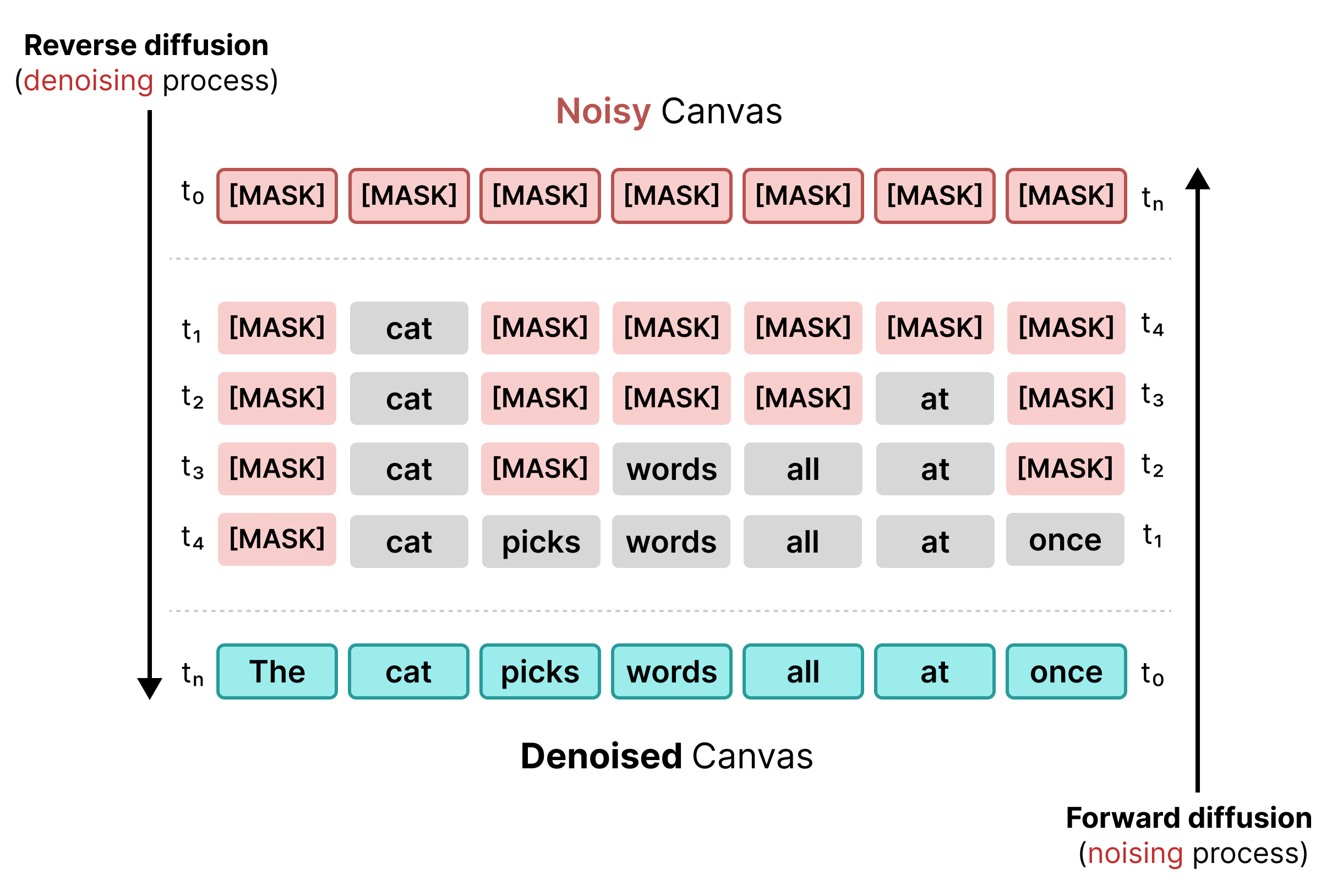
A difusão de texto inicial dependia de mascaramento, semelhante ao treinamento do BERT. Tokens aleatórios em uma sequência são substituídos por um token [MASK] (que representa ruído). Durante a difusão reversa, o modelo prevê o token correto por trás da máscara, substituindo os tokens quando a confiança atinge um limite específico.
No entanto, a difusão mascarada sofre de rigidez: depois que um token [MASK] é substituído por uma palavra, ele fica bloqueado e não pode ser corrigido em etapas posteriores se o contexto ao redor mudar.
2. Uniform State Diffusion
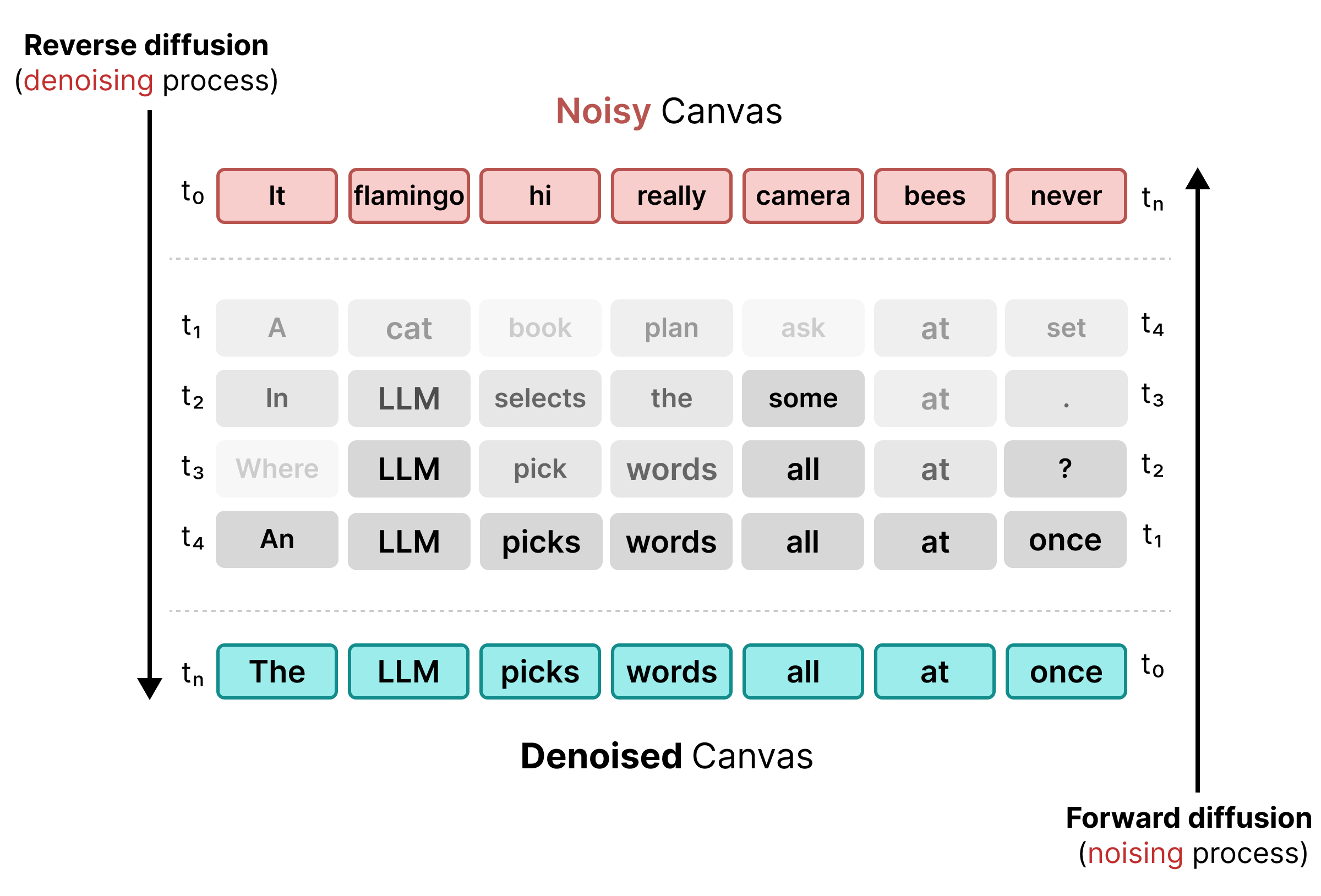
Para resolver as limitações da mascaragem, a DiffusionGemma usa a Difusão de estado uniforme (link em inglês). Em vez de um token [MASK] explícito, o ruído é introduzido pela substituição de palavras originais por tokens aleatórios do vocabulário.
Durante o processo de remoção de ruído, o modelo analisa toda a tela para determinar quais tokens são ruídos contextuais e os atualiza. Se um token estiver correto, ele vai manter uma alta probabilidade. Se a probabilidade de um token cair abaixo de um limite devido ao surgimento de um novo contexto em etapas posteriores, ele será re-ruído com um novo token aleatório. Esse ciclo permite a correção contínua de erros e o refinamento paralelo da tela.
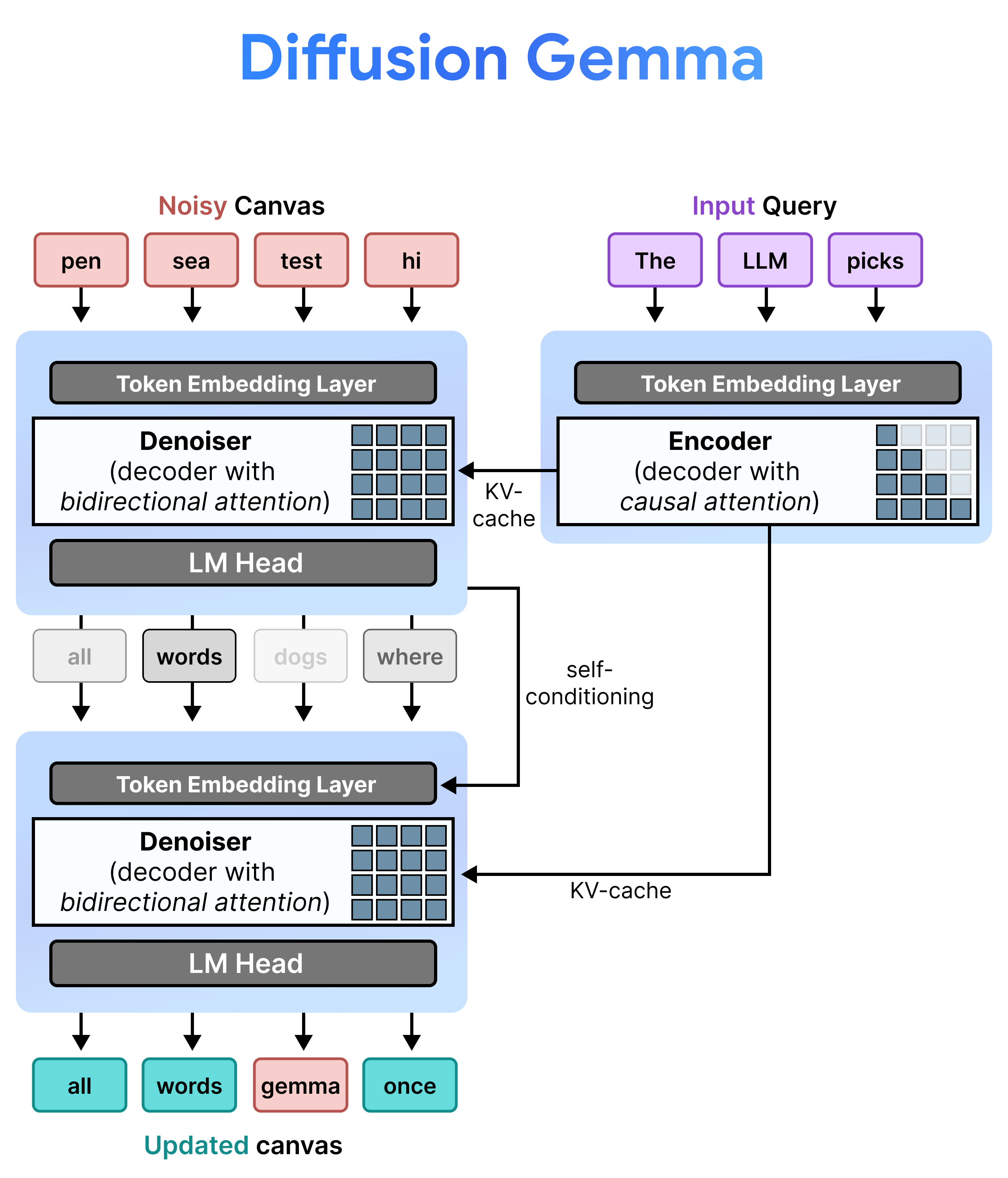
Arquitetura: pré-preenchimento e remoção de ruído incrementais
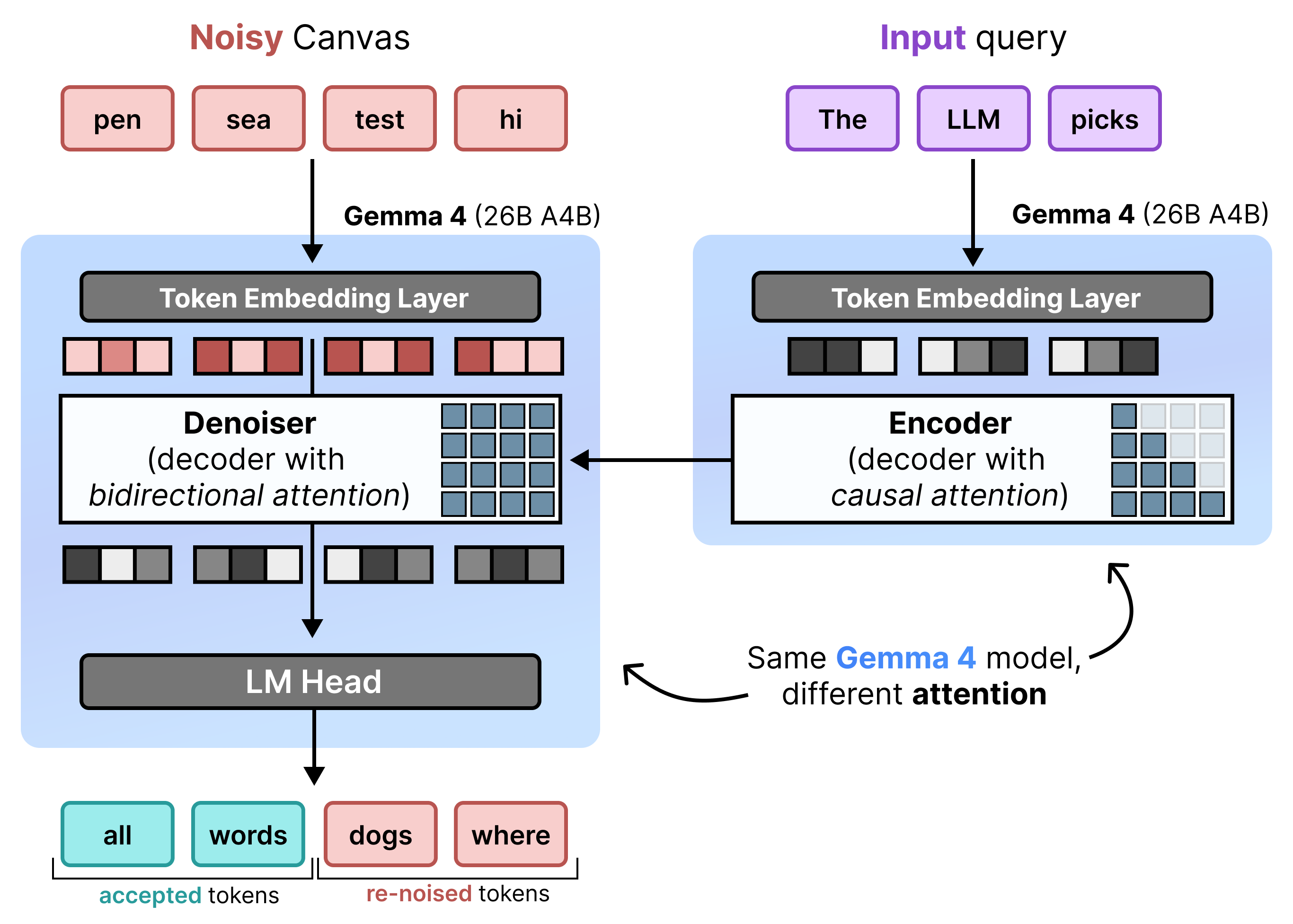
O DiffusionGemma implementa a difusão de estado uniforme de maneira eficiente alternando entre pré-preenchimento incremental e remoção de ruído. O modelo Gemma 4 26B A4B não é usado de forma nativa, mas é ajustado para oferecer suporte às diferentes tarefas de remoção de ruído e codificação. Em vez de usar modelos separados, um único backbone alterna dinamicamente entre dois modos:
- Pré-preenchimento / pré-preenchimento incremental (causal): usa atenção causal para ingerir o contexto do comando e gravar no cache KV. Isso é executado uma vez para pré-preencher o contexto inicial e depois uma vez por bloco para anexar cada tela finalizada de 256 tokens ao cache KV antes de prosseguir com a remoção de ruído da próxima tela.
- Redução de ruído (bidirecional): usa atenção bidirecional para reduzir o ruído do canvas de forma iterativa. Os tokens de consulta em qualquer posição no canvas podem atender a todos os outros tokens do canvas (bem como ao cache KV), permitindo que o modelo processe o contexto de forma bidirecional.
Frameworks de inferência avançada
Para mover uma tela de ruído puro para texto finalizado, a DiffusionGemma usa uma coleção de sistemas de decodificação subjacentes:
Autocondicionamento
Durante a inferência, o decodificador (também conhecido como denoiser) retém o estado anterior. Depois de concluir uma etapa de remoção de ruído, ele multiplica a matriz de distribuição de probabilidade gerada pela tabela de incorporação de token. Isso produz uma representação vetorial localizada que carrega uma memória das previsões anteriores e métricas de confiança, que é transmitida diretamente para a próxima etapa.
Amostragem de várias telas (difusão em blocos)
Como uma única tela é fixada em 256 tokens, o DiffusionGemma encadeia a difusão e a regressão automática para textos longos. Ele executa ciclos de difusão para gerar um bloco completo de 256 tokens, anexa esse bloco concluído ao contexto do comando, atualiza o cache KV do codificador e inicia um novo ciclo de difusão de tela de 256 tokens.
Resumo
Os modelos de linguagem autorregressivos padrão geram texto sequencialmente (um token por vez), o que os torna limitados pela memória e cria um gargalo de latência para usuários individuais. O DiffusionGemma resolve isso mudando para um modelo limitado por computação que gera uma "tela" completa de 256 tokens simultaneamente.
Ao usar a difusão de estado uniforme, o modelo substitui o texto por ruído de vocabulário aleatório e refina de maneira iterativa toda a tela em paralelo. Ele usa um Gemma 4 26B A4B refinado para oferecer suporte às diferentes tarefas de remoção de ruído e codificação. Frameworks avançados, como autocondicionamento e amostragem de blocos de vários canvas, permitem que o modelo corrija erros de forma dinâmica, processe a geração de texto longo e alcance uma latência ultrabaixa para um único usuário.