
หากต้องการทําความเข้าใจ DiffusionGemma คุณควรพิจารณาข้อจํากัดหลักของ โมเดลภาษามาตรฐานและความแตกต่างของการแพร่กระจายตามข้อความ
ปัญหาเกี่ยวกับโมเดล Autoregressive
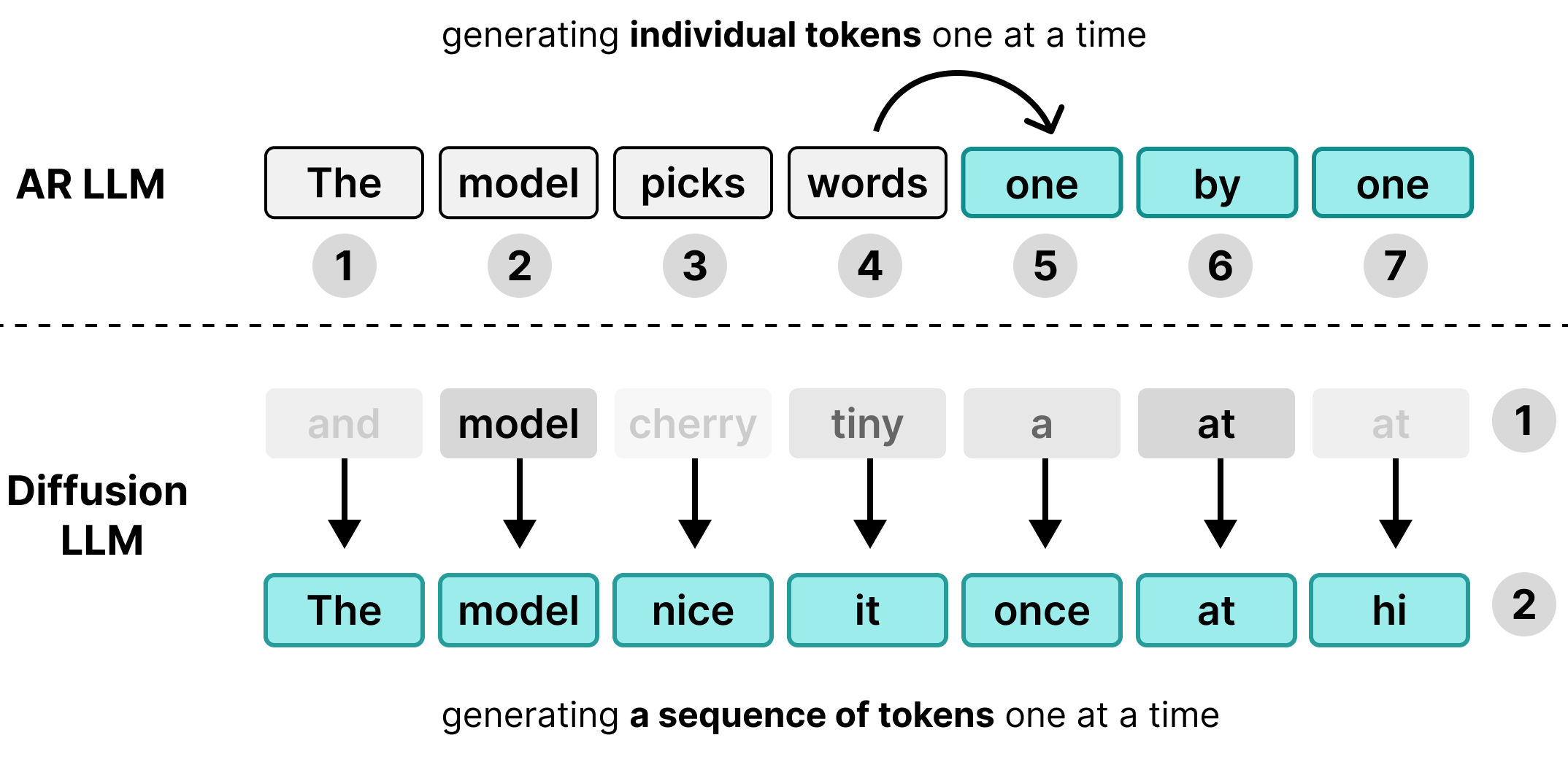
โมเดลภาษาขนาดใหญ่ (LLM) จำนวนมากเป็นแบบถดถอยอัตโนมัติ ซึ่งหมายความว่าโมเดลจะสร้างข้อความทีละโทเค็น แม้ว่าแนวทางนี้จะเหมาะกับการแสดงโฆษณาต่อผู้ใช้จำนวนมากพร้อมกันผ่านการจัดกลุ่ม แต่ก็ทำให้เกิดคอขวดด้านเวลาในการตอบสนองสำหรับผู้ใช้แต่ละราย
ในระหว่างขั้นตอนการถอดรหัส โมเดล Transformer มาตรฐานจะขึ้นอยู่กับหน่วยความจำ มากกว่าขึ้นอยู่กับการคำนวณ เวลาในการสร้างส่วนใหญ่จะใช้ไปกับการโหลดน้ำหนักของโมเดล จากหน่วยความจำของฮาร์ดแวร์ไปยังหน่วยประมวลผล แทนที่จะใช้ไปกับการ คำนวณทางคณิตศาสตร์จริง เนื่องจากระบบจะโหลดน้ำหนักเพียงครั้งเดียวต่อขั้นตอน โดยไม่คำนึงถึงขนาดกลุ่ม การสร้างโทเค็นจึงใช้เวลาเกือบเท่ากัน สำหรับผู้ใช้ 1 คนและผู้ใช้ 256 คนที่จัดกลุ่มไว้ด้วยกัน
ด้วยเหตุนี้ ผู้ใช้แต่ละรายจึงไม่เห็นข้อดีด้านเวลาในการตอบสนอง ความสามารถในการประมวลผลของฮาร์ดแวร์ จึงไม่ได้ใช้งานขณะรอการโอนหน่วยความจำ
DiffusionGemma ใช้เวลาในการคำนวณที่ไม่มีการใช้งานนี้สำหรับผู้ใช้แต่ละราย แทนที่จะสร้างโทเค็น 1 รายการสำหรับผู้ใช้ 256 รายแยกกัน แต่จะสร้างโทเค็น 256 รายการ พร้อมกันสำหรับผู้ใช้รายเดียว
โมเดลจะเริ่มต้นลำดับโทเค็นแบบสุ่ม 256 รายการที่ว่างเปล่า ซึ่งเรียกว่าผืนผ้าใบ จากนั้นจะประเมินและปรับแต่งผืนผ้าใบทั้งหมด พร้อมกันซ้ำๆ ซึ่งจะเปลี่ยนโมเดลจากการจำกัดด้วยหน่วยความจำเป็นการจำกัดด้วยการคำนวณ ทำให้สามารถปรับขนาดความเร็วในการประมวลผลได้อย่างมีประสิทธิภาพเมื่อกำลังการคำนวณเพิ่มขึ้น
| ทิศด้านลาด | การถดถอยอัตโนมัติของข้อความ | Text Diffusion |
|---|---|---|
| การสร้างโทเค็น | ทีละโทเค็น | Canvas ของโทเค็นทั้งหมดในครั้งเดียว |
| ขั้นตอน | 1 ขั้นตอนสำหรับโทเค็นแต่ละรายการ | ขั้นตอนเดียวสำหรับหลายโทเค็น |
| ลำดับการสร้าง | ซ้ายไปขวา | ทุกตำแหน่งแบบขนาน |
| จุดเริ่มต้น | ลำดับว่าง | โทเค็นแบบสุ่มที่สุ่มตัวอย่างจากคำศัพท์ |
| การแก้ไขข้อผิดพลาด | คงที่ แก้ไขโทเค็นที่ผ่านมาไม่ได้ | ไดนามิก แก้ไขตำแหน่ง Canvas ได้ |
| คอขวดของฮาร์ดแวร์ | ขึ้นอยู่กับหน่วยความจำ | ขึ้นอยู่กับการประมวลผล |
| เน้นปริมาณงาน | อัตราการส่งข้อมูลแบบหลายผู้ใช้สูง | เวลาในการตอบสนองของผู้ใช้รายเดียวต่ำมาก |
ทำความเข้าใจกลไกการแพร่กระจายของข้อความ
ในการสร้างรูปภาพ โมเดลการแพร่กระจายจะเริ่มต้นด้วยสัญญาณรบกวนแบบ Gaussian แบบสุ่ม 100% และค่อยๆ นำออก (การลดสัญญาณรบกวน) ในหลายขั้นตอนโดยมีพรอมต์ข้อความเป็นแนวทาง การแปลตรรกะนี้เป็นข้อความนั้นมีความท้าทายมากกว่าเนื่องจากโทเค็นข้อความเป็นเอนทิตีแบบไม่ต่อเนื่อง ซึ่งแตกต่างจากค่าพิกเซลแบบต่อเนื่อง
DiffusionGemma สร้างการแพร่กระจายตามข้อความผ่านลำดับของ วิธีการเฉพาะทางดังนี้
1. การแพร่กระจายแบบมาสก์
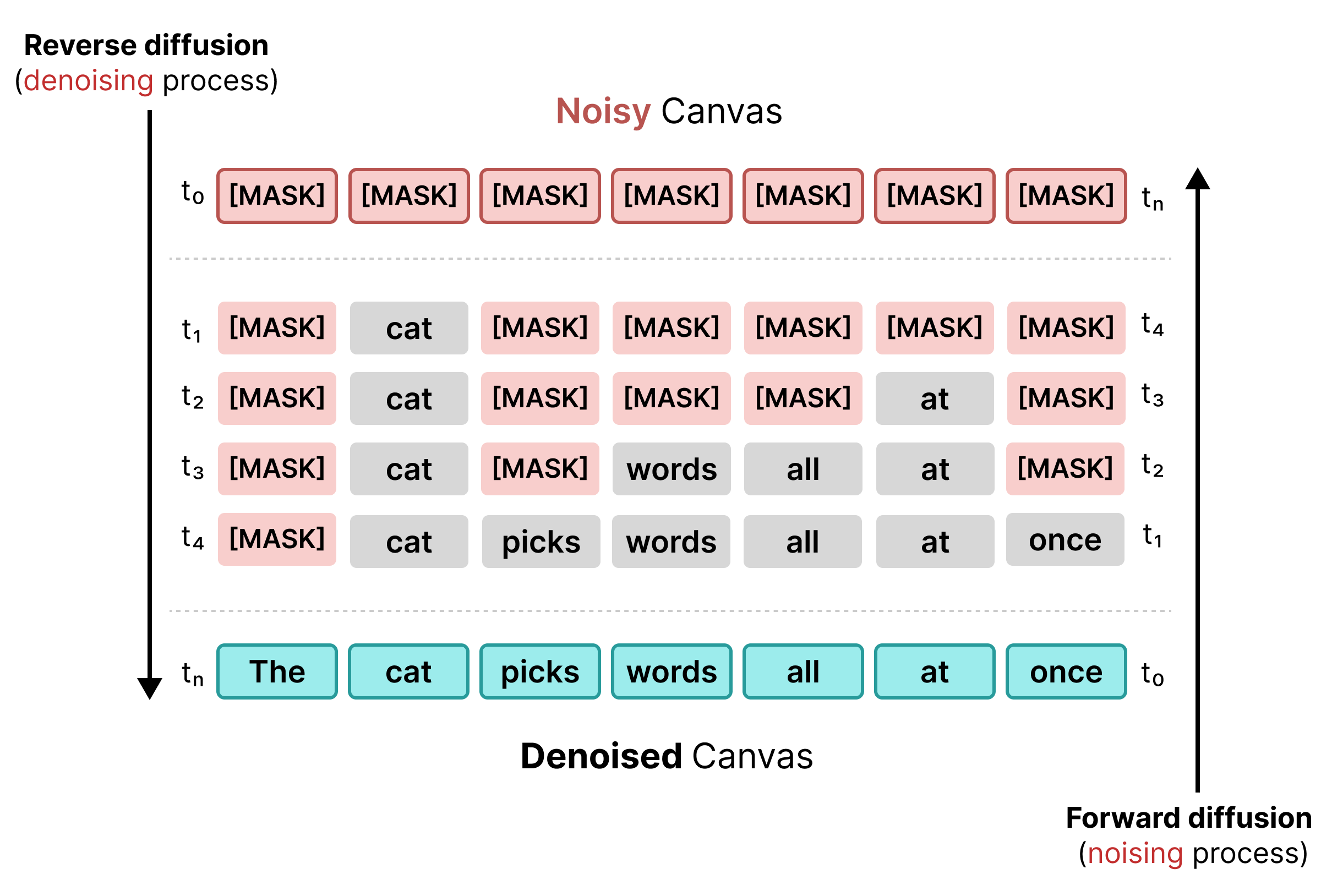
การแพร่ข้อความในระยะแรกอาศัยการมาสก์ ซึ่งคล้ายกับการฝึก BERT โทเค็นแบบสุ่ม
ในลำดับจะถูกแทนที่ด้วยโทเค็น [MASK] (แสดงถึงสัญญาณรบกวน) ในระหว่างการ
ดีฟิวชันแบบย้อนกลับ โมเดลจะคาดการณ์โทเค็นที่ถูกต้องซึ่งอยู่หลังมาสก์
โดยแทนที่โทเค็นเมื่อค่าความเชื่อมั่นตรงกับเกณฑ์ที่เฉพาะเจาะจง
อย่างไรก็ตาม การแพร่กระจายแบบมาสก์มีความแข็งตัว กล่าวคือ เมื่อโทเค็น [MASK] ถูกแทนที่ด้วยคำแล้ว ก็จะล็อกคำนั้นไว้ หากบริบทโดยรอบเปลี่ยนแปลง คุณจะแก้ไขในขั้นตอนต่อๆ ไปไม่ได้
2. การแพร่กระจายสถานะแบบสม่ำเสมอ
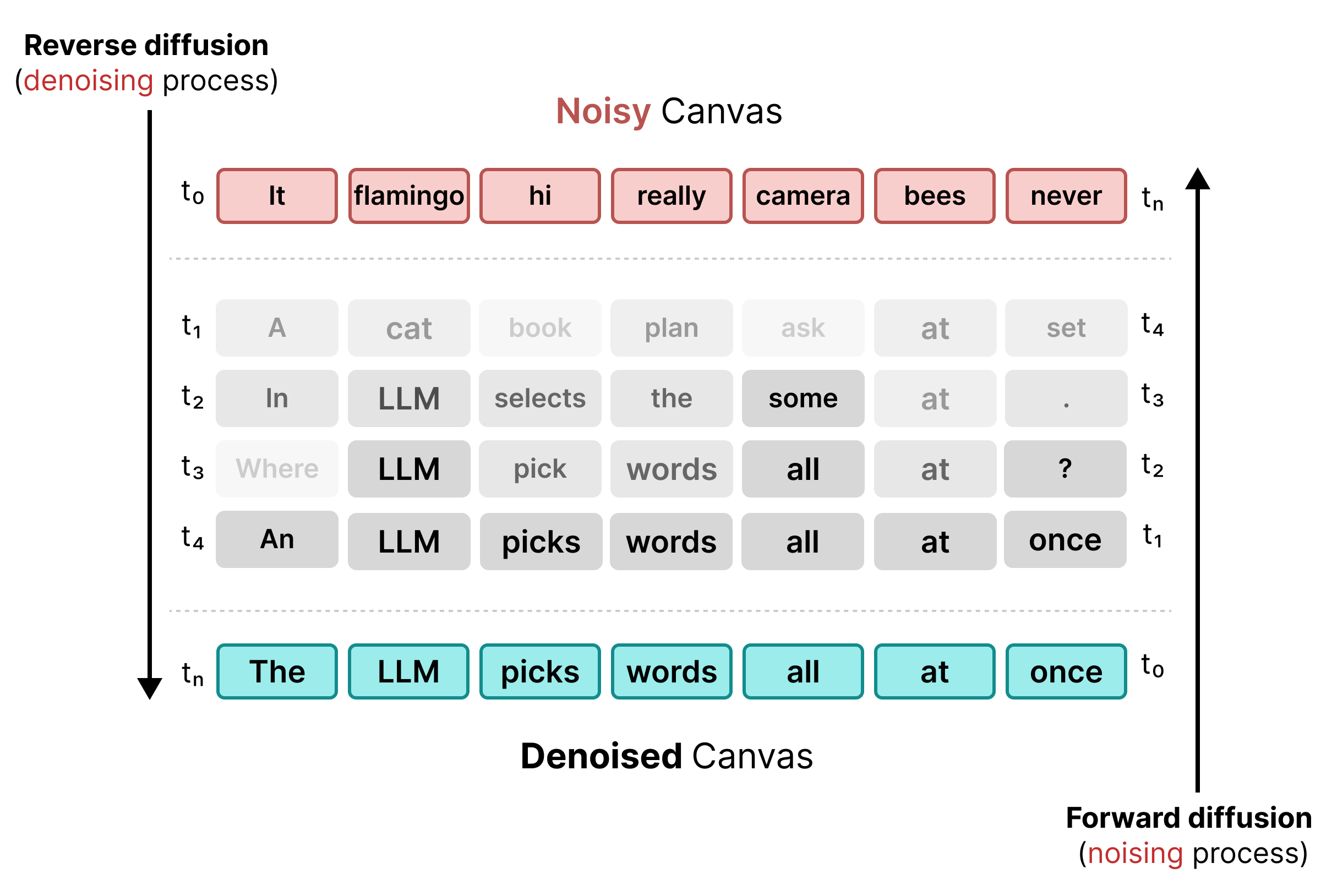
DiffusionGemma ใช้ Uniform State
Diffusion เพื่อแก้ไขข้อจำกัดของการมาสก์ แทนที่จะใช้โทเค็น [MASK] อย่างชัดเจน ระบบจะเพิ่มสัญญาณรบกวนโดยการแทนที่คำต้นฉบับด้วยโทเค็นแบบสุ่มทั้งหมดจากคำศัพท์
ในระหว่างกระบวนการลดสัญญาณรบกวน โมเดลจะวิเคราะห์ทั้ง Canvas เพื่อระบุว่าโทเค็นใดเป็นสัญญาณรบกวนตามบริบทและอัปเดตโทเค็นเหล่านั้น หากโทเค็นถูกต้อง โทเค็นจะยังคงมีความน่าจะเป็นสูง หากความน่าจะเป็นของโทเค็นลดลงต่ำกว่าเกณฑ์เนื่องจากบริบทใหม่ที่เกิดขึ้นในขั้นตอนต่อๆ ไป ระบบจะเพิ่มสัญญาณรบกวนอีกครั้งด้วยโทเค็นแบบสุ่มใหม่ วงจรนี้ช่วยให้แก้ไขข้อผิดพลาดและปรับแต่ง Canvas แบบขนานได้อย่างต่อเนื่อง
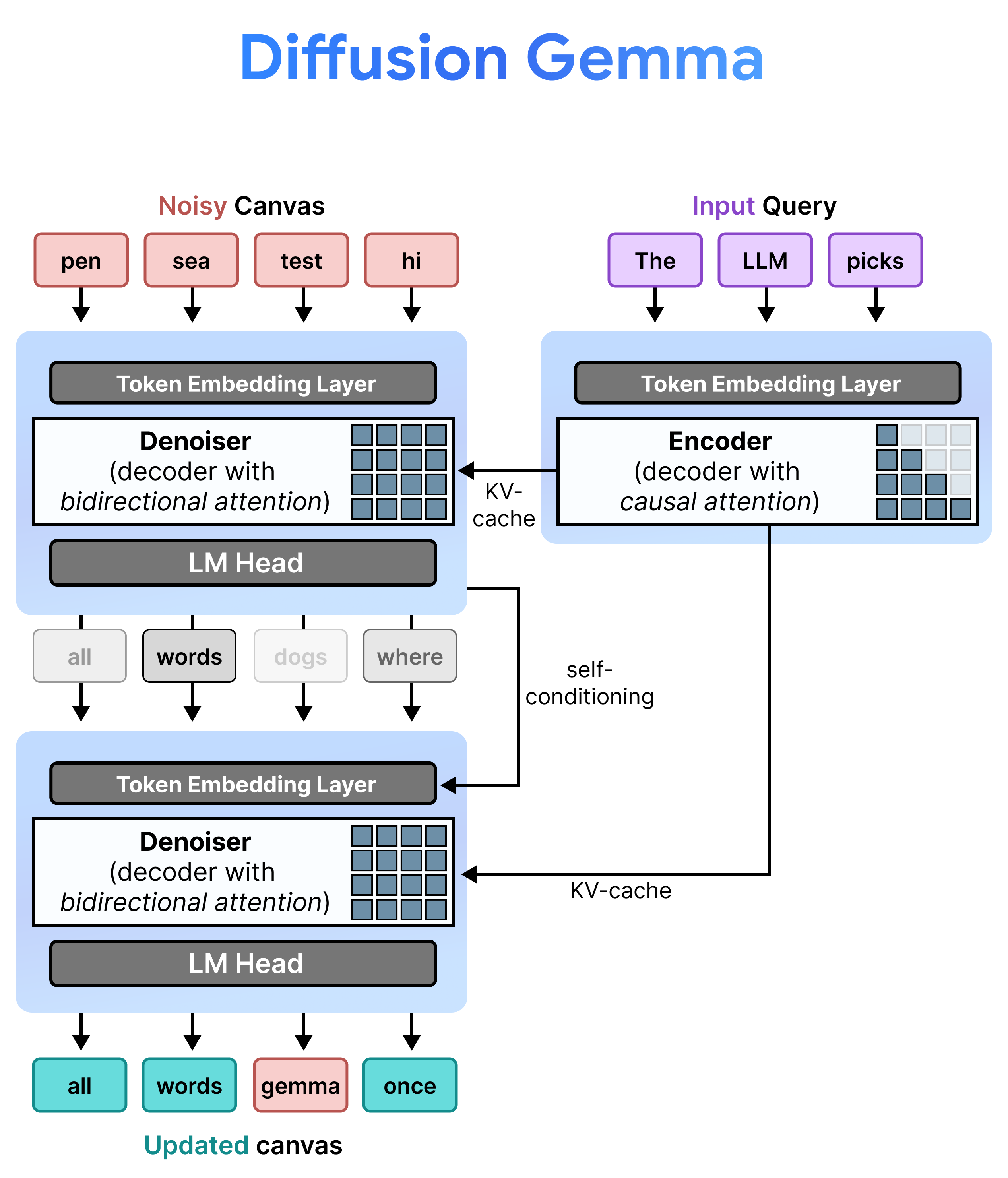
สถาปัตยกรรม: การเติมข้อความล่วงหน้าและการลดสัญญาณรบกวนแบบเพิ่มทีละส่วน
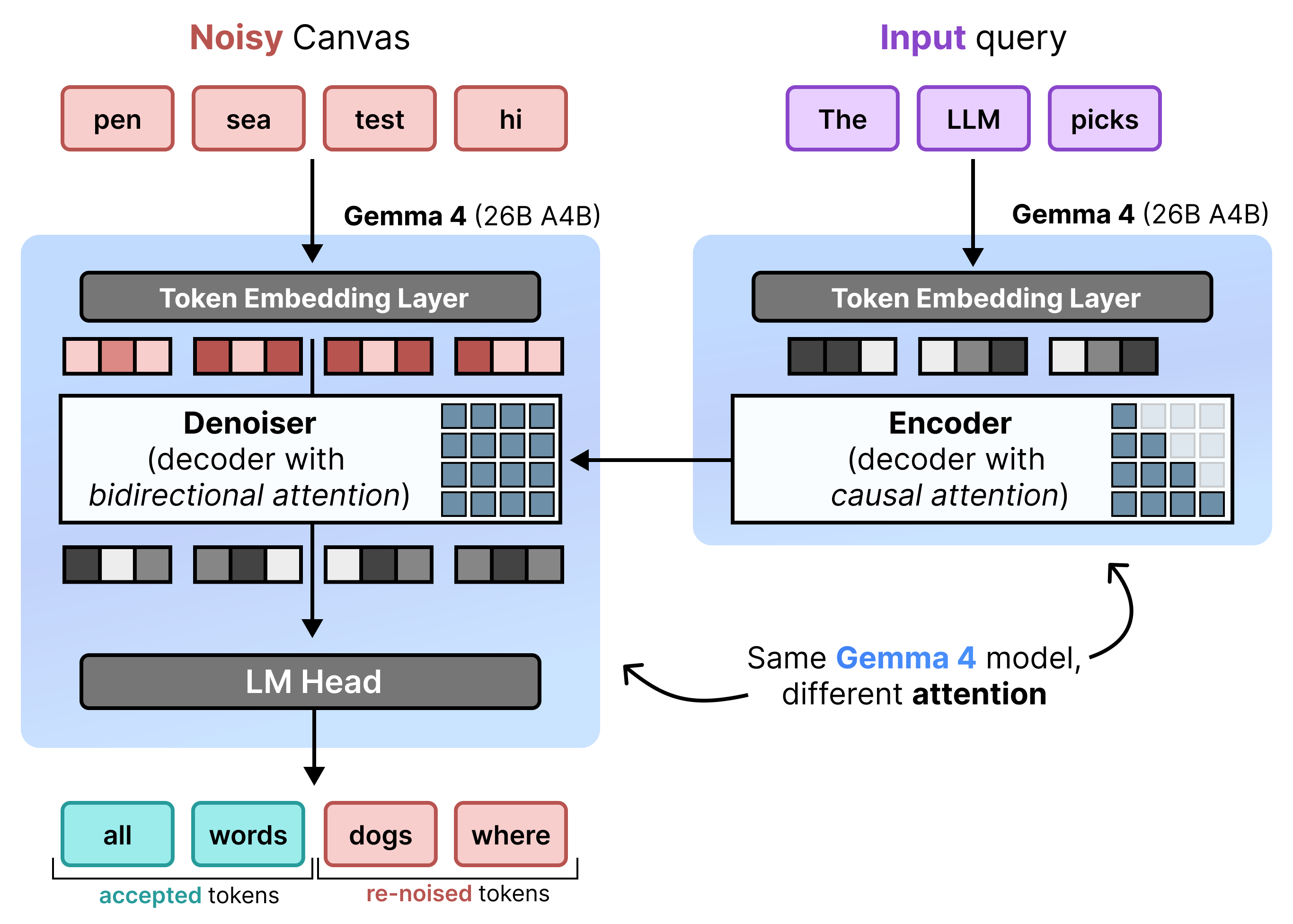
DiffusionGemma ใช้การแพร่กระจายสถานะแบบสม่ำเสมออย่างมีประสิทธิภาพโดยสลับ ระหว่างการเติมข้อความล่วงหน้าแบบเพิ่มทีละส่วนและการลดสัญญาณรบกวน โมเดล Gemma 4 26B A4B ไม่ได้ ใช้โดยตรง แต่ได้รับการปรับแต่งเพื่อรองรับงานต่างๆ ของการลดสัญญาณรบกวนและ การเข้ารหัส แทนที่จะใช้โมเดลแยกกัน Backbone เดียวจะสลับระหว่าง 2 โหมดแบบไดนามิก
- การป้อนข้อมูลล่วงหน้า / การป้อนข้อมูลล่วงหน้าแบบเพิ่ม (เชิงสาเหตุ): ใช้ความสนใจเชิงสาเหตุเพื่อส่งผ่านบริบทของพรอมต์และเขียนไปยังแคช KV โดยจะทำงาน 1 ครั้งเพื่อป้อนข้อมูลล่วงหน้าในบริบทเริ่มต้น จากนั้นจะทำงาน 1 ครั้งต่อบล็อกเพื่อผนวก Canvas ที่มีโทเค็น 256 รายการที่เสร็จสมบูรณ์แล้วแต่ละรายการไปยังแคช KV ก่อนที่จะดำเนินการลดสัญญาณรบกวนใน Canvas ถัดไป
- การลดสัญญาณรบกวน (แบบสองทิศทาง): ใช้การสนใจแบบสองทิศทางเพื่อลดสัญญาณรบกวนใน Canvas ซ้ำๆ โทเค็นคำค้นหาที่ตำแหน่งใดก็ได้ใน Canvas สามารถสนใจโทเค็นอื่นๆ ทั้งหมดใน Canvas (รวมถึงแคช KV) ทำให้โมเดลประมวลผลบริบทแบบสองทิศทางได้
เฟรมเวิร์กการอนุมานขั้นสูง
DiffusionGemma ใช้ ชุดระบบการถอดรหัสพื้นฐานเพื่อเปลี่ยนภาพวาดจากสัญญาณรบกวนล้วนๆ ให้เป็นข้อความที่เสร็จสมบูรณ์
การปรับสภาพตนเอง
ในระหว่างการอนุมาน ตัวถอดรหัส (หรือที่เรียกว่าตัวลดสัญญาณรบกวน) จะคงสถานะก่อนหน้าไว้ หลังจากทำขั้นตอนการลดสัญญาณรบกวนแล้ว โมเดลจะคูณเมทริกซ์การกระจายความน่าจะเป็นที่สร้างขึ้น กับตารางการฝังโทเค็น ซึ่งจะสร้าง การแสดงเวกเตอร์ที่แปลเป็นภาษาท้องถิ่นซึ่งมีหน่วยความจำของการคาดการณ์ก่อนหน้าและ เมตริกความเชื่อมั่น ซึ่งจะส่งไปยังขั้นตอนถัดไปโดยตรง
การสุ่มตัวอย่างแบบหลาย Canvas (การแพร่กระจายแบบบล็อก)
เนื่องจาก Canvas เดียวจะจำกัดไว้ที่ 256 โทเค็น DiffusionGemma จึงเชื่อมโยง Diffusion และการถดถอยอัตโนมัติเข้าด้วยกันสำหรับข้อความแบบยาว โดยจะเรียกใช้วงจรการแพร่กระจายเพื่อ สร้างบล็อกโทเค็น 256 รายการที่สมบูรณ์ ผนวกบล็อกที่เสร็จสมบูรณ์นั้นเข้ากับบริบทของพรอมต์ อัปเดตแคช KV ของตัวเข้ารหัส และเริ่มวงจรการแพร่กระจายของ Canvas ที่มีโทเค็น 256 รายการใหม่
สรุป
โมเดลภาษาแบบถดถอยอัตโนมัติมาตรฐานจะสร้างข้อความตามลำดับ (ทีละโทเค็น) ซึ่งทำให้โมเดลดังกล่าวต้องใช้หน่วยความจำและสร้างจุดคอขวดด้านเวลาในการตอบสนองสำหรับผู้ใช้แต่ละราย DiffusionGemma แก้ปัญหานี้ด้วยการเปลี่ยนไปใช้โมเดลที่ต้องใช้การคำนวณซึ่งสร้าง "Canvas" แบบ 256 โทเค็นพร้อมกัน
โมเดลจะแทนที่ข้อความด้วยสัญญาณรบกวนคำศัพท์แบบสุ่มและปรับแต่งทั้ง Canvas ซ้ำๆ แบบขนานโดยใช้ Uniform State Diffusion โดยใช้ Gemma 4 26B A4B ที่ปรับแต่งมาอย่างละเอียดเพื่อรองรับงานต่างๆ ในการลดสัญญาณรบกวนและ การเข้ารหัส เฟรมเวิร์กขั้นสูง เช่น การปรับสภาพด้วยตนเอง การสุ่มตัวอย่างบล็อกหลาย Canvas ช่วยให้โมเดลแก้ไขข้อผิดพลาดแบบไดนามิก จัดการการสร้างเนื้อหารูปแบบยาว และบรรลุเวลาในการตอบสนองของผู้ใช้คนเดียวที่ต่ำมาก