
Gemma 3n هو نموذج ذكاء اصطناعي توليدي محسَّن للاستخدام في الأجهزة اليومية، مثل الهواتف المحمولة وأجهزة الكمبيوتر المحمول والأجهزة اللوحية. يتضمّن هذا النموذج ابتكارات في المعالجة الفعّالة للمَعلمات، بما في ذلك ميزة "التضمين لكل طبقة" (PLE) لميزة التخزين المؤقت للمَعلمات وبنية نموذج MatFormer التي توفّر المرونة اللازمة لمحاولة تقليل متطلبات الحوسبة والذاكرة. تتعامل هذه النماذج مع الإدخال الصوتي، بالإضافة إلى البيانات النصية والمرئية.
تتضمّن Gemma 3n الميزات الرئيسية التالية:
- إدخال الصوت: معالجة بيانات الصوت للتعرّف على الكلام والترجمة وتحليل بيانات الصوت مزيد من المعلومات
- الإدخال المرئي والنصوص: تتيح لك إمكانات الوسائط المتعددة التعامل مع الرؤية والصوت والنص لمساعدتك في فهم العالم من حولك وتحليله. مزيد من المعلومات
- برنامج ترميز الرؤية: يعمل برنامج ترميز MobileNet-V5 العالي الأداء على تحسين سرعة ودقة معالجة البيانات المرئية بشكل كبير. مزيد من المعلومات
- التخزين المؤقت لمَعلمات PLE: يمكن تخزين مَعلمات PLE (التضمين حسب الطبقة) المضمّنة في هذه النماذج مؤقتًا في مساحة تخزين محلية سريعة لتقليل التكاليف المتعلّقة بتشغيل الذاكرة في النموذج. مزيد من المعلومات
- بنية MatFormer: تسمح بنية Matryoshka Transformer بتنشيط اختياري لمَعلمات النماذج لكل طلب من أجل تقليل تكلفة الحساب ووقت الاستجابة. مزيد من المعلومات
- تحميل المَعلمات الشَرطية: يمكنك تخطّي تحميل مَعلمات الرؤية والصوت في النموذج لتقليل إجمالي عدد المَعلمات المحمَّلة وحفظ موارد الذاكرة. مزيد من المعلومات
- إتاحة لغات متعددة: إمكانات لغوية واسعة النطاق، تم تدريبها على أكثر من 140 لغة
- سياق الرموز المميزة التي تبلغ 32 ألف رمز: سياق إدخال أساسي لتحليل البيانات ومعالجة المهام.
تجربة Gemma 3n الحصول عليها من Kaggle الحصول عليها من Hugging Face
كما هو الحال مع نماذج Gemma الأخرى، يتم توفير Gemma 3n بأوزان مفتوحة ويُسمح باستخدامهاتجاريًا بشكل مسؤول، ما يتيح لك ضبطها ونشرها في مشاريعك وتطبيقاتك.
مَعلمات النموذج والمَعلمات الفعّالة
يتم إدراج طُرز Gemma 3n مع أعداد المَعلمات، مثل E2B و
E4B، التي تكون أدنى من إجمالي عدد المَعلمات الواردة في
الطُرز. تشير البادئة E إلى أنّ هذه النماذج يمكن أن تعمل باستخدام مجموعة مُعدَّلة
من المَعلمات الفعّالة. يمكن تحقيق هذا الإجراء المنخفض للمَعلمات باستخدام
تكنولوجيا المَعلمات المرنة المضمّنة في نماذج Gemma 3n لمساعدتها على العمل
بكفاءة على الأجهزة ذات الموارد المنخفضة.
تنقسم المَعلمات في نماذج Gemma 3n إلى 4 مجموعات رئيسية: مَعلمات النص والمرئيات والصوت و"التضمين لكل طبقة" (PLE). عند تنفيذ نموذج E2B بشكل عادي، يتم تحميل أكثر من 5 مليارات مَعلمة عند تنفيذ النموذج. ومع ذلك، باستخدام تقنيات تخطّي المَعلمات وتخزين PLE، يمكن تشغيل هذا النموذج مع تحميل ذاكرة فعّال يقلّ قليلاً عن مليارَي (1.91 مليار) مَعلمة، كما هو موضّح في الشكل 1.
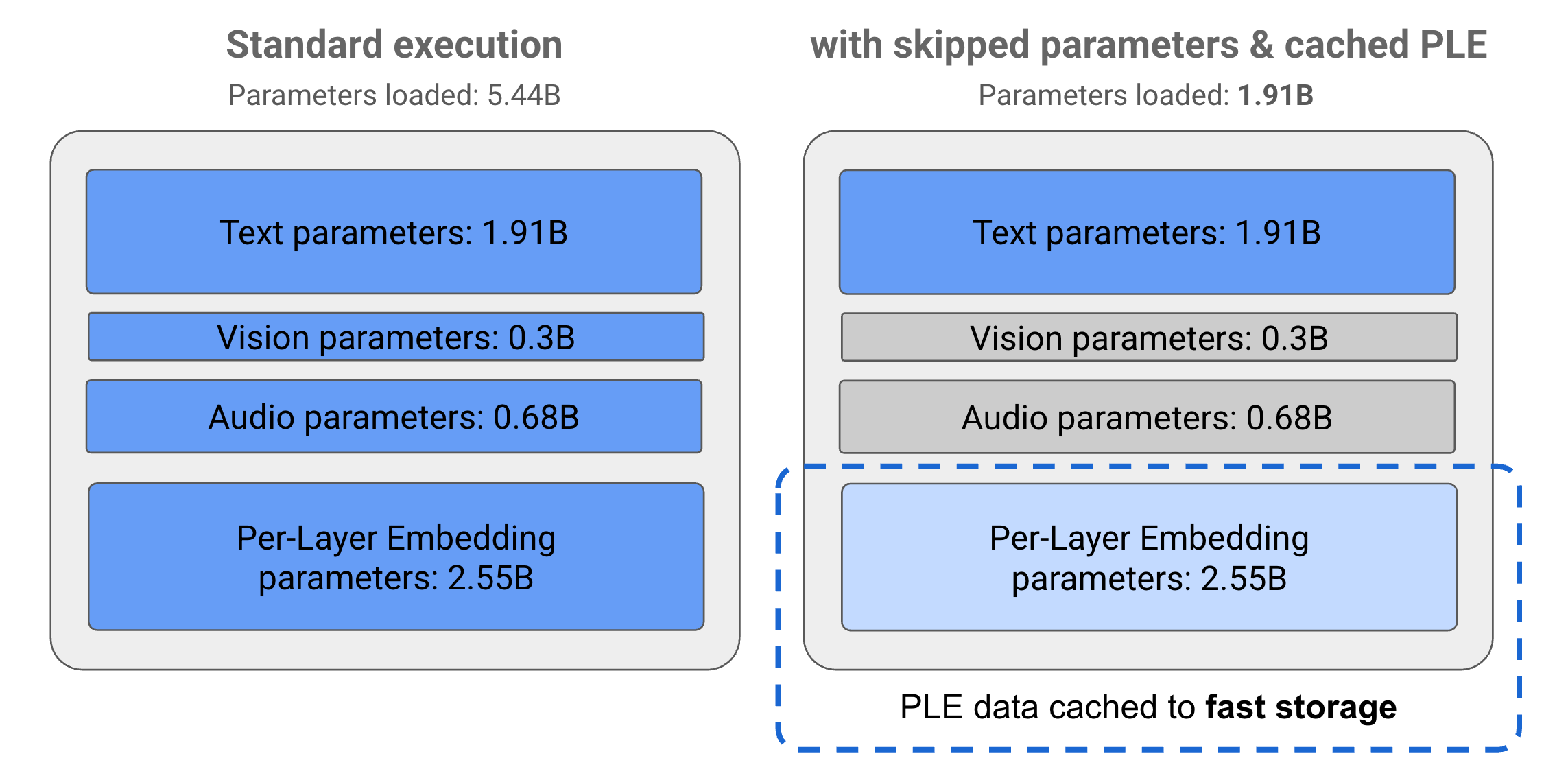
الشكل 1: مَعلمات نموذج Gemma 3n E2B التي يتم تنفيذها بشكل عادي مقارنةً بتحميل مَعلمات أقل فعالية باستخدام تقنيات تخزين PLE المؤقت وتخطّي المَعلمات
باستخدام تقنيات تفريغ المَعلمات وتفعيلها بشكل انتقائي، يمكنك تشغيل النموذج باستخدام مجموعة بسيطة جدًا من المَعلمات أو تفعيل مَعلمات إضافية للتعامل مع أنواع البيانات الأخرى، مثل المحتوى المرئي والمسموع. تتيح لك هذه الميزات زيادة وظائف النموذج أو خفض إمكاناته استنادًا إلى إمكانات الجهاز أو متطلبات المهمة. توضّح الأقسام التالية المزيد حول التقنيات الفعّالة للمَعلمات المتاحة في نماذج Gemma 3n.
التخزين المؤقت لـ PLE
تتضمّن نماذج Gemma 3n مَعلمات "التضمين لكل طبقة" (PLE) التي يتم استخدامها أثناء تنفيذ النموذج لإنشاء بيانات تحسِّن أداء كل طبقة من طبقات النموذج. يمكن إنشاء بيانات PLE بشكل منفصل، خارج ذاكرة التشغيل للنموذج، وتخزينها مؤقتًا في مساحة تخزين سريعة، ثم إضافتها إلى عملية استنتاج النموذج أثناء تشغيل كل طبقة. يتيح هذا النهج إبقاء مَعلمات PLE خارج مساحة ذاكرة النموذج، ما يقلل من استهلاك الموارد مع مواصلة تحسين جودة استجابة النموذج.
بنية MatFormer
تستخدِم نماذج Gemma 3n بنية نموذج Matryoshka Transformer أو MatFormer التي تحتوي على نماذج أصغر مُدمجة ضمن نموذج واحد أكبر. يمكن استخدام النماذج الفرعية المُدمجة لإجراء الاستنتاجات بدون تفعيل مَعلمات نماذج التضمين عند الردّ على الطلبات. إنّ هذه القدرة على تشغيل نماذج أساسية أصغر حجمًا فقط ضمن نموذج MatFormer يمكن أن تقلّل من تكلفة الحوسبة ووقت الاستجابة واستهلاك الطاقة للنموذج. في حالة Gemma 3n، يحتوي ملف تعريف E4B على مَعلمات ملف تعريف E2B. تتيح لك هذه البنية أيضًا اختيار المَعلمات وتجميع النماذج بأحجام متوسطة تتراوح بين 2B و4B. لمزيد من التفاصيل حول هذا النهج، يُرجى الاطّلاع على مقالة البحث MatFormer. جرِّب استخدام تقنيات MatFormer لتقليل حجم نموذج Gemma 3n باستخدام دليل MatFormer Lab.
تحميل المَعلمات الشَرطية
على غرار مَعلمات PLE، يمكنك تخطّي تحميل بعض المَعلمات إلى الذاكرة، مثل المَعلمات الصوتية أو المرئية، في نموذج Gemma 3n لتقليل عبء الذاكرة. يمكن تحميل هذه المَعلمات ديناميكيًا أثناء التشغيل إذا كان الجهاز يتضمّن الموارد المطلوبة. بشكل عام، يمكن أن يؤدي تخطّي المَعلمات إلى تقليل سعة ذاكرة التشغيل المطلوبة لنموذج Gemma 3n بشكلٍ أكبر، ما يتيح التنفيذ على نطاق أوسع من الأجهزة ويسمح للمطوّرين بزيادة كفاءة الموارد للمهام الأقل تطلبًا.
هل أنت على استعداد لبدء إنشاء الأدوات؟
البدء
باستخدام نماذج Gemma