
많은 기업에서 이를 효과적으로 사용하기 위해서는 특정 음성 언어로 인공지능 (AI) 기술을 사용하는 것이 매우 중요합니다. Gemma 모델 제품군에는 다국어 기능이 있지만 영어가 아닌 언어로 사용하면 이상적인 결과가 나오지 않는 경우가 많습니다.
다행히 Gemma에게 해당 언어로 작업을 완료할 수 있도록 전체 언어를 가르치지 않아도 됩니다. 또한 Gemma 모델을 조정하여 언어에서 특정 작업을 생각하는 것보다 훨씬 적은 데이터와 노력으로 완료할 수 있습니다. 타겟 언어로 약 20개의 요청 예시와 예상 응답을 사용하면 Gemma를 통해 나와 내 고객에게 가장 적합한 언어로 다양한 비즈니스 문제를 해결할 수 있습니다.
프로젝트를 만든 사람들의 통찰력을 포함하여 프로젝트에 대한 개요와 확장 방법을 보려면 음성 언어 AI 어시스턴트 Google AI로 빌드 동영상을 확인하세요. Gemma Cookbook 코드 저장소에서 이 프로젝트의 코드를 검토할 수도 있습니다. 또는 다음 안내에 따라 프로젝트 확장을 시작할 수 있습니다.
개요
이 튜토리얼에서는 Gemma와 Python으로 빌드된 음성 언어 태스크 애플리케이션을 설정, 실행, 확장하는 방법을 안내합니다. 애플리케이션은 필요에 맞게 수정할 수 있는 기본 웹 사용자 인터페이스를 제공합니다. 이 애플리케이션은 가상의 한국 빵집의 고객 이메일에 대한 답장을 생성하도록 빌드되었으며 모든 언어 입력과 출력은 전적으로 한국어로 처리됩니다. 이 애플리케이션 패턴은 텍스트 입력과 텍스트 출력을 사용하는 모든 언어와 비즈니스 작업에 사용할 수 있습니다.
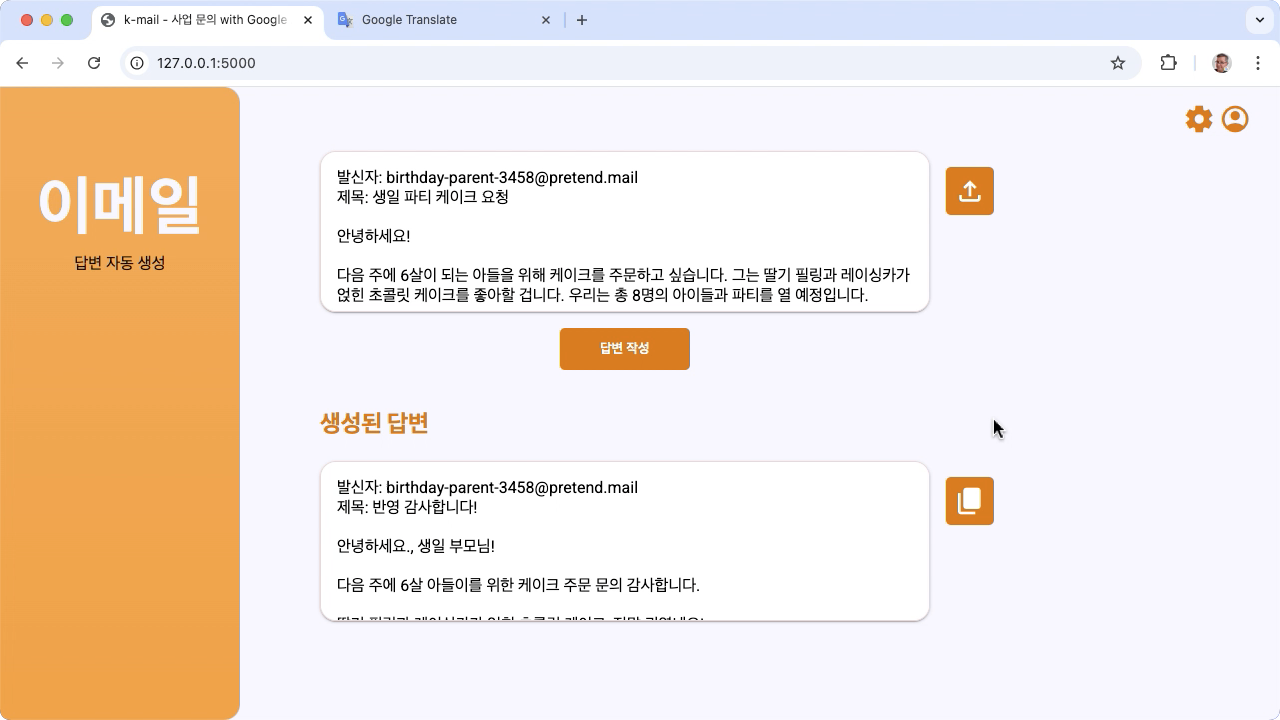
그림 1. 한국 베이커리 이메일 문의를 위한 프로젝트 사용자 인터페이스
하드웨어 요구사항
그래픽 처리 장치(GPU) 또는 Tensor Processing Unit(TPU)과 기존 모델과 조정 데이터를 저장할 수 있는 충분한 메모리가 있는 컴퓨터에서 이 조정 프로세스를 실행합니다. 이 프로젝트에서 조정 구성을 실행하려면 약 16GB의 GPU 메모리, 약 같은 양의 일반 RAM, 최소 50GB의 디스크 공간이 필요합니다.
T4 GPU 런타임이 있는 Colab 환경을 사용하여 이 튜토리얼의 Gemma 모델 조정 부분을 실행할 수 있습니다. Google Cloud VM 인스턴스에서 이 프로젝트를 빌드하는 경우 다음 요구사항에 따라 인스턴스를 구성하세요.
- GPU 하드웨어: 이 프로젝트를 실행하려면 NVIDIA T4가 필요하며 NVIDIA L4 이상이 권장됩니다.
- 운영체제: Linux용 딥 러닝 옵션, 특히 GPU 소프트웨어 드라이버가 사전 설치된 CUDA 12.3 M124가 포함된 딥 러닝 VM을 선택합니다.
- 부팅 디스크 크기: 데이터, 모델, 지원 소프트웨어를 위해 50GB 이상의 디스크 공간을 프로비저닝합니다.
프로젝트 설정
이 안내에서는 이 프로젝트를 개발 및 테스트할 준비를 하는 방법을 안내합니다. 일반적인 설정 단계에는 기본 소프트웨어 설치, 코드 저장소에서 프로젝트 클론, 몇 가지 환경 변수 설정, Python 라이브러리 설치, 웹 애플리케이션 테스트가 포함됩니다.
설치 및 구성
이 프로젝트는 Python 3 및 가상 환경(venv)을 사용하여 패키지를 관리하고 애플리케이션을 실행합니다. 다음은 Linux 호스트 머신용 설치 안내입니다.
필수 소프트웨어를 설치하려면 다음 단계를 따르세요.
Python 3과 Python용
venv가상 환경 패키지를 설치합니다.sudo apt update sudo apt install git pip python3-venv
프로젝트 클론
프로젝트 코드를 개발 컴퓨터에 다운로드합니다. 프로젝트 소스 코드를 가져오려면 git 소스 제어 소프트웨어가 필요합니다.
프로젝트 코드를 다운로드하는 방법은 다음과 같습니다.
다음 명령어를 사용하여 git 저장소를 클론합니다.
git clone https://github.com/google-gemini/gemma-cookbook.git원하는 경우 프로젝트의 파일만 포함되도록 스파스 체크아웃을 사용하도록 로컬 git 저장소를 구성합니다.
cd gemma-cookbook/ git sparse-checkout set Demos/spoken-language-tasks/ git sparse-checkout init --cone
Python 라이브러리 설치
Python 패키지 및 종속 항목을 관리하기 위해 venv Python 가상 환경을 활성화한 상태에서 Python 라이브러리를 설치합니다. pip 설치 프로그램으로 Python 라이브러리를 설치하기 전에 Python 가상 환경을 활성화해야 합니다. Python 가상 환경 사용에 관한 자세한 내용은 Python venv 문서를 참고하세요.
Python 라이브러리를 설치하려면 다음 단계를 따르세요.
터미널 창에서
spoken-language-tasks디렉터리로 이동합니다.cd Demos/spoken-language-tasks/이 프로젝트의 Python 가상 환경 (venv)을 구성하고 활성화합니다.
python3 -m venv venv source venv/bin/activatesetup_python스크립트를 사용하여 이 프로젝트에 필요한 Python 라이브러리를 설치합니다../setup_python.sh
환경 변수 설정하기
Kaggle 사용자 이름 및 Kaggle 토큰 키를 비롯하여 이 코드 프로젝트를 실행하는 데 필요한 몇 가지 환경 변수를 설정합니다. Gemma 모델을 다운로드하려면 Kaggle 계정이 있어야 하고 Gemma 모델에 대한 액세스 권한을 요청해야 합니다. 이 프로젝트에서는 웹 애플리케이션과 조정 프로그램에서 각각 읽는 두 개의 .env 파일에 Kaggle 사용자 이름과 Kaggle 토큰 키를 추가합니다.
환경 변수를 설정하려면 다음 안내를 따르세요.
- Kaggle 문서의 안내에 따라 Kaggle 사용자 이름과 토큰 키를 가져옵니다.
- Gemma 설정 페이지의 Gemma 액세스 권한 얻기 안내에 따라 Gemma 모델에 액세스합니다.
- 프로젝트 클론의 다음 위치 각각에
.env텍스트 파일을 만들어 프로젝트의 환경 변수 파일을 만듭니다.k-mail-replier/k_mail_replier/.env k-gemma-it/.env
.env텍스트 파일을 만든 후 두 파일에 다음 설정을 추가합니다.KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
애플리케이션 실행 및 테스트
프로젝트 설치 및 구성을 완료한 후 웹 애플리케이션을 실행하여 올바르게 구성했는지 확인합니다. 사용할 프로젝트를 편집하기 전에 이 작업을 기준으로 이 작업을 수행해야 합니다.
프로젝트를 실행하고 테스트하려면 다음 단계를 따르세요.
터미널 창에서
/k_mail_replier/디렉터리로 이동합니다.cd spoken-language-tasks/k-mail-replier/run_flask_app.sh스크립트를 사용하여 애플리케이션을 실행합니다../run_flask_app.sh웹 애플리케이션을 시작한 후 프로그램 코드에는 탐색하고 테스트할 수 있는 URL이 표시됩니다. 일반적으로 이 주소는 다음과 같습니다.
http://127.0.0.1:5000/웹 인터페이스에서 첫 번째 입력 필드 아래에 있는 작업 작성 버튼을 눌러 모델에서 응답을 생성합니다.
애플리케이션을 실행한 후 모델의 첫 번째 응답은 첫 번째 생성 실행에서 초기화 단계를 완료해야 하므로 더 오래 걸립니다. 이미 실행 중인 웹 애플리케이션에서 후속 프롬프트 요청 및 생성이 더 짧은 시간에 완료됩니다.
애플리케이션 확장
애플리케이션을 실행한 후 사용자 인터페이스와 비즈니스 로직을 수정하여 나 또는 내 비즈니스와 관련된 작업에 맞게 애플리케이션을 확장할 수 있습니다. 애플리케이션이 생성형 AI 모델로 보내는 프롬프트의 구성요소를 변경하여 애플리케이션 코드를 통해 Gemma 모델의 동작을 수정할 수도 있습니다.
애플리케이션은 사용자의 입력 데이터와 함께 모델에 지침을 제공하여 모델의 전체 프롬프트를 완성합니다. 이러한 안내를 수정하여 모델의 동작을 변경할 수 있습니다. 예를 들어 모델이 요청에서 정보를 추출하여 JSON과 같은 구조화된 데이터 형식으로 저장하도록 지정할 수 있습니다. 모델의 동작을 변경하는 더 간단한 방법은 생성된 답글을 정중한 어조로 작성해야 한다고 지정하는 등 모델의 응답에 관한 추가 안내나 안내를 제공하는 것입니다.
프롬프트 안내를 수정하려면 다음 단계를 따르세요.
- spoken-language-task 프로젝트에서
k-mail-replier/k_mail_replier/app.py코드 파일을 엽니다. app.py코드에서get_prompt():함수에 추가 안내를 추가합니다.def get_prompt(): return "발신자에게 요청에 대한 감사를 전하고, 곧 자세한 내용을 알려드리겠다고 정중하게 답장해 주세요. 정중하게 답변해 주세요!:\n"
이 예에서는 한국어 안내에 '정중한 답변을 작성하세요'라는 문구를 추가합니다.
프롬프트 안내를 추가하면 생성된 출력물에 큰 영향을 미칠 수 있으며 구현하는 데 훨씬 적은 노력이 듭니다. 먼저 이 메서드를 시도하여 모델에서 원하는 동작을 가져올 수 있는지 확인해야 합니다. 하지만 프롬프트 안내를 사용하여 Gemma 모델의 동작을 수정하는 데는 한계가 있습니다. 특히 모델의 전체 입력 토큰 한도(Gemma 2의 경우 8,192개 토큰)를 준수하려면 자세한 프롬프트 안내와 제공하는 새 데이터의 크기 간에 균형을 맞춰야 합니다.
또한 Gemma가 영어가 아닌 다른 언어로 작업을 실행하도록 하려면 기본 모델에 메시지를 표시하는 것만으로는 유용하고 안정적인 결과를 얻을 수 없습니다. 대신 대상 언어의 예시를 사용하여 모델을 조정하고 그런 다음 프롬프트 안내를 수정하여 조정된 모델의 출력을 더 세부적으로 조정하는 것이 좋습니다.
모델 조정
Gemma 모델을 미세 조정하면 영어가 아닌 다른 언어로 효과적으로 응답하도록 할 수 있습니다. 하지만 모델이 해당 언어로 작업을 완료할 수 있도록 하기 위해 도착어를 완전히 유창하게 구사할 필요는 없습니다. 약 20개의 예시를 통해 타겟 언어로 태스크의 기본 기능을 실행할 수 있습니다. 이 튜토리얼 섹션에서는 특정 언어로 특정 작업을 위해 Gemma 모델에서 미세 조정을 설정하고 실행하는 방법을 설명합니다.
다음 안내는 VM 환경에서 미세 조정 작업을 실행하는 방법을 설명하지만 이 프로젝트와 연결된 Colab 노트북을 사용하여 이 조정 작업을 실행할 수도 있습니다.
하드웨어 요구사항
미세 조정을 위한 컴퓨팅 요구사항은 나머지 프로젝트의 하드웨어 요구사항과 동일합니다. 입력 토큰을 256개로, 일괄 크기를 1로 제한하면 T4 GPU 런타임이 있는 Colab 환경에서 조정 작업을 실행할 수 있습니다.
데이터 준비
Gemma 모델 조정을 시작하기 전에 조정 데이터를 준비해야 합니다. 특정 태스크 및 언어에 맞게 모델을 조정할 때는 해당 타겟 언어로 된 일련의 요청 및 응답 예가 필요합니다. 이러한 예에서는 안내 없이 요청 텍스트와 예상 응답 텍스트를 보여주어야 합니다. 먼저 약 20개의 예시로 데이터 세트를 준비해야 합니다. 이러한 예는 다양한 요청과 이상적인 응답을 나타내야 합니다. 요청과 응답이 반복되지 않도록 합니다. 요청과 응답이 반복되면 모델 응답이 반복되고 요청의 변화에 적절하게 조정되지 않을 수 있습니다. 다음 표에는 이 코드 예의 데이터 세트에서 가져온 몇 가지 샘플 레코드가 나와 있습니다.
| 요청 | 응답 |
|---|---|
| 안녕하세요, 2주 뒤에 있을 아이 생일을 위해 3호 케이크 3개를 주문하고 싶은데 가능할까요? | 참여해 주셔서 감사합니다. 2주 뒤 아이 생일을 위한 3호 케이크 2개 주문 문의 감사합니다. 네, 3호 케이크 2개 주문 가능합니다. 아이 생일 케이크와 같이 더 많이 써서 정성을 준비하겠습니다. 혹시 원하시는 디자인이나 특별한 요청 사항이 있으시면 편하게 말씀해주세요. 픽업 날짜와 시간을 알려주시면 더욱 자세한 안내를 도와드리겠습니다. 다시 한번 문의 감사드리며, 아이 생일 진심으로 축하합니다! [가게 이름] 드림 |
| 안녕하세요, 9월 15일에 있을 아들의 돌잔치를 위해 케이크를 주문하고 싶습니다. - 케이크 종류: 생크림 케이크 - 크기: 2호 - 디자인: 아기자기한 동물 디자인 - 문구: "첫 생일 축하해, 사랑하는 아들!" - 픽업 날짜 및 시간: 9월 14일 오후 3시 가격 및 주문 가능 여부를 알려주시면 감사하겠습니다. 감사합니다. 김민지 드림 | 안녕하세요, 김민지 님, 9월 15일 아드님의 돌잔치를 위한 케이크를 보내주셔서 감사합니다. - 생크림 케이크 2호, 아기자기한 동물 디자인, "첫 생일 축하해, 사랑하는 아들!" 메모, 9월 14일 오후 3시 픽업 모두 가능합니다. - 가격은 5만원입니다. 주문을 원하시면 연락 주세요 감사합니다. [가게 이름] 드림 |
표 1. 한국 베이커리 이메일 응답자의 조정 데이터 세트의 일부 목록
데이터 형식 및 로드
Python 코드로 레코드를 검색할 수 있는 수단이 있다면 데이터베이스 레코드, JSON 파일, CSV 또는 일반 텍스트 파일 등 편리한 형식으로 조정 데이터를 저장할 수 있습니다. 편의를 위해 예시 조정 프로그램은 온라인 저장소에서 레코드를 가져옵니다.
이 예시에서는 prepare_tuning_dataset() 함수를 사용하여 튜닝 데이터 세트가 k-gemma-it/main.py 모듈에 로드됩니다.
def prepare_tuning_dataset():
tokenizer = keras_nlp.models.GemmaTokenizer.from_preset(model_id)
# load data from repository (or local directory)
from datasets import load_dataset
ds = load_dataset(
# Dataset : https://huggingface.co/datasets/bebechien/korean_cake_boss
"bebechien/korean_cake_boss",
split="train",
)
...
앞서 언급한 바와 같이 연결된 응답과 함께 요청을 검색하고 이를 조정 레코드로 사용되는 텍스트 문자열로 조합할 수 있다면 편리한 형식으로 데이터 세트를 저장할 수 있습니다.
조정 레코드 조합
실제 조정 프로세스의 경우 각 요청과 응답은 프롬프트 안내와 태그를 사용하여 단일 문자열로 조합되어 요청의 콘텐츠와 응답의 콘텐츠를 나타냅니다. 그런 다음 이 조정 프로그램은 모델에서 사용할 문자열을 토큰화합니다. 다음과 같이 k-gemma-it/main.py 모듈 prepare_tuning_dataset() 함수에서 조정 레코드를 조합하는 코드를 확인할 수 있습니다.
def prepare_tuning_dataset():
...
prompt_instruction = "다음에 대한 이메일 답장을 작성해줘."
for x in data:
item = f"<start_of_turn>user\n{prompt_instruction}\n\"{x['input']}\"<end_of_turn>\n<start_of_turn>model\n{x['output']}<end_of_turn>"
length = len(tokenizer(item))
# skip data if the token length is longer than our limit
if length < token_limit:
tuning_dataset.append(item)
if(len(tuning_dataset)>=num_data_limit):
break
...
이 함수는 데이터를 읽고 Gemma 모델 조정을 위한 데이터를 제공할 때 필수 형식인 start_of_turn 및 end_of_turn 태그를 추가하여 형식을 지정합니다. 이 코드는 각 요청에 prompt_instruction도 삽입하며, 이는 애플리케이션에 적절하게 수정해야 합니다.
모델 가중치 생성
조정 데이터를 준비하고 로드했으면 조정 프로그램을 실행할 수 있습니다. 이 예시 애플리케이션의 조정 프로세스는 Keras NLP 라이브러리를 사용하여 Low Rank Adaptation(LoRA) 기법으로 모델을 조정하여 새 모델 가중치를 생성합니다. LoRA를 사용하면 모델 가중치의 변경사항을 근사하므로 전체 정밀도 조정에 비해 메모리가 훨씬 더 효율적입니다. 그런 다음 이러한 근사치 가중치를 기존 모델 가중치에 오버레이하여 모델의 동작을 변경할 수 있습니다.
조정 실행을 수행하고 새 가중치를 계산하려면 다음 안내를 따르세요.
터미널 창에서
k-gemma-it/디렉터리로 이동합니다.cd spoken-language-tasks/k-gemma-it/tune_model스크립트를 사용하여 조정 프로세스를 실행합니다../tune_model.sh
튜닝 프로세스는 사용 가능한 컴퓨팅 리소스에 따라 몇 분 정도 걸립니다. 완료되면 튜닝 프로그램이 다음 형식으로 k-gemma-it/weights 디렉터리에 새 *.h5 가중치 파일을 씁니다.
gemma2-2b_k-tuned_4_epoch##.lora.h5
문제 해결
조정이 완료되지 않는 경우 다음 두 가지 이유가 있을 수 있습니다.
- 메모리 부족 / 리소스 소진: 이 오류는 조정 프로세스에서 사용 가능한 GPU 메모리 또는 CPU 메모리를 초과하는 메모리를 요청할 때 발생합니다. 조정 프로세스가 실행되는 동안 웹 애플리케이션을 실행하지 않아야 합니다. GPU 메모리가 16GB인 기기에서 조정하는 경우
token_limit를 256으로,batch_size를 1로 설정합니다. - GPU 드라이버가 설치되지 않았거나 JAX와 호환되지 않음: 변환 프로세스에는 컴퓨팅 기기에 JAX 라이브러리 버전과 호환되는 하드웨어 드라이버가 설치되어 있어야 합니다. 자세한 내용은 JAX 설치 문서를 참고하세요.
조정된 모델 배포
조정 프로세스는 조정 데이터와 조정 애플리케이션에 설정된 총 에포크 수를 기반으로 여러 가중치를 생성합니다. 기본적으로 조정 프로그램은 조정 에포크마다 하나씩 20개의 모델 가중치 파일을 생성합니다. 연속된 각 조정 에포크는 조정 데이터의 결과를 더 정확하게 재현하는 가중치를 생성합니다. 다음과 같이 조정 프로세스의 터미널 출력에서 각 에포크의 정확도 비율을 확인할 수 있습니다.
...
Epoch 14/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 567ms/step - loss: 0.4026 - sparse_categorical_accuracy: 0.8235
Epoch 15/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 569ms/step - loss: 0.3659 - sparse_categorical_accuracy: 0.8382
Epoch 16/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 571ms/step - loss: 0.3314 - sparse_categorical_accuracy: 0.8538
Epoch 17/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 572ms/step - loss: 0.2996 - sparse_categorical_accuracy: 0.8686
Epoch 18/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 574ms/step - loss: 0.2710 - sparse_categorical_accuracy: 0.8801
Epoch 19/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2451 - sparse_categorical_accuracy: 0.8903
Epoch 20/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2212 - sparse_categorical_accuracy: 0.9021
정확도 비율은 비교적 높아야 하지만(0.80~0.90) 너무 높거나 1.00에 매우 근접해서는 안 됩니다. 가중치가 조정 데이터에 과적합할 수 있기 때문입니다. 이 경우 모델은 조정 예시와 크게 다른 요청에서 제대로 작동하지 않습니다. 기본적으로 배포 스크립트는 일반적으로 정확도 비율이 약 0.90인 에포크 17 가중치를 선택합니다.
생성된 가중치를 웹 애플리케이션에 배포하려면 다음 단계를 따르세요.
터미널 창에서
k-gemma-it/디렉터리로 이동합니다.cd spoken-language-tasks/k-gemma-it/deploy_weights스크립트를 사용하여 조정 프로세스를 실행합니다../deploy_weights.sh
이 스크립트를 실행하면 k-mail-replier/k_mail_replier/weights/ 디렉터리에 새 *.h5 파일이 표시됩니다.
새 모델 테스트
새 가중치를 애플리케이션에 배포했다면 이제 새로 조정된 모델을 사용해 볼 차례입니다. 웹 애플리케이션을 다시 실행하고 응답을 생성하면 됩니다.
프로젝트를 실행하고 테스트하려면 다음 단계를 따르세요.
터미널 창에서
/k_mail_replier/디렉터리로 이동합니다.cd spoken-language-tasks/k-mail-replier/run_flask_app.sh스크립트를 사용하여 애플리케이션을 실행합니다../run_flask_app.sh웹 애플리케이션을 시작한 후 프로그램 코드에는 탐색하고 테스트할 수 있는 URL이 표시됩니다. 일반적으로 이 주소는 다음과 같습니다.
http://127.0.0.1:5000/웹 인터페이스에서 첫 번째 입력란 아래에 있는 답변 작성 버튼을 눌러 모델에서 응답을 생성합니다.
이제 애플리케이션에서 Gemma 모델을 조정하고 배포했습니다. 애플리케이션을 실험하고 태스크에 맞게 조정된 모델의 생성 기능의 한도를 파악해 보세요. 모델이 제대로 작동하지 않는 시나리오를 발견하면 요청을 추가하고 이상적인 응답을 제공하여 이러한 요청 중 일부를 조정 예시 데이터 목록에 추가해 보세요. 그런 다음 조정 프로세스를 다시 실행하고 새 가중치를 다시 배포한 후 출력을 테스트합니다.
추가 리소스
이 프로젝트에 관한 자세한 내용은 Gemma Cookbook 코드 저장소를 참고하세요. 애플리케이션을 빌드하는 데 도움이 필요하거나 다른 개발자와 공동작업하려는 경우 Google 개발자 커뮤니티 Discord 서버를 확인하세요. Build with Google AI 프로젝트에 관한 자세한 내용은 동영상 재생목록을 확인하세요.