
許多企業都需要在特定口語中使用人工智慧 (AI) 技術,才能有效運用這項技術。Gemma 系列模型具備多語言功能,但在英文以外的語言中使用時,經常會產生不理想的結果。
幸好,您不必教 Gemma 整個語言,就能使用該語言完成工作。此外,您可以調整 Gemma 模型,以使用語言完成特定工作,而且使用的資料和心力比想像中還少。只要提供約 20 個目標語言的請求和預期回應範例,Gemma 就能以最適合您和客戶的語言,協助您解決許多不同的業務問題。
有關專案及其延伸方式的影片總覽 (包括建構專案人員的見解),請觀看 Spken Language AI Assistant 「Build with Google AI」(運用 Google AI 建構) 影片。您也可以在 Gemma Cookbook 程式碼存放區中查看這個專案的程式碼。或者,您也可以開始使用下列操作說明來擴充專案。
總覽
本教學課程將逐步引導您設定、執行及擴充使用 Gemma 和 Python 建構的語音語言工作應用程式。此應用程式提供基本的網頁使用者介面,可讓您根據需求進行修改。此應用程式的設計目的是為一家虛構的韓國麵包店產生客戶電子郵件的回覆,且所有語言輸入和輸出作業完全以韓文處理。您可以將此應用程式模式用於任何語言,以及任何使用文字輸入和文字輸出的商務工作。
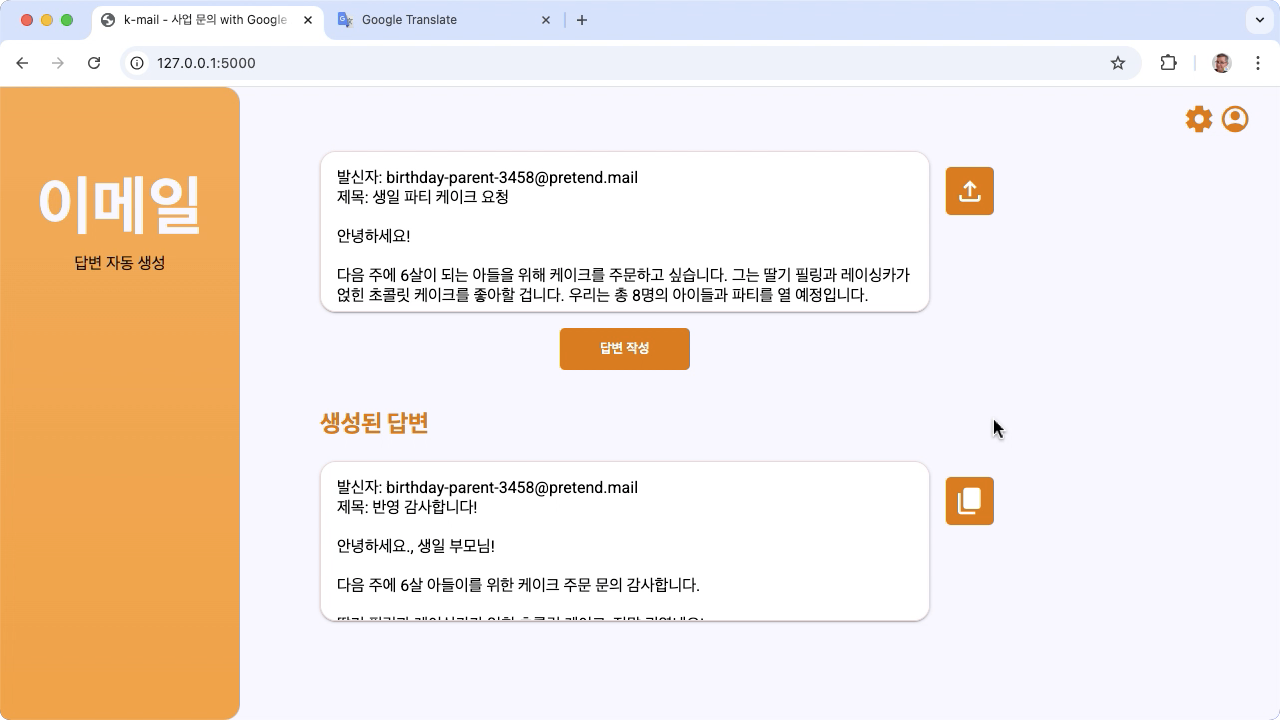
圖 1. 韓國麵包店電子郵件查詢的專案使用者介面
硬體需求
請在搭載圖形處理器 (GPU) 或 Tensor 處理器 (TPU) 的電腦上執行這項調整程序,並確保電腦有足夠的記憶體來儲存現有模型,以及調整資料。如要在這個專案中執行調整設定,您需要約 16 GB 的 GPU 記憶體、約相同容量的一般 RAM,以及至少 50 GB 的磁碟空間。
您可以使用 Colab 環境搭配 T4 GPU 執行階段,執行本教學課程中的 Gemma 模型調整部分。如果您要在 Google Cloud VM 執行個體上建構這個專案,請按照下列規定設定執行個體:
- GPU 硬體:執行這項專案時需要使用 NVIDIA T4,而且建議使用 NVIDIA L4 或以上版本。
- 作業系統:選取「Deep Learning on Linux」選項,特別是「Deep Learning VM with CUDA 12.3 M124」,其中預先安裝了 GPU 軟體驅動程式。
- 開機磁碟大小:為資料、模型和支援軟體預留至少 50 GB 的磁碟空間。
專案設定
這些操作說明將引導您逐步準備這個專案,以便進行開發和測試。一般設定步驟包括安裝必要軟體、從程式碼存放區複製專案、設定一些環境變數、安裝 Python 程式庫,以及測試網路應用程式。
安裝及設定
這個專案會使用 Python 3 和虛擬環境 (venv) 管理套件和執行應用程式。以下安裝操作說明適用於 Linux 主機。
如何安裝必要軟體:
安裝 Python 3 和 Python 適用的
venv虛擬環境套件。sudo apt update sudo apt install git pip python3-venv
複製專案
將專案程式碼下載到開發電腦。您需要使用 git 原始碼管控軟體,才能擷取專案原始碼。
下載專案程式碼的方式如下:
使用下列指令複製 Git 存放區。
git clone https://github.com/google-gemini/gemma-cookbook.git您可以選擇將本機 Git 存放區設定為使用稀疏檢出功能,這樣您就只會取得專案的檔案。
cd gemma-cookbook/ git sparse-checkout set Demos/spoken-language-tasks/ git sparse-checkout init --cone
安裝 Python 程式庫
啟用 venv Python 虛擬環境,安裝 Python 程式庫,以便管理 Python 套件和依附元件。請務必先使用 pip 安裝程式啟用 Python 虛擬環境,再安裝 Python 程式庫。如要進一步瞭解如何使用 Python 虛擬環境,請參閱 Python venv 說明文件。
如何安裝 Python 程式庫:
在終端機視窗中,前往
spoken-language-tasks目錄:cd Demos/spoken-language-tasks/為此專案設定及啟用 Python 虛擬環境 (venv):
python3 -m venv venv source venv/bin/activate使用
setup_python指令碼,為這個專案安裝必要的 Python 程式庫。./setup_python.sh
設定環境變數
設定幾個環境變數,讓這個程式碼專案可以執行,包括 Kaggle 使用者名稱和 Kaggle 權杖金鑰。您必須擁有 Kaggle 帳戶,並要求 Gemma 模型的存取權,才能下載這些模型。針對這個專案,您將 Kaggle 使用者名稱和 Kaggle 權杖金鑰新增至兩個 .env 檔案,分別由網頁應用程式和調校程式讀取。
如要設定環境變數,請按照下列步驟操作:
- 按照 Kaggle 說明文件中的指示,取得 Kaggle 使用者名稱和符記金鑰。
- 如要取得 Gemma 模型的存取權,請按照「Gemma 設定」頁面中的「取得 Gemma 存取權」操作說明操作。
- 在專案複本的每個位置建立
.env文字檔案,為專案建立環境變數檔案:k-mail-replier/k_mail_replier/.env k-gemma-it/.env
建立
.env文字檔後,請在兩個檔案中新增下列設定:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
執行及測試應用程式
完成專案的安裝和設定後,請執行網頁應用程式,確認設定正確無誤。您應先執行這項操作,做為基準檢查,然後再編輯專案供自己使用。
如要執行及測試專案,請按照下列步驟操作:
在終端機視窗中,前往
/k_mail_replier/目錄:cd spoken-language-tasks/k-mail-replier/使用
run_flask_app.sh指令碼執行應用程式:./run_flask_app.sh啟動網頁應用程式後,程式碼會列出可供您瀏覽及測試的網址。這個地址通常是:
http://127.0.0.1:5000/在網頁介面中,按下第一個輸入欄位下方的「답변 작성」按鈕,即可透過模型產生回覆。
執行應用程式後,模型的第一個回應會花費較長時間,因為它必須在第一次執行時完成初始化步驟。在已執行的網路應用程式上,後續提示要求和產生作業會在更短的時間內完成。
擴充應用程式
應用程式開始執行後,您可以修改使用者介面和商業邏輯,藉此擴充應用程式,讓應用程式可執行與您或貴商家相關的作業。您也可以使用應用程式程式碼修改 Gemma 模型的行為,方法是變更應用程式傳送至生成式 AI 模型的提示內容。
應用程式會提供模型的操作說明,以及使用者輸入的完整模型提示。您可以修改這些指示,以變更模型的行為,例如指定模型應從要求中擷取資訊,並將資訊放入結構化資料格式,例如 JSON。變更模型行為的更簡單方式,就是為模型的回應提供額外指示或指引,例如指定產生的回覆應以友善語氣撰寫。
如要修改提示操作說明,請按照下列步驟操作:
- 在語言任務專案中,開啟
k-mail-replier/k_mail_replier/app.py程式碼檔案。 在
app.py程式碼中,將附加指示新增至get_prompt():函式:def get_prompt(): return "발신자에게 요청에 대한 감사를 전하고, 곧 자세한 내용을 알려드리겠다고 정중하게 답장해 주세요. 정중하게 답변해 주세요!:\n"
這個範例會在韓文說明中加入「Please write a polite response!」(請寫出禮貌的回覆!) 這句話。
提供額外的提示操作說明,可大幅影響產生的輸出內容,且實作所需的努力程度也較低。建議您先嘗試使用這個方法,看看是否能透過模型取得所需的行為。不過,使用提示指令修改 Gemma 模型的行為有其限制。具體來說,模型的整體輸入符代碼限制 (Gemma 2 為 8,192 個符代碼) 要求您在詳細提示指示和提供的新資料大小之間取得平衡,以便維持在該限制以下。
此外,如果您希望 Gemma 以英文以外的語言執行工作,只提示基礎模型可能無法產生可靠且實用的結果。相反地,您應使用目標語言的範例調整模型,然後再考慮修改提示指示,以便對已調整模型的輸出內容進行微調。
調整模型
建議您對 Gemma 模型進行微調,讓模型以英語以外的口語回應。不過,您不必完全精通目標語言,模型就能以該語言完成工作。您可以使用目標語言完成約 20 個範例的任務,以便實現基本功能。教學課程的本節說明如何使用特定語言,針對特定工作設定及執行 Gemma 模型並進行微調。
以下指示說明如何在 VM 環境中執行微調作業,不過您也可以使用與這項專案相關聯的 Colab 筆記本執行這項調整作業。
硬體需求
精細調整的運算需求與專案其餘部分的硬體需求相同。如果將輸入符記限制為 256,並將批量限制在 1,即可在 Colab 環境中使用 T4 GPU 執行階段執行調整作業。
準備資料
開始調整 Gemma 模型前,您必須先準備調整資料。針對特定工作和語言微調模型時,您需要該目標語言的一組要求和回應範例。這些範例應顯示要求文字 (不含任何操作說明) 和預期的回應文字。首先,您應該使用約 20 個範例準備資料集。這些範例應代表各種要求和理想的回應。請確認要求和回應不會重複,否則可能會導致模型回應重複,也無法配合要求變化版本適當調整。下表列出本程式碼範例資料集內的幾筆記錄範例:
| 要求 | 回應 |
|---|---|
| 안녕하세요, 2주 뒤에 있을 아이 생일을 위해 3호 케이크 3개를 주문하고 싶은데 가능할까요? | 牛江社區2주 뒤 아이 생일을 위한 3호 케이크 2개 주문 문의 감사합니다. 네, 3 안 케이해 相片庫능空格。卡願意픽업 날짜와 시간을 알려주시면 더욱 자세한 안내를 도와드리겠습니다. 百貨專線[familyery 이름] 更換 :[림] |
| 안녕하세요, 9월 15일에 있을 아들의 돌잔치를 위해 케이크를 주문하고 싶습니다. - 케이크 종류: 생크림 케이크 - 크기: 2호 - 디자인: 아기자기한 동물 디자인 - 문구: "첫 생일 축하해, 사랑하는 아들!" - 픽업 날짜 및 시간: 9월 14일 오후 3시 가격 및 주문 가능 여부를 알려주시면 감사하겠습니다. 감사합니다. 김민지 드림 | 🇨?녕해1- 가격은 5만원입니다. 주문을 원하시면 연락 주세요 감사합니다. [familyery 이름] 更換 :[림] |
表 1. 韓國烘焙食品電子郵件回應者的部分調校資料集。
資料格式和載入
您可以使用任何方便的格式儲存調整資料,包括資料庫記錄、JSON 檔案、CSV 或純文字檔案,只要您有透過 Python 程式碼擷取記錄的方法即可。為方便起見,示範調整程式會從線上存放區取得記錄。在這個轉換程式範例中,系統會使用 prepare_tuning_dataset() 函式,在 k-gemma-it/main.py 模組中載入微調資料集:
def prepare_tuning_dataset():
tokenizer = keras_nlp.models.GemmaTokenizer.from_preset(model_id)
# load data from repository (or local directory)
from datasets import load_dataset
ds = load_dataset(
# Dataset : https://huggingface.co/datasets/bebechien/korean_cake_boss
"bebechien/korean_cake_boss",
split="train",
)
...
如先前所述,只要您能擷取含有相關回應的要求,並將這些要求組合成用於調整記錄的文字字串,即可以方便的格式儲存資料集。
組合調整記錄
在實際調整程序中,系統會將每個要求和回應組合成一個字串,並加入提示操作說明和標記,用於指出要求內容和回應內容。然後,這個調整程式會將字串轉為符記,供模型使用。您可以查看 k-gemma-it/main.py 模組 prepare_tuning_dataset() 函式中用於組合調整記錄的程式碼,如下所示:
def prepare_tuning_dataset():
...
prompt_instruction = "다음에 대한 이메일 답장을 작성해줘."
for x in data:
item = f"<start_of_turn>user\n{prompt_instruction}\n\"{x['input']}\"<end_of_turn>\n<start_of_turn>model\n{x['output']}<end_of_turn>"
length = len(tokenizer(item))
# skip data if the token length is longer than our limit
if length < token_limit:
tuning_dataset.append(item)
if(len(tuning_dataset)>=num_data_limit):
break
...
這個函式會讀取資料,並透過新增 start_of_turn 和 end_of_turn 標記來格式化資料,這也是提供 Gemma 模型調校資料時的必要格式。這個程式碼也會為每個要求插入 prompt_instruction,您應根據應用程式需求進行適當編輯。
產生模型權重
完成調整資料的載入作業後,您就可以執行調整程式。這個範例應用程式的調整程序會使用 Keras NLP 程式庫,透過低秩調整 (LoRA) 技巧調整模型,產生新的模型權重。與全精確度調整相比,使用 LoRA 可大幅提升記憶體效率,因為 LoRA 會近似模擬模型權重變更。接著,您可以將這些近似權重疊加至現有模型權重,以便變更模型的行為。
如要執行調整作業並計算新的權重,請按照下列步驟操作:
在終端機視窗中,前往
k-gemma-it/目錄。cd spoken-language-tasks/k-gemma-it/使用
tune_model指令碼執行調整程序:./tune_model.sh
視可用的運算資源而定,調整程序可能需要數分鐘的時間。成功完成後,調整程式會以下列格式寫入 k-gemma-it/weights 目錄中的新 *.h5 權重檔案:
gemma2-2b_k-tuned_4_epoch##.lora.h5
疑難排解
如果調整未順利完成,可能的原因有兩個:
- 記憶體不足/資源用盡:如果調整程序要求的記憶體超過可用的 GPU 記憶體或 CPU 記憶體,就會發生這些錯誤。請確保在調整程序執行期間並非執行網頁應用程式。如果您在具備 16 GB GPU 記憶體的裝置上進行調整,請務必將
token_limit設為 256,並將batch_size設為 1。 - 未安裝 GPU 驅動程式或與 JAX 不相容:如要啟用程序,運算裝置必須安裝與 JAX 程式庫版本相容的硬體驅動程式。詳情請參閱 JAX 安裝說明文件。
部署經過調整的模型
調整程序會根據調整資料和調整應用程式中設定的訓練週期總數,產生多個權重。根據預設,調整程式會產生 20 個模型權重檔案,每個調整週期一個。每個後續的調校週期都會產生權重,以更準確地重現調校資料的結果。您可以在調整程序的終端機輸出中看到每個週期的準確率率,如下所示:
...
Epoch 14/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 567ms/step - loss: 0.4026 - sparse_categorical_accuracy: 0.8235
Epoch 15/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 569ms/step - loss: 0.3659 - sparse_categorical_accuracy: 0.8382
Epoch 16/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 571ms/step - loss: 0.3314 - sparse_categorical_accuracy: 0.8538
Epoch 17/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 572ms/step - loss: 0.2996 - sparse_categorical_accuracy: 0.8686
Epoch 18/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 574ms/step - loss: 0.2710 - sparse_categorical_accuracy: 0.8801
Epoch 19/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2451 - sparse_categorical_accuracy: 0.8903
Epoch 20/20
10/10 ━━━━━━━━━━━━━━━━━━━━ 6s 575ms/step - loss: 0.2212 - sparse_categorical_accuracy: 0.9021
雖然您希望準確率相當高 (0.80 到 0.90 左右),但不希望結果頻率太高或非常接近 1.00,因為這表示權重接近調整數據的高度。在這種情況下,模型在與調校範例有顯著差異的請求上,表現不佳。根據預設,部署指令碼會挑選 17 個權重的 Epoch 權重,這通常的準確率約為 0.90。
如要將產生的權重部署至網頁應用程式,請按照下列步驟操作:
在終端機視窗中,前往
k-gemma-it/目錄。cd spoken-language-tasks/k-gemma-it/使用
deploy_weights指令碼執行調整程序:./deploy_weights.sh
執行這個指令碼後,您應該會在 k-mail-replier/k_mail_replier/weights/ 目錄中看到新的 *.h5 檔案。
測試新模型
將新的權重部署至應用程式後,即可試用經過調整的新模型。您可以重新執行網頁應用程式並產生回應。
如要執行及測試專案,請按照下列步驟操作:
在終端機視窗中,前往
/k_mail_replier/目錄。cd spoken-language-tasks/k-mail-replier/使用
run_flask_app.sh指令碼執行應用程式:./run_flask_app.sh啟動網頁應用程式後,程式碼會列出可供瀏覽及測試的網址,通常為:
http://127.0.0.1:5000/在網頁介面中,按下第一個輸入欄位下方的「답 沖繩」按鈕,從模型產生回應。
您現在已在應用程式中調整及部署 Gemma 模型!請嘗試應用程式,並嘗試判斷經過調整的模型在工作中生成內容的能力有何限制。如果您發現模型在某些情況下效能不佳,請考慮將其中一些要求加入調整範例資料清單,方法是新增要求並提供理想回應。接著,請重新執行調整程序、重新部署新的權重,然後測試輸出內容。
其他資源
如要進一步瞭解這個專案,請參閱 Gemma Cookbook 程式碼存放區。如果您需要應用程式建構方面的協助,或希望與其他開發人員合作,請造訪 Google 開發人員社群 Discord 伺服器。如要進一步瞭解更多「Build with Google AI」專案,請參閱影片播放清單。