Gemini, ऑडियो इनपुट का विश्लेषण करके टेक्स्ट वाले जवाब जनरेट कर सकता है.
Python
from google import genai
import base64
client = genai.Client()
uploaded_file = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const uploadedFile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mp3" }
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
REST
# First upload the file, then use the URI:
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": "YOUR_FILE_URI",
"mime_type": "audio/mp3"
}
]
}'
खास जानकारी
Gemini, ऑडियो इनपुट का विश्लेषण कर सकता है और उसे समझ सकता है. साथ ही, टेक्स्ट फ़ॉर्मैट में जवाब जनरेट कर सकता है. इससे इन कामों को पूरा किया जा सकता है:
- ऑडियो कॉन्टेंट के बारे में जानकारी देना, खास जानकारी देना या सवालों के जवाब देना
- ट्रांसक्रिप्ट और अनुवाद (बोली को लिखाई में बदलना)
- स्पीकर डायराइज़ेशन (अलग-अलग स्पीकर की पहचान करना)
- भाषण और संगीत में भावनाओं का पता लगाना
- टाइमस्टैंप की मदद से, किसी सेगमेंट का विश्लेषण करना
रीयल-टाइम में आवाज़ और वीडियो से इंटरैक्ट करने के लिए, Live API देखें. रीयल-टाइम ट्रांसक्रिप्शन की सुविधा के साथ काम करने वाले, बोली को लिखाई में बदलने वाले मॉडल के लिए, Google Cloud Speech-to-Text API का इस्तेमाल करें.
बोले जा रहे शब्दों को टेक्स्ट में बदलना
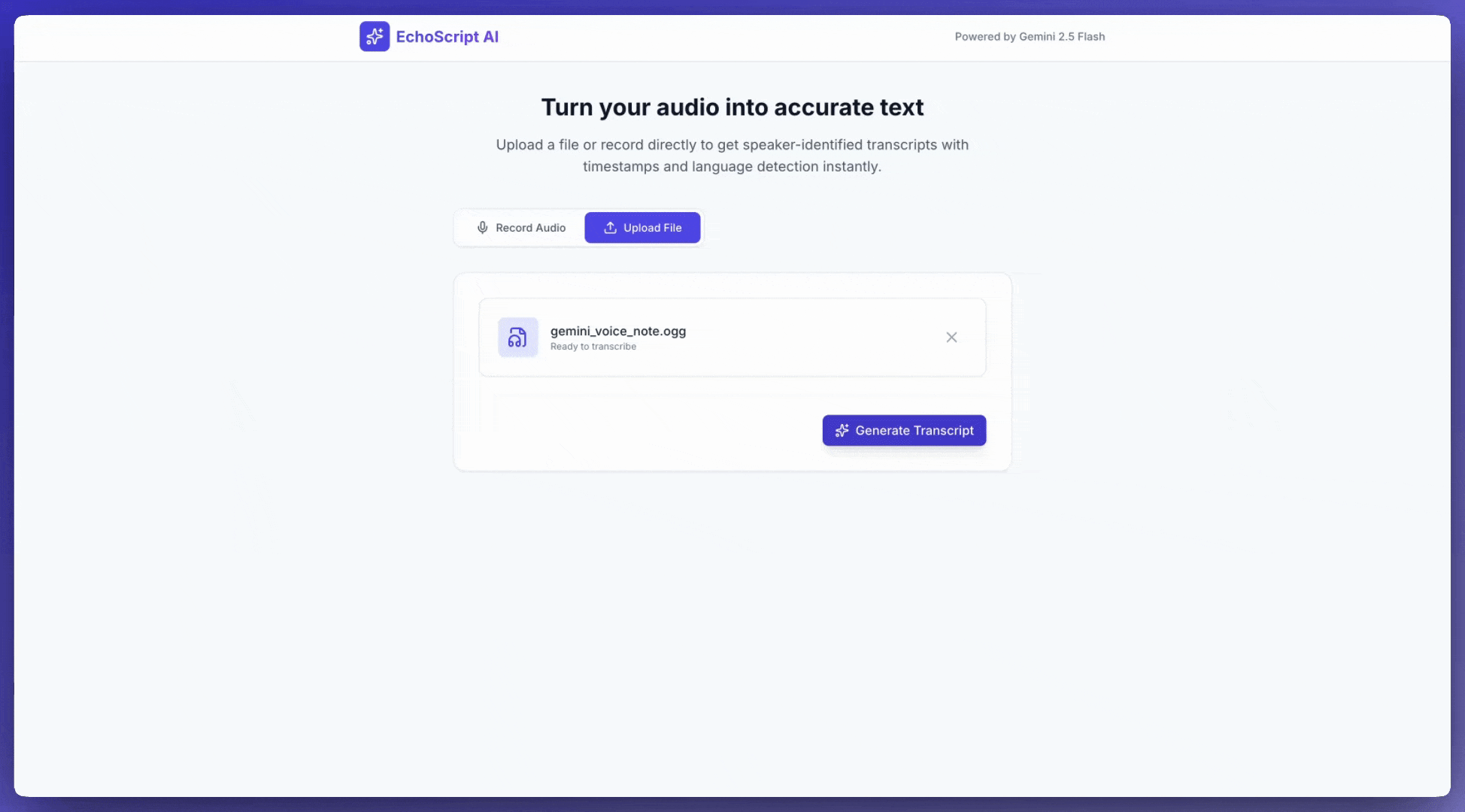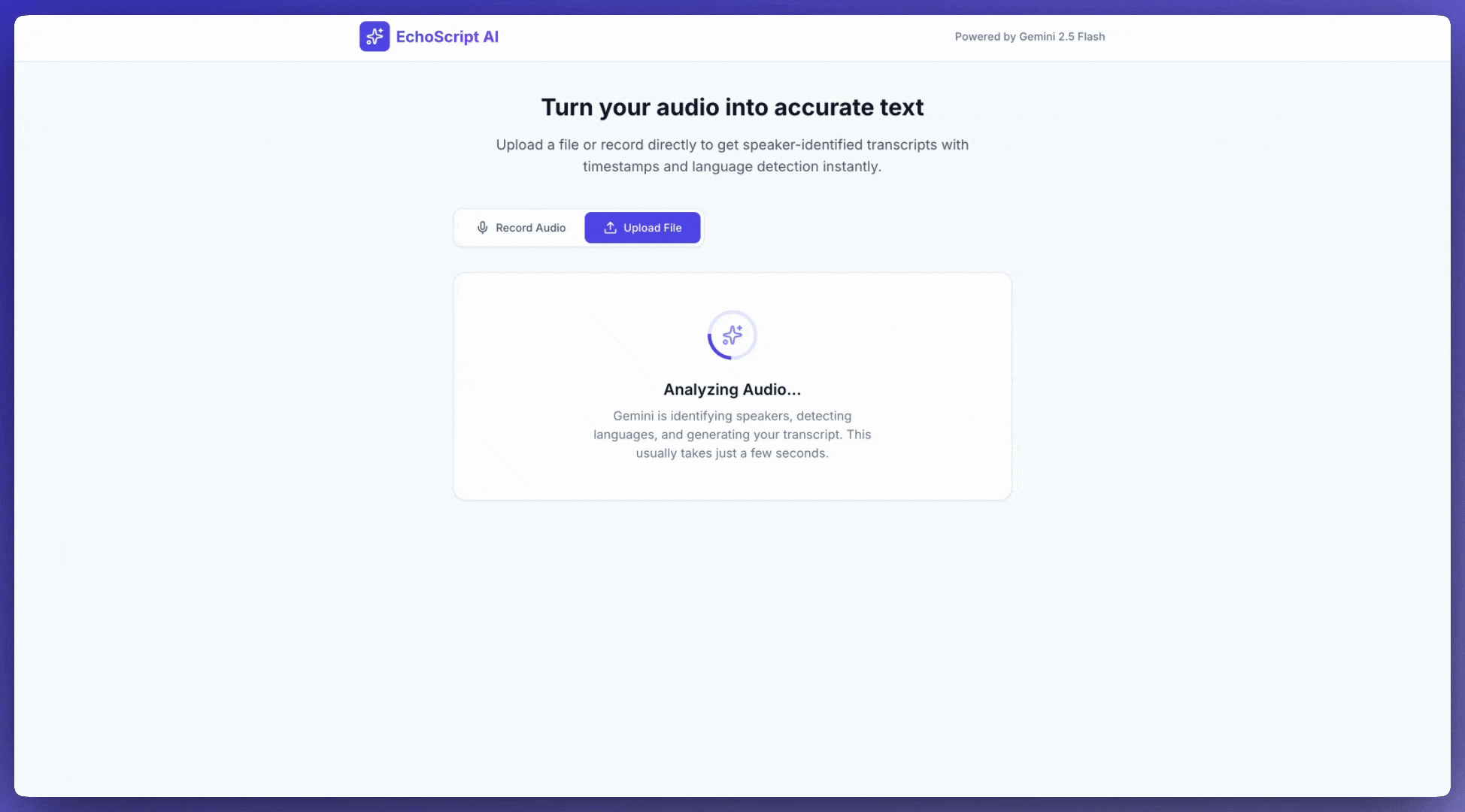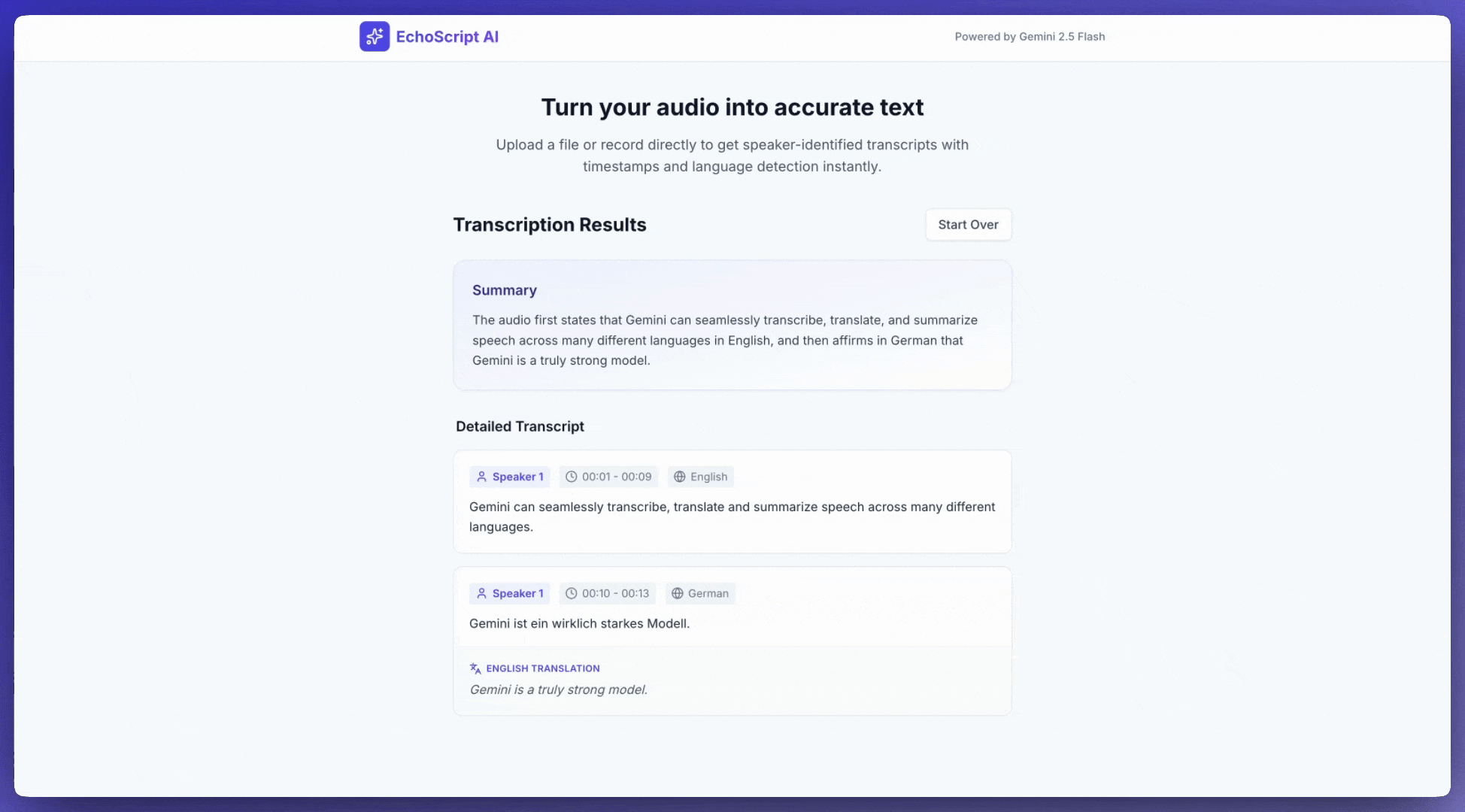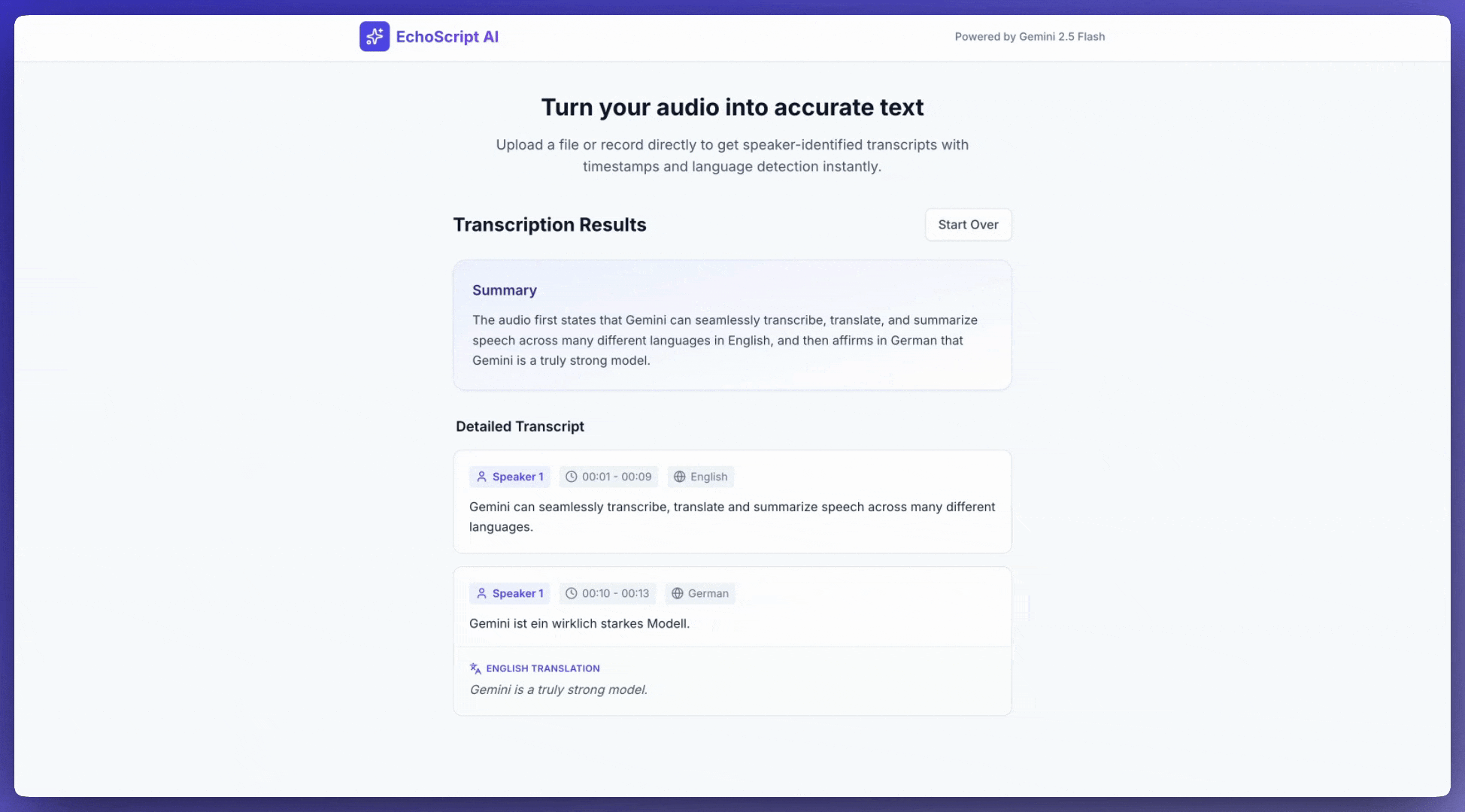
इस उदाहरण में, स्ट्रक्चर्ड आउटपुट का इस्तेमाल करके, टाइमस्टैंप, स्पीकर डायराइज़ेशन, और भावनाओं का पता लगाने की सुविधा के साथ, स्पीच को ट्रांसक्राइब करने, उसका अनुवाद करने, और उसकी खास जानकारी पाने का तरीका दिखाया गया है.
Python
from google import genai
client = genai.Client()
YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM"
prompt = """
Process the audio file and generate a detailed transcription.
Requirements:
1. Identify distinct speakers (e.g., Speaker 1, Speaker 2).
2. Provide accurate timestamps for each segment (Format: MM:SS).
3. Detect the primary language of each segment.
4. If not English, provide the English translation.
5. Identify the primary emotion: Happy, Sad, Angry, or Neutral.
6. Provide a brief summary at the beginning.
"""
response_schema = {
"type": "object",
"properties": {
"summary": {"type": "string"},
"segments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"speaker": {"type": "string"},
"timestamp": {"type": "string"},
"content": {"type": "string"},
"language": {"type": "string"},
"emotion": {
"type": "string",
"enum": ["happy", "sad", "angry", "neutral"]
}
},
"required": ["speaker", "timestamp", "content", "emotion"]
}
}
},
"required": ["summary", "segments"]
}
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "video", "uri": YOUTUBE_URL, "mime_type": "video/mp4"},
{"type": "text", "text": prompt}
],
response_format=response_schema,
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM";
const prompt = `
Process the audio file and generate a detailed transcription.
Requirements:
1. Identify distinct speakers (e.g., Speaker 1, Speaker 2).
2. Provide accurate timestamps for each segment (Format: MM:SS).
3. Detect the primary language of each segment.
4. If not English, provide the English translation.
5. Identify the primary emotion: Happy, Sad, Angry, or Neutral.
6. Provide a brief summary at the beginning.
`;
const responseSchema = {
type: "object",
properties: {
summary: { type: "string" },
segments: {
type: "array",
items: {
type: "object",
properties: {
speaker: { type: "string" },
timestamp: { type: "string" },
content: { type: "string" },
language: { type: "string" },
emotion: {
type: "string",
enum: ["happy", "sad", "angry", "neutral"]
}
},
required: ["speaker", "timestamp", "content", "emotion"]
}
}
},
required: ["summary", "segments"]
};
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "video", uri: YOUTUBE_URL, mime_type: "video/mp4" },
{ type: "text", text: prompt }
],
response_format: responseSchema,
});
console.log(JSON.parse(interaction.output_text));
REST
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=ku-N-eS1lgM",
"mime_type": "video/mp4"
},
{
"type": "text",
"text": "Transcribe with speaker diarization and emotion detection."
}
],
"response_format": {
"type": "object",
"properties": {
"summary": {"type": "string"},
"segments": {
"type": "array",
"items": {
"type": "object",
"properties": {
"speaker": {"type": "string"},
"timestamp": {"type": "string"},
"content": {"type": "string"},
"emotion": {"type": "string", "enum": ["happy", "sad", "angry", "neutral"]}
}
}
}
}
}
}'
ऑडियो इनपुट करना
ऑडियो डेटा इन तरीकों से दिया जा सकता है:
- अनुरोध करने से पहले, ऑडियो फ़ाइल अपलोड करें.
- अनुरोध के साथ इनलाइन ऑडियो डेटा पास करें.
ऑडियो फ़ाइल अपलोड करना
20 एमबी से बड़ी फ़ाइलों के लिए, Files API का इस्तेमाल करें.
Python
from google import genai
client = genai.Client()
uploaded_file = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
const uploadedFile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mp3" }
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
REST
# First upload the file using the Files API, then use the URI:
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"uri": "YOUR_FILE_URI",
"mime_type": "audio/mp3"
}
]
}'
ऑडियो डेटा को इनलाइन पास करना
अगर ऑडियो फ़ाइलें छोटी हैं और अनुरोध का कुल साइज़ 20 एमबी से कम है, तो:
Python
from google import genai
import base64
client = genai.Client()
with open('path/to/small-sample.mp3', 'rb') as f:
audio_bytes = f.read()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"data": base64.b64encode(audio_bytes).decode('utf-8'),
"mime_type": "audio/mp3"
}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const client = new GoogleGenAI({});
const audioData = fs.readFileSync("path/to/small-sample.mp3", {
encoding: "base64"
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{type: "text", text: "Describe this audio clip"},
{
type: "audio",
data: audioData,
mime_type: "audio/mp3"
}
]
});
console.log(interaction.output_text);
REST
AUDIO_PATH="path/to/sample.mp3"
if [[ "$(base64 --version 2>&1)" = *"FreeBSD"* ]]; then
B64FLAGS="--input"
else
B64FLAGS="-w0"
fi
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{
"type": "audio",
"data": "'$(base64 $B64FLAGS $AUDIO_PATH)'",
"mime_type": "audio/mp3"
}
]
}'
इनलाइन ऑडियो डेटा के बारे में जानकारी: * अनुरोध का ज़्यादा से ज़्यादा साइज़ 20 एमबी होना चाहिए. इसमें प्रॉम्प्ट और सभी फ़ाइलें शामिल हैं * दोबारा इस्तेमाल करने के लिए, फ़ाइल अपलोड करें
ट्रांसक्रिप्ट पाना
ट्रांसक्रिप्ट पाने के लिए, प्रॉम्प्ट में इसके लिए अनुरोध करें:
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Generate a transcript of the speech."},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
print(interaction.output_text)
JavaScript
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Generate a transcript of the speech." },
{
type: "audio",
uri: uploadedFile.uri,
mime_type: uploadedFile.mimeType
}
]
});
console.log(interaction.output_text);
टाइमस्टैंप देखें
किसी खास सेक्शन का रेफ़रंस देने के लिए, MM:SS फ़ॉर्मैट का इस्तेमाल करें:
Python
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Provide a transcript from 02:30 to 03:29."},
{
"type": "audio",
"uri": uploaded_file.uri,
"mime_type": uploaded_file.mime_type
}
]
)
JavaScript
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Provide a transcript from 02:30 to 03:29." },
{ type: "audio", uri: uploadedFile.uri, mime_type: "audio/mp3" }
]
});
टोकन गिनना
किसी ऑडियो फ़ाइल में टोकन की गिनती करना:
Python
response = client.models.count_tokens(
model="gemini-3.5-flash",
contents=[uploaded_file]
)
print(response)
JavaScript
const response = await client.models.countTokens({
model: "gemini-3.5-flash",
contents: [
{ fileData: { fileUri: uploadedFile.uri, mimeType: uploadedFile.mimeType } }
]
});
console.log(response.totalTokens);
इस्तेमाल किए जा सकने वाले ऑडियो फ़ॉर्मैट
- WAV -
audio/wav - MP3 -
audio/mp3 - AIFF -
audio/aiff - AAC -
audio/aac - OGG Vorbis -
audio/ogg - FLAC -
audio/flac
ऑडियो के बारे में तकनीकी जानकारी
- टोकन: ऑडियो के हर सेकंड के लिए 32 टोकन (1 मिनट = 1,920 टोकन)
- बोली न जाने वाली आवाज़ें: Gemini, बोली न जाने वाली आवाज़ों (जैसे, पक्षियों के चहचहाने, सायरन वगैरह) को समझ सकता है
- ज़्यादा से ज़्यादा लंबाई: हर प्रॉम्प्ट के लिए 9.5 घंटे का ऑडियो
- रिज़ॉल्यूशन: 16 केबीपीएस पर डाउनसैंपल किया गया
- चैनल: मल्टी-चैनल ऑडियो को एक चैनल में मिलाया गया है
आगे क्या करना है
- Files API: ऑडियो फ़ाइलें अपलोड और मैनेज करें
- सिस्टम के निर्देश: मॉडल के व्यवहार को पसंद के मुताबिक बनाएं
- स्ट्रक्चर्ड आउटपुट: ट्रांसक्रिप्शन के नतीजे JSON फ़ॉर्मैट में पाएं