
In dieser Anleitung wird beschrieben, wie Sie Gemma-Modelle im Hugging Face-Format „Safetensors“ (.safetensors) in das MediaPipe-Aufgabendateiformat (.task) konvertieren. Diese Konvertierung ist erforderlich, um vortrainierte oder feinabgestimmte Gemma-Modelle für die On-Device-Inferenz auf Android und iOS mit der MediaPipe LLM Inference API und der LiteRT-Laufzeit bereitzustellen.

Zum Erstellen des erforderlichen Task-Bundles (.task) verwenden Sie LiteRT Torch. Mit diesem Tool werden PyTorch-Modelle in LiteRT-Modelle mit mehreren Signaturen (.tflite) exportiert, die mit der MediaPipe LLM Inference API kompatibel sind und sich für die Ausführung auf CPU-Backends in mobilen Anwendungen eignen.
Die endgültige .task-Datei ist ein in sich geschlossenes Paket, das von MediaPipe benötigt wird. Es enthält das LiteRT-Modell, das Tokenizer-Modell und wichtige Metadaten. Dieses Bundle ist erforderlich, da der Tokenizer (der Textprompts in Token-Einbettungen für das Modell konvertiert) mit dem LiteRT-Modell verpackt werden muss, um End-to-End-Inferenz zu ermöglichen.
Hier ist eine detaillierte Anleitung für den Vorgang:
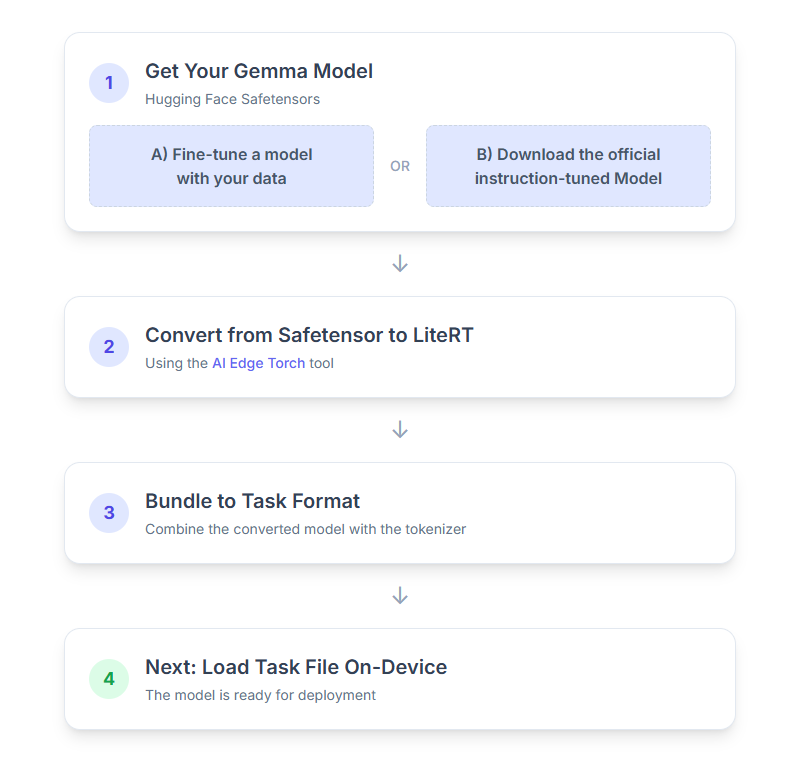
1. Gemma-Modell abrufen
Sie haben zwei Möglichkeiten, um loszulegen.
Option A: Vorhandenes feinabgestimmtes Modell verwenden
Wenn Sie ein abgestimmtes Gemma-Modell haben, fahren Sie einfach mit dem nächsten Schritt fort.
Option B: Offizielles, auf Anweisungen abgestimmtes Modell herunterladen
Wenn Sie ein Modell benötigen, können Sie ein Gemma-Modell mit Instruction Tuning aus dem Hugging Face Hub herunterladen.
Erforderliche Tools einrichten:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
Modell herunterladen:
Modelle im Hugging Face-Hub werden durch eine Modell-ID identifiziert, die in der Regel das Format <organization_or_username>/<model_name> hat. Wenn Sie beispielsweise das offizielle auf Anweisungen abgestimmte Modell Gemma 3 270M von Google herunterladen möchten, verwenden Sie:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. Modell in LiteRT konvertieren und quantisieren
Richten Sie eine virtuelle Python-Umgebung ein und installieren Sie die neueste stabile Version des LiteRT-Torch-Pakets:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
Verwenden Sie das folgende Skript, um das Safetensor-Modell in ein LiteRT-Modell zu konvertieren.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
Dieser Prozess ist zeitaufwendig und hängt von der Verarbeitungsgeschwindigkeit Ihres Computers ab. Auf einer 8‑Kern-CPU von 2025 dauert das Training eines 270‑Millionen-Modells etwa 5–10 Minuten, während ein 1‑Milliarden-Modell etwa 10–30 Minuten in Anspruch nehmen kann.
Die endgültige Ausgabe, ein LiteRT-Modell, wird in Ihrem angegebenen OUTPUT_DIR_PATH gespeichert.
Passen Sie die folgenden Werte an die Arbeitsspeicher- und Leistungsbeschränkungen Ihres Zielgeräts an.
kv_cache_max_len: Definiert die insgesamt zugewiesene Größe des Arbeitsspeichers des Modells (KV-Cache). Diese Kapazität ist ein hartes Limit und muss ausreichen, um die kombinierte Summe der Tokens der Eingabeaufforderung (Prefill) und aller nachfolgend generierten Tokens (Decode) zu speichern.prefill_seq_len: Gibt die Token-Anzahl des Eingabe-Prompts für die Aufteilung in Prefill-Chunks an. Bei der Verarbeitung des Eingabe-Prompts mit Prefill-Chunking wird die gesamte Sequenz (z.B. 50.000 Tokens) wird nicht auf einmal berechnet, sondern in überschaubare Segmente (z. B. Blöcke mit 2.048 Tokens) unterteilt, die sequenziell in den Cache geladen werden, um einen Fehler aufgrund von zu wenig Arbeitsspeicher zu vermeiden.quantize: String für die ausgewählten Quantisierungsschemas. Im Folgenden finden Sie eine Liste der verfügbaren Quantisierungsrezepte für Gemma 3.none: Keine Quantisierungfp16: FP16-Gewichtungen, FP32-Aktivierungen und Gleitkomma-Berechnung für alle Vorgängedynamic_int8: FP32-Aktivierungen, INT8-Gewichtungen und Ganzzahlberechnungweight_only_int8: FP32-Aktivierungen, INT8-Gewichtungen und Gleitkomma-Berechnung
3. Task-Bundle aus LiteRT und Tokenizer erstellen
Richten Sie eine virtuelle Python-Umgebung ein und installieren Sie das mediapipe-Python-Paket:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
Verwenden Sie die genai.bundler-Bibliothek, um das Modell zu bündeln:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
Mit der Funktion bundler.create_bundle wird eine .task-Datei erstellt, die alle erforderlichen Informationen zum Ausführen des Modells enthält.
4. Inferenz mit MediaPipe unter Android
Initialisieren Sie die Aufgabe mit grundlegenden Konfigurationsoptionen:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
Verwenden Sie die Methode generateResponse(), um eine Textantwort zu generieren.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
Verwenden Sie die Methode generateResponseAsync(), um die Antwort zu streamen.
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
Weitere Informationen finden Sie im LLM Inference guide for Android.
Nächste Schritte
Weitere Informationen zum Entwickeln und Erkunden mit Gemma-Modellen: