
|
|
|
|
|
 Quelle auf GitHub ansehen Quelle auf GitHub ansehen
|
In diesem Leitfaden wird beschrieben, wie Sie Gemma mit Hugging Face Transformers und TRL für ein NPC-Dataset für mobile Spiele optimieren. Lerninhalte:
- Entwicklungsumgebung einrichten
- Dataset für die Feinabstimmung vorbereiten
- Gemma-Modell mit TRL und SFTTrainer vollständig abstimmen
- Modellinferenz und Vibe-Checks testen
Entwicklungsumgebung einrichten
Der erste Schritt besteht darin, Hugging Face-Bibliotheken, einschließlich TRL, und Datasets zu installieren, um ein offenes Modell mit verschiedenen RLHF- und Ausrichtungstechniken abzustimmen.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
Hinweis: Wenn Sie eine GPU mit Ampere-Architektur (z. B. NVIDIA L4) oder neuer verwenden, können Sie Flash Attention verwenden. Flash Attention ist eine Methode, die Berechnungen erheblich beschleunigt und die Arbeitsspeichernutzung von quadratisch auf linear in der Sequenzlänge reduziert, was zu einer bis zu dreifachen Beschleunigung des Trainings führt. FlashAttention
Bevor Sie mit dem Training beginnen können, müssen Sie die Nutzungsbedingungen für Gemma akzeptieren. Sie können die Lizenz auf Hugging Face akzeptieren, indem Sie auf der Modellseite unter http://huggingface.co/google/gemma-3-270m-it auf die Schaltfläche „Agree and access repository“ (Zustimmen und auf Repository zugreifen) klicken.
Nachdem Sie die Lizenz akzeptiert haben, benötigen Sie ein gültiges Hugging Face-Token, um auf das Modell zuzugreifen. Wenn Sie Google Colab verwenden, können Sie Ihr Hugging Face-Token sicher über Colab-Secrets verwenden. Andernfalls können Sie das Token direkt in der Methode login festlegen. Achten Sie darauf, dass Ihr Token auch Schreibzugriff hat, da Sie Ihr Modell während des Trainings in den Hub hochladen.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
Sie können die Ergebnisse auf der lokalen VM von Colab speichern. Wir empfehlen jedoch dringend, Zwischenergebnisse in Google Drive zu speichern. So sind Ihre Trainingsergebnisse sicher und Sie können das beste Modell ganz einfach vergleichen und auswählen.
from google.colab import drive
drive.mount('/content/drive')
Wählen Sie das Basismodell aus, das Sie optimieren möchten, und passen Sie das Prüfpunktverzeichnis und die Lernrate an.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
Dataset für das Fine-Tuning erstellen und vorbereiten
Das Dataset bebechien/MobileGameNPC enthält eine kleine Auswahl von Unterhaltungen zwischen einem Spieler und zwei Alien-NPCs (einem Marsianer und einem Venusianer), die jeweils einen einzigartigen Sprechstil haben. Der marsianische NPC spricht beispielsweise mit einem Akzent, bei dem „s“-Laute durch „z“ ersetzt werden, verwendet „da“ für „the“ und „diz“ für „this“ und macht gelegentlich Klickgeräusche wie *k'tak*.
Dieses Dataset veranschaulicht ein wichtiges Prinzip für das Fine-Tuning: Die erforderliche Dataset-Größe hängt von der gewünschten Ausgabe ab.
- Um dem Modell eine stilistische Variante einer Sprache beizubringen, die es bereits kennt, z. B. den Akzent des Marsianers, kann ein kleines Dataset mit nur 10 bis 20 Beispielen ausreichen.
- Um dem Modell jedoch eine völlig neue oder gemischte außerirdische Sprache beizubringen, wäre ein deutlich größerer Datensatz erforderlich.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
Gemma mit TRL und SFTTrainer optimieren
Jetzt können Sie Ihr Modell abstimmen. Mit SFTTrainer von Hugging Face TRL lassen sich offene LLMs ganz einfach mit überwachtem Lernen feinabstimmen. SFTTrainer ist eine abgeleitete Klasse von Trainer aus der transformers-Bibliothek und unterstützt dieselben Funktionen.
Mit dem folgenden Code werden das Gemma-Modell und der Tokenizer von Hugging Face geladen.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
Vor dem Feinabstimmung
Die folgende Ausgabe zeigt, dass die Standardfunktionen für diesen Anwendungsfall möglicherweise nicht ausreichen.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
Im obigen Beispiel wird die primäre Funktion des Modells geprüft, nämlich das Generieren von In-Game-Dialogen. Im nächsten Beispiel wird die Konsistenz der Charaktere getestet. Wir stellen dem Modell einen themenfremden Prompt. Zum Beispiel Sorry, you are a game NPC., das außerhalb der Wissensdatenbank des Charakters liegt.
Ziel ist es, herauszufinden, ob das Modell in der Rolle bleiben kann, anstatt die Frage außerhalb des Kontexts zu beantworten. Dies dient als Grundlage, um zu bewerten, wie effektiv die gewünschte Persona durch den Feinabstimmungsprozess vermittelt wurde.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
Wir können zwar durch Prompt-Engineering den Ton steuern, aber die Ergebnisse können unvorhersehbar sein und stimmen möglicherweise nicht immer mit der gewünschten Persona überein.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
Training
Bevor Sie mit dem Training beginnen können, müssen Sie die Hyperparameter definieren, die Sie in einer SFTConfig-Instanz verwenden möchten.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
Sie haben jetzt alle Bausteine, die Sie zum Erstellen von SFTTrainer benötigen, um das Training Ihres Modells zu starten.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
Starten Sie das Training, indem Sie die Methode train() aufrufen.
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
Um die Trainings- und Validierungsverluste darzustellen, würden Sie diese Werte normalerweise aus dem TrainerState-Objekt oder den während des Trainings generierten Logs extrahieren.
Bibliotheken wie Matplotlib können dann verwendet werden, um diese Werte über Trainingsschritten oder Epochen hinweg zu visualisieren. Die x-Achse würde die Trainingsschritte oder ‑epochen darstellen und die y-Achse die entsprechenden Verlustwerte.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
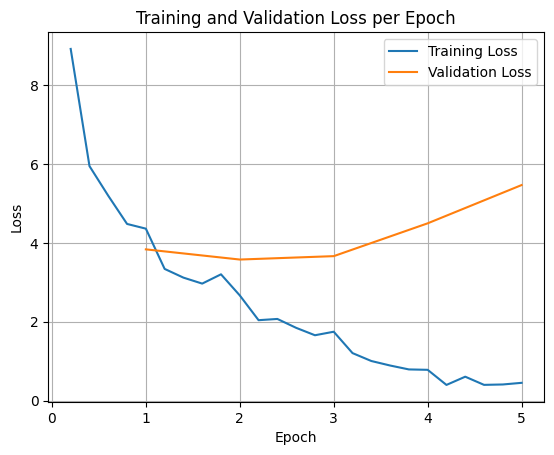
Diese Visualisierung hilft, den Trainingsprozess zu überwachen und fundierte Entscheidungen zur Hyperparameter-Abstimmung oder zum vorzeitigen Stoppen zu treffen.
Der Trainingsverlust gibt den Fehler bei den Daten an, mit denen das Modell trainiert wurde, während der Validierungsverlust den Fehler bei einem separaten Dataset angibt, das dem Modell noch nicht bekannt ist. Durch die Überwachung beider Werte lässt sich eine Überanpassung erkennen, wenn das Modell mit den Trainingsdaten gut funktioniert, aber schlecht mit unbekannten Daten.
- Validierungsverlust >> Trainingsverlust: Überanpassung
- Validierungsverlust > Trainingsverlust: Leichte Überanpassung
- Validierungsverlust < Trainingsverlust: Einige Unteranpassungen
- Validierungsverlust << Trainingsverlust: Unteranpassung
Modellinferenz testen
Nach dem Training sollten Sie Ihr Modell bewerten und testen. Sie können verschiedene Stichproben aus dem Test-Dataset laden und das Modell anhand dieser Stichproben bewerten.
Für diesen speziellen Anwendungsfall ist das beste Modell eine Frage der Präferenz. Interessanterweise kann das, was wir normalerweise als „Overfitting“ bezeichnen, für einen NPC in einem Spiel sehr nützlich sein. Dadurch wird das Modell gezwungen, allgemeine Informationen zu vergessen und sich stattdessen auf die spezifische Persona und die Merkmale zu konzentrieren, mit denen es trainiert wurde. So wird sichergestellt, dass es durchgehend im Charakter bleibt.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Laden wir alle Fragen aus dem Test-Dataset und generieren wir Ausgaben.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
Wenn Sie unseren ursprünglichen Generalist-Prompt ausprobieren, sehen Sie, dass das Modell immer noch versucht, im trainierten Stil zu antworten. In diesem Beispiel sind Overfitting und katastrophales Vergessen tatsächlich von Vorteil für den NPC, da er beginnt, allgemeines Wissen zu vergessen, das möglicherweise nicht anwendbar ist. Das gilt auch für andere Arten des vollständigen Feinabstimmens, bei denen die Ausgabe auf bestimmte Datenformate beschränkt werden soll.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
Zusammenfassung und nächste Schritte
In dieser Anleitung wurde beschrieben, wie Sie ein vollständiges Modell mit TRL abstimmen. Lesen Sie als Nächstes die folgenden Dokumente: