
Ce guide explique comment convertir des modèles Gemma au format Hugging Face Safetensors (.safetensors) au format de fichier de tâche MediaPipe (.task). Cette conversion est essentielle pour déployer des modèles Gemma pré-entraînés ou affinés pour l'inférence sur l'appareil sur Android et iOS à l'aide de l'API MediaPipe LLM Inference et de l'environnement d'exécution LiteRT.
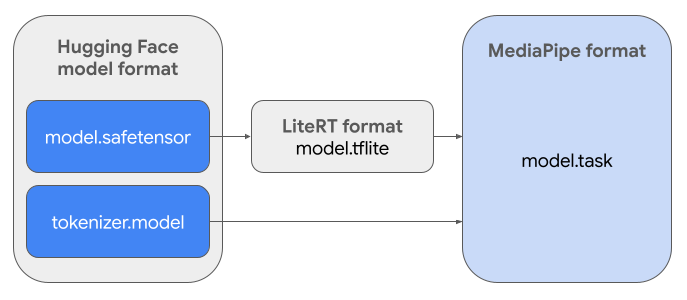
Pour créer le Task Bundle (.task) requis, vous utiliserez LiteRT Torch. Cet outil exporte les modèles PyTorch dans des modèles LiteRT (.tflite) à signatures multiples, qui sont compatibles avec l'API MediaPipe LLM Inference et adaptés à l'exécution sur des backends de processeur dans les applications mobiles.
Le fichier .task final est un package autonome requis par MediaPipe, qui regroupe le modèle LiteRT, le modèle de tokenisation et les métadonnées essentielles. Ce bundle est nécessaire, car le tokenizer (qui convertit les requêtes textuelles en embeddings de jetons pour le modèle) doit être fourni avec le modèle LiteRT pour permettre l'inférence de bout en bout.
Voici la procédure à suivre :
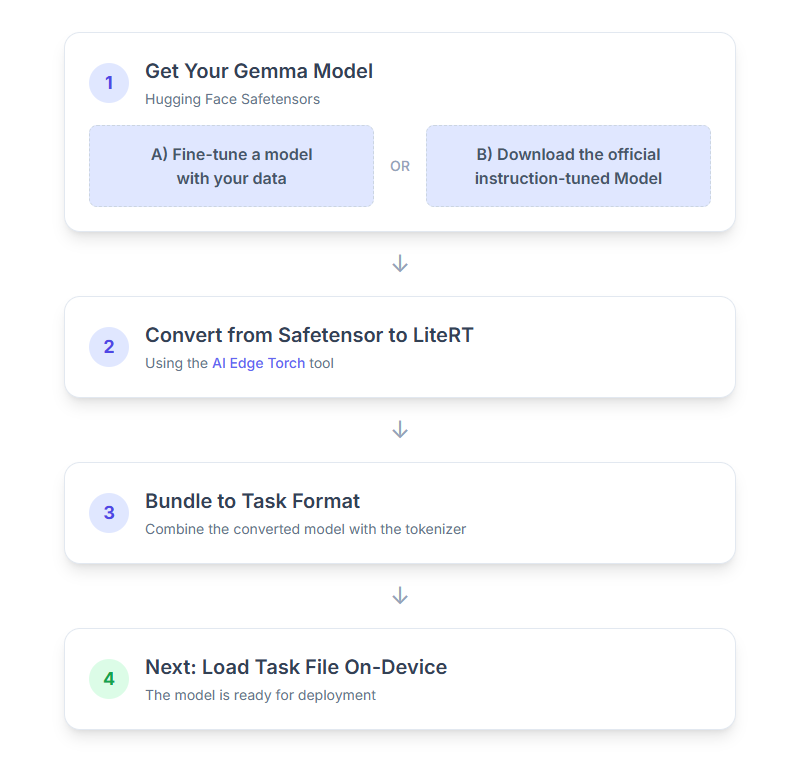
1. Obtenir votre modèle Gemma
Deux options s'offrent à vous pour commencer.
Option A : Utiliser un modèle affiné existant
Si vous avez préparé un modèle Gemma affiné, passez directement à l'étape suivante.
Option B. Télécharger le modèle officiel adapté aux instructions
Si vous avez besoin d'un modèle, vous pouvez télécharger un modèle Gemma adapté aux instructions depuis le hub Hugging Face.
Configurez les outils nécessaires :
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
Téléchargez le modèle :
Les modèles du hub Hugging Face sont identifiés par un ID de modèle, généralement au format <organization_or_username>/<model_name>. Par exemple, pour télécharger le modèle officiel Google Gemma 3 270M adapté aux instructions, utilisez la commande suivante :
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. Convertir et quantifier le modèle en LiteRT
Configurez un environnement virtuel Python et installez la dernière version stable du package LiteRT Torch :
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
Utilisez le script suivant pour convertir le modèle Safetensor en modèle LiteRT.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
Sachez que ce processus prend du temps et dépend de la vitesse de traitement de votre ordinateur. À titre de référence, sur un processeur 8 cœurs de 2025, un modèle de 270 M de paramètres prend entre 5 et 10 minutes, tandis qu'un modèle de 1 B de paramètres peut prendre entre 10 et 30 minutes.
La sortie finale, un modèle LiteRT, sera enregistrée dans le OUTPUT_DIR_PATH que vous avez spécifié.
Ajustez les valeurs suivantes en fonction des contraintes de mémoire et de performances de votre appareil cible.
kv_cache_max_len: définit la taille totale allouée à la mémoire de travail du modèle (cache KV). Cette capacité est une limite stricte et doit être suffisante pour stocker la somme combinée des jetons de la requête (le préremplissage) et de tous les jetons générés par la suite (le décodage).prefill_seq_len: spécifie le nombre de jetons de la requête d'entrée pour le découpage du préremplissage. Lors du traitement de l'invite d'entrée à l'aide du chunking de préremplissage, la séquence entière (par exemple, 50 000 jetons) n'est pas calculée en une seule fois. Elle est divisée en segments gérables (par exemple, des blocs de 2 048 jetons) qui sont chargés séquentiellement dans le cache pour éviter une erreur de mémoire insuffisante.quantize: chaîne pour les schémas de quantification sélectionnés. Vous trouverez ci-dessous la liste des recettes de quantification disponibles pour Gemma 3.none: aucune quantificationfp16: pondérations FP16, activations FP32 et calcul à virgule flottante pour toutes les opérationsdynamic_int8: activations FP32, pondérations INT8 et calcul d'entiersweight_only_int8: activations FP32, pondérations INT8 et calcul à virgule flottante
3. Créer un Task Bundle à partir de LiteRT et du tokenizer
Configurez un environnement virtuel Python et installez le package Python mediapipe :
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
Utilisez la bibliothèque genai.bundler pour regrouper le modèle :
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
La fonction bundler.create_bundle crée un fichier .task qui contient toutes les informations nécessaires à l'exécution du modèle.
4. Inférence avec MediaPipe sur Android
Initialisez la tâche avec les options de configuration de base :
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
Utilisez la méthode generateResponse() pour générer une réponse textuelle.
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
Pour diffuser la réponse en streaming, utilisez la méthode generateResponseAsync().
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
Pour en savoir plus, consultez le guide sur l'inférence LLM pour Android.
Étapes suivantes
Créez et explorez davantage avec les modèles Gemma :