Génération d'images Nano Banana
- Ou créez la vôtre à partir de requêtes :
-








-
Généré par Nano Banana 2 Requête : "Photo d'une couverture de magazine brillant, la couverture bleue minimaliste comporte les mots Nano Banana en gros et en gras. Le texte est écrit dans une police avec empattement et remplit la vue. Aucun autre texte. Devant le texte se trouve le portrait d'une personne portant une robe élégante et minimaliste. Elle tient le chiffre 2 de manière ludique, qui est le point focal.
Mets le numéro du problème et la date "février 2026" dans l'angle, avec un code-barres. Le magazine est posé sur une étagère contre un mur orange crépi, dans une boutique de créateurs." -
Généré par Nano Banana Pro Requête : "Présente une scène de dessin animé 3D miniature isométrique claire, vue de dessus à 45°, de Londres, avec ses monuments et éléments architecturaux les plus emblématiques. Utilisez des textures douces et raffinées avec des matériaux PBR réalistes, ainsi que des éclairages et des ombres doux et réalistes. Intégrez les conditions météorologiques actuelles directement dans l'environnement urbain pour créer une ambiance immersive. Utilise une composition épurée et minimaliste avec un arrière-plan uni et doux. En haut au centre, placez le titre "Londres" en gros caractères gras, une icône météo bien visible en dessous, puis la date (en petits caractères) et la température (en caractères moyens). Tout le texte doit être centré avec un espacement cohérent et peut chevaucher légèrement le haut des bâtiments." -
Généré par Nano Banana 2 Requête : "Utilise la recherche d'images pour trouver des images précises d'un quetzal resplendissant. Crée un magnifique fond d'écran au format 3:2 de cet oiseau, avec un dégradé naturel de haut en bas et une composition minimaliste." -

Généré par Nano Banana Pro Requête : "Place ce logo sur une publicité haut de gamme pour un parfum à la banane. Le logo est parfaitement intégré à la bouteille." -
Généré par Nano Banana Pro Requête : "Photo d'une scène de la vie quotidienne dans un café animé servant le petit-déjeuner. Au premier plan, un homme d'anime aux cheveux bleus, l'une des personnes est un croquis au crayon, l'autre est une personne en pâte à modeler" -
Généré par Nano Banana Pro Requête : "Utilise la recherche pour savoir comment le lancement de Gemini 3 Flash a été accueilli. Utilise ces informations pour écrire un court article à ce sujet (avec des titres). Retourne une photo de l'article tel qu'il est apparu dans un magazine brillant axé sur le design. Il s'agit d'une photo d'une seule page pliée, montrant l'article sur Gemini 3 Flash. Une photo principale. Titre en serif." -
Généré par Nano Banana Pro Requête : "Une icône représentant un chien mignon. L'arrière-plan est blanc. Crée des icônes dans un style 3D coloré et tactile. Pas de texte." -
Généré par Nano Banana 2 Requête : "Crée une photo parfaitement isométrique. Il ne s'agit pas d'une miniature, mais d'une photo qui s'est avérée parfaitement isométrique. Il s'agit d'une photo d'un magnifique jardin moderne. Il y a une grande piscine en forme de 2 et les mots "Nano Banana 2"."
Nano Banana est le nom des fonctionnalités de génération d'images natives de Gemini. Gemini peut générer et traiter des images de manière conversationnelle avec du texte, des images ou une combinaison des deux. Vous pouvez ainsi créer, modifier et itérer des éléments visuels avec un contrôle sans précédent.
Nano Banana fait référence à deux modèles distincts disponibles dans l'API Gemini :
- Nano Banana 2 : modèle Gemini 3.1 Flash Image (
gemini-3.1-flash-image). Ce modèle est l'équivalent haute efficacité de Gemini 3 Pro Image. Il est optimisé pour la vitesse et les cas d'utilisation des développeurs à volume élevé. - Nano Banana Pro : modèle Gemini 3 Pro Image (
gemini-3-pro-image). Ce modèle est conçu pour la production d'assets professionnels. Il utilise un raisonnement avancé ("Réflexion") pour suivre des instructions complexes et générer du texte haute fidélité. - Nano Banana : modèle Gemini 2.5 Flash Image (
gemini-2.5-flash-image). Ce modèle est conçu pour la rapidité et l'efficacité. Il est optimisé pour les tâches à faible latence et à volume élevé.
Toutes les images générées incluent un filigrane SynthID.
Génération d'images (texte vers image)
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const prompt =
"Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme";
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"}
]
}'
Vous pouvez récupérer les données d'image générées à l'aide de la propriété interaction.output_image, qui renvoie le dernier bloc d'image généré. Pour en savoir plus sur les propriétés pratiques, consultez Présentation des interactions.
Retouche d'images (texte et image vers image)
Rappel : Assurez-vous de disposer des droits nécessaires sur toutes les images que vous importez. Ne générez aucun contenu qui porte atteinte aux droits d'autrui, y compris des vidéos ou images trompeuses, ou qui harcèlent ou nuisent à autrui. Votre utilisation de ce service d'IA générative est soumise à notre Règlement sur les utilisations interdites.
Fournissez une image et utilisez des requêtes textuelles pour ajouter, supprimer ou modifier des éléments, changer le style ou ajuster la correction colorimétrique.
L'exemple suivant montre comment importer des images encodées au format base64.
Pour en savoir plus sur les images multiples, les charges utiles plus importantes et les types MIME acceptés, consultez la page Compréhension des images.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open("/path/to/cat_image.png", "rb") as f:
image_bytes = f.read()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
with open("generated_image.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "path/to/cat_image.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const prompt = [
{ type: "text", text: "Create a picture of my cat eating a nano-banana in a" +
"fancy restaurant under the Gemini constellation" },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("gemini-native-image.png", buffer);
console.log("Image saved as gemini-native-image.png");
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Create a picture of my cat eating a nano-banana in a fancy restaurant under the Gemini constellation\"},
{
\"type\": \"image\",
\"mime_type\": \"image/jpeg\",
\"data\": \"<BASE64_IMAGE_DATA>\"
}
]
}"
Édition d'images multitour
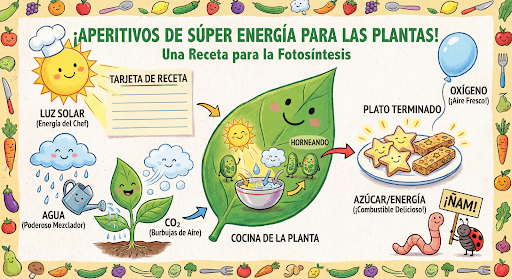
Continuez à générer et à modifier des images de manière conversationnelle. Nous vous recommandons d'utiliser les conversations multitours pour itérer sur les images. L'exemple suivant montre une requête permettant de générer une infographie sur la photosynthèse.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools=[{"type": "google_search"}],
)
with open("photosynthesis.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const ai = new GoogleGenAI({});
async function main() {
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plant's favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids' cookbook, suitable for a 4th grader.",
tools: [{"type": "google_search"}],
});
const generatedImage = interaction.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis.png", buffer);
console.log("Image saved as photosynthesis.png");
}
}
await main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Create a vibrant infographic that explains photosynthesis as if it were a recipe for a plants favorite food. Show the \"ingredients\" (sunlight, water, CO2) and the \"finished dish\" (sugar/energy). The style should be like a page from a colorful kids cookbook, suitable for a 4th grader."}
],
"tools": [{"type": "google_search"}]
}'

Vous pouvez ensuite utiliser previous_interaction_id pour modifier la langue de l'image et la passer à l'espagnol.
Python
interaction_2 = client.interactions.create(
model="gemini-3.1-flash-image",
input="Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id=interaction.id,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
},
)
generated_image = interaction_2.output_image
if generated_image:
with open("photosynthesis_spanish.png", "wb") as f:
f.write(base64.b64decode(generated_image.data))
JavaScript
const interaction2 = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Update this infographic to be in Spanish. Do not change any other elements of the image.",
previous_interaction_id: interaction.id,
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const generatedImage = interaction2.output_image;
if (generatedImage) {
const buffer = Buffer.from(generatedImage.data, "base64");
fs.writeFileSync("photosynthesis_spanish.png", buffer);
}
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Update this infographic to be in Spanish. Do not change any other elements of the image.",
"previous_interaction_id": "<PREVIOUS_INTERACTION_ID>",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
Nouveautés des modèles Gemini 3 Image
Gemini 3 propose des modèles de pointe pour la génération et la retouche d'images. Gemini 3.1 Flash Image est optimisé pour la vitesse et les cas d'utilisation à fort volume, tandis que Gemini 3 Pro Image est optimisé pour la production d'assets professionnels. Conçus pour gérer les workflows les plus complexes grâce à un raisonnement avancé, ils excellent dans les tâches complexes de création et de modification multitours.
- Sortie haute résolution : fonctionnalités de génération intégrées pour les visuels 1K, 2K et 4K.
- Gemini 3.1 Flash Image ajoute la résolution inférieure de 512 px (0,5K).
- Rendu de texte avancé : permet de générer du texte lisible et stylisé pour les infographies, les menus, les diagrammes et les supports marketing.
- Ancrage avec la recherche Google : le modèle peut utiliser la recherche Google comme outil pour vérifier des faits et générer des images basées sur des données en temps réel (par exemple, des cartes météo actuelles, des graphiques boursiers ou des événements récents).
- Gemini 3.1 Flash Image ajoute l'intégration de l'ancrage de la recherche d'images Google à la recherche sur le Web.
- Mode Raisonnement : le modèle utilise un processus de "réflexion" pour raisonner sur les requêtes complexes. Il génère des "images de réflexion" intermédiaires (visibles dans le backend, mais non facturées) pour affiner la composition avant de produire le résultat final de haute qualité.
- Jusqu'à 14 images de référence : vous pouvez désormais combiner jusqu'à 14 images de référence pour générer l'image finale.
- Nouveaux formats : Gemini 3.1 Flash Image ajoute les formats 1:4, 4:1, 1:8 et 8:1.
Utiliser jusqu'à 14 images de référence
Les modèles d'image Gemini 3 vous permettent de combiner jusqu'à 14 images de référence. Ces 14 images peuvent inclure les éléments suivants :
| Image Gemini 3.1 Flash | Gemini 3 Pro Image |
|---|---|
| Jusqu'à 10 images d'objets haute fidélité à inclure dans l'image finale | Jusqu'à six images d'objets haute fidélité à inclure dans l'image finale |
| Jusqu'à quatre images de personnages pour assurer leur cohérence | Jusqu'à cinq images de personnages pour assurer leur cohérence |
| N/A | Jusqu'à trois images à utiliser comme références de style |
Python
from google import genai
from google.genai import types
from PIL import Image
import base64
prompt = "An office group photo of these people, they are making funny faces."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "text",
"text": prompt,
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
],
response_format={
"type": "image",
"aspect_ratio": "5:4",
"image_size": "2K"
},
)
with open("office.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const input = [
{
type: "text",
text: "An office group photo of these people, they are making funny faces.",
},
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile1 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile2 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile3 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile4 },
{ type: "image", mime_type: "image/jpeg", data: base64ImageFile5 },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
response_format: {
type: "image",
aspect_ratio: "5:4",
image_size: "2K",
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('office.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"An office group photo of these people, they are making funny faces.\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_1>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_2>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_3>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_4>\"},
{\"type\": \"image\", \"mime_type\": \"image/png\", \"data\": \"<BASE64_DATA_IMG_5>\"}
],
\"response_format\": {
\"type\": \"image\",
\"aspect_ratio\": \"5:4\",
\"image_size\": \"2K\"
}
}"

Ancrage avec la recherche Google
Utilisez l'outil de recherche Google pour générer des images basées sur des informations en temps réel, comme des prévisions météo, des graphiques boursiers ou des événements récents.
Notez que lorsque vous utilisez l'ancrage avec la recherche Google pour générer des images, les résultats de recherche basés sur des images ne sont pas transmis au modèle de génération et sont exclus de la réponse (voir Ancrage avec la recherche Google Images).
Python
from google import genai
from google.genai import types
import base64
prompt = "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
tools=[{"type": "google_search"}],
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
},
)
with open("weather.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day",
tools: [{"type": "google_search"}],
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "16:9",
image_size: "2K"
},
});
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('weather.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Visualize the current weather forecast for the next 5 days in San Francisco as a clean, modern weather chart. Add a visual on what I should wear each day"}
],
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9"
}
}'

La réponse inclut les étapes google_search_call et google_search_result, ainsi que des annotations url_citation intégrées à l'étape de texte :
google_search_result: contientsearch_suggestions, un extrait HTML permettant d'afficher les suggestions de recherche dans votre UI.- Annotations
url_citation: citations intégrées dans l'étape de texte, qui relient des parties de la réponse à leurs sources Web.
Ancrage avec la recherche Google pour les images (3.1 Flash)
L'ancrage avec la recherche Google Images permet aux modèles d'utiliser les images Web récupérées via la recherche Google Images comme contexte visuel pour la génération d'images. La recherche d'images est un nouveau type de recherche au sein de l'outil existant d'ancrage avec la recherche Google. Elle fonctionne en parallèle de la recherche sur le Web standard.
Pour activer la recherche d'images, configurez l'outil google_search dans votre requête API et spécifiez image_search dans le tableau search_types. La recherche d'images peut être utilisée indépendamment ou en même temps que la recherche sur le Web.
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A detailed painting of a Timareta butterfly resting on a flower",
tools=[{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
)
JavaScript
import { GoogleGenAI } from "@google/genai";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A detailed painting of a Timareta butterfly resting on a flower",
tools: [{
"type": "google_search",
"search_types": ["web_search", "image_search"]
}]
});
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A detailed painting of a Timareta butterfly resting on a flower",
"tools": [{"type": "google_search", "search_types": ["web_search", "image_search"]}]
}'
Conditions requises pour l'affichage
Lorsque vous utilisez la recherche d'images dans l'ancrage avec la recherche Google, vous devez afficher le search_suggestions de l'étape google_search_result. Les exigences d'utilisation complètes sont détaillées dans les Conditions d'utilisation.
Réponse
Pour les réponses ancrées utilisant la recherche d'images, l'API renvoie des citations intégrées et des métadonnées d'attribution dans les étapes de la réponse :
Annotations
url_citation: citations intégrées dans le bloc de contenu textuel demodel_output, qui relient le contenu généré à sa source.google_search_result: contientsearch_suggestions, un extrait HTML permettant d'afficher les suggestions de recherche dans votre UI.
Génération d'images à partir de vidéos (3.1 Flash)
La génération d'images à partir de vidéos vous permet de créer des images en utilisant le contexte d'une vidéo comme référence multimodale. Cela est utile pour créer des miniatures vidéo de haute qualité, des affiches de films, des infographies récapitulatives ou de nouvelles illustrations inspirées d'une scène vidéo.
Lors de la génération, le modèle analyse les images vidéo dans leur contexte pour extraire les thèmes visuels et les événements clés. Il les utilise ensuite avec votre requête textuelle pour synthétiser l'image de sortie.
Vous pouvez transmettre des URL YouTube publiques directement dans votre requête d'API ou importer des fichiers vidéo locaux à l'aide de l'API Files.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{"type": "text", "text": "Generate a poster image that captures the key themes of this video."}
],
response_format={"type": "image", "aspect_ratio": "16:9"}
)
# Save the generated image part
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("video_poster.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
print("Image saved as video_poster.png")
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "video",
uri: "https://www.youtube.com/watch?v=UTdfxFyOQTI",
mime_type: "video/mp4"
},
{ type: "text", text: "Generate a poster image that captures the key themes of this video." }
],
response_format: {
type: "image",
aspect_ratio: "16:9"
}
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("video_poster.png", buffer);
console.log("Image saved as video_poster.png");
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{
"type": "video",
"uri": "https://www.youtube.com/watch?v=UTdfxFyOQTI",
"mime_type": "video/mp4"
},
{
"type": "text",
"text": "Generate a poster image that captures the key themes of this video."
}
],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

Générer des images jusqu'à la résolution 4K
Les modèles d'images Gemini 3 génèrent 1 000 images par défaut, mais peuvent également générer des images de 2 000, 4 000 et 512 px (05.K) (Gemini 3.1 Flash Image uniquement). Pour générer des composants de résolution supérieure, spécifiez image_size dans response_format.
Vous devez utiliser un "K" en majuscule (par exemple, 512px (05.K), 1K, 2K, 4K). Les paramètres en minuscules (par exemple, 1k) seront refusés.
Python
from google import genai
from google.genai import types
import base64
prompt = "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English."
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
},
)
print(interaction.output_text)
with open("butterfly.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
response_format: {
type: "image",
mime_type: "image/png",
aspect_ratio: "1:1",
image_size: "1K",
},
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('butterfly.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Da Vinci style anatomical sketch of a dissected Monarch butterfly. Detailed drawings of the head, wings, and legs on textured parchment with notes in English.",
"response_format": {
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "1:1",
"image_size": "1K"
}
}'
Voici un exemple d'image générée à partir de cette requête :

Processus de réflexion
Les modèles d'image Gemini 3 sont des modèles de réflexion qui utilisent un processus de raisonnement ("Réflexion") pour les requêtes complexes. Cette fonctionnalité est activée par défaut et ne peut pas être désactivée dans l'API. Pour en savoir plus sur le processus de réflexion, consultez le guide Réflexion de Gemini.
Le modèle génère jusqu'à deux images intermédiaires pour tester la composition et la logique. La dernière image de la section "Réflexion" est également l'image finale rendue.
Vous pouvez consulter les réflexions qui ont conduit à la production de l'image finale.
Python
for step in interaction.steps:
if step.type == "thought":
for content_block in step.summary:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
image = Image.open(io.BytesIO(base64.b64decode(content_block.data)))
image.show()
JavaScript
for (const step of interaction.steps) {
if (step.type === "thought") {
for (const contentBlock of step.summary) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, 'base64');
fs.writeFileSync('thought_image.png', buffer);
}
}
}
}
Texte et images entrelacés
Alors que les modèles de génération d'images standards ne génèrent que des images, certains modèles Gemini 3 avancés (comme gemini-3-pro-image) peuvent générer du contenu entrelacé, comme des histoires ou des guides d'instructions contenant à la fois des blocs de texte et des illustrations dans la même réponse.
Étant donné que la sortie est complexe et entrelacée, les propriétés pratiques telles que .output_image ou .output_text ne captureront pas la séquence complète. Pour accéder au contenu entrelacé et l'enregistrer, vous devez itérer manuellement sur steps :
Python
interaction = client.interactions.create(
model="gemini-3-pro-image",
input="Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
)
image_counter = 1
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
filename = f"butterfly_lifecycle_{image_counter}.png"
with open(filename, "wb") as f:
f.write(base64.b64decode(content_block.data))
print(f"\n[Saved illustration: {filename}]\n")
image_counter += 1
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3-pro-image",
input: "Write the story of the lifecycle of a monarch butterfly, interleave illustrations",
});
let imageCounter = 1;
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
const filename = `butterfly_lifecycle_${imageCounter}.png`;
fs.writeFileSync(filename, buffer);
console.log(`\n[Saved illustration: ${filename}]\n`);
imageCounter++;
}
}
}
}
Contrôler les niveaux de réflexion
Avec Gemini 3.1 Flash Image, vous pouvez contrôler la quantité de réflexion utilisée par le modèle pour trouver le bon équilibre entre qualité et latence. La valeur par défaut de thinking_level est minimal. Les niveaux acceptés sont minimal et high.
Python
from google import genai
from PIL import Image
import base64
import io
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A futuristic city built inside a giant glass bottle floating in space",
generation_config={"thinking_level": "high"},
)
print(interaction.output_text)
image = Image.open(io.BytesIO(base64.b64decode(interaction.output_image.data)))
image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A futuristic city built inside a giant glass bottle floating in space",
generation_config: { thinking_level: "high" },
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('image.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A futuristic city built inside a giant glass bottle floating in space",
"generation_config": {
"thinking_level": "high"
}
}'
Notez que les jetons de réflexion sont facturés par défaut pour les modèles de réflexion, car le processus de réflexion se produit toujours par défaut, que vous le consultiez ou non.
Autres modes de génération d'images
Bien que les modèles de génération d'images Nano Banana soient recommandés pour la plupart des cas d'utilisation, vous pouvez également explorer des modèles de génération d'images dédiés :
- Imagen : modèles texte-vers-image de Google optimisés pour générer des images de haute qualité.
- Veo : modèle de génération de vidéos de Google.
Générer des images par lot
Toutes les fonctionnalités de génération d'images décrites sur cette page peuvent également être exécutées en tant que jobs par lot à l'aide de l'API Batch, ce qui est idéal si vous devez générer de nombreuses images.Vous bénéficiez de limites de fréquence plus élevées en échange d'un délai de traitement pouvant aller jusqu'à 24 heures.
Guide et stratégies de requête
Cette section fournit des exemples et des modèles de requêtes pour les workflows courants de génération et de modification d'images. Chaque exemple inclut un modèle réutilisable et un exemple d'invite pour l'API Interactions.
Requêtes pour générer des images
Les exemples suivants montrent comment utiliser des requêtes textuelles pour générer différents types d'images.
1. Scènes photoréalistes
Décrivez une scène de manière très détaillée. Plus vous serez précis, plus vous aurez de contrôle sur les résultats.
Modèle
A photorealistic [type of shot] of a [subject description] in a [setting
description]. [Description of the light]. Shot from a [camera angle]
with a [lens type].
Prompt
A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format=[
{
"type": "image",
"mime_type": "image/jpeg",
"aspect_ratio": "16:9",
}
],
)
print(interaction.output_text)
with open("coral_reef.png", "wb") as f:
f.write(base64.b64decode(interaction.output_image.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
response_format: [
{
type: "image",
mime_type: "image/jpeg",
aspect_ratio: "16:9",
}
],
});
console.log(interaction.output_text);
const buffer = Buffer.from(interaction.output_image.data, 'base64');
fs.writeFileSync('coral_reef.png', buffer);
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A photorealistic wide-angle shot of a vibrant coral reef teeming with tropical fish. Crystal-clear turquoise water with sunbeams filtering down from the surface, illuminating a sea turtle gliding gracefully over the coral. Shot from a low perspective with a wide-angle lens. Aspect ratio 16:9.",
"response_format": {
"type": "image",
"mime_type": "image/png",
"aspect_ratio": "16:9"
}
}'

2. Illustrations et autocollants stylisés
Décrivez le style artistique, le sujet et le support. Soyez précis sur les détails visuels (lignes en gras, couleurs, etc.) pour obtenir des résultats cohérents.
Modèle
A [style] of a [subject, with details about accessories or actions]
doing [activity]. The design features [visual qualities, e.g., bold outlines,
cel-shading, etc.] and [color/background preference].
Prompt
A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("red_panda_sticker.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It's munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("red_panda_sticker.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A kawaii-style sticker of a happy red panda wearing a tiny bamboo hat. It is munching on a green bamboo leaf. The design features bold, clean outlines, simple cel-shading, and a vibrant color palette. The background must be white."
}'

3. Texte précis dans les images
Gemini excelle dans le rendu de texte. Décrivez clairement le texte, le style de police et la conception globale. Utilisez Gemini 3 Pro Image pour produire des assets professionnels.
Modèle
Create a [image type] for [brand/concept] with the text "[text to render]"
in a [font style]. The design should be [style description], with a
[color scheme].
Prompt
Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format={"type": "image", "aspect_ratio": "1:1"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("logo_example.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Create a modern, minimalist logo for a coffee shop called 'The Daily Grind'. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
response_format: { type: "image", aspect_ratio: "1:1" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("logo_example.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a modern, minimalist logo for a coffee shop called The Daily Grind. The text should be in a clean, bold, sans-serif font. The color scheme is black and white. Put the logo in a circle. Use a coffee bean in a clever way.",
"response_format": {
"type": "image",
"aspect_ratio": "1:1"
}
}'
4. Maquettes de produits et photographie commerciale
Idéal pour créer des photos de produits claires et professionnelles pour l'e-commerce, la publicité ou le branding.
Modèle
A high-resolution, studio-lit product photograph of a [product description]
on a [background surface/description]. The lighting is a [lighting setup,
e.g., three-point softbox setup] to [lighting purpose]. The camera angle is
a [angle type] to showcase [specific feature]. Ultra-realistic, with sharp
focus on [key detail]. [Aspect ratio].
Prompt
A high-resolution, studio-lit product photograph of a minimalist ceramic
coffee mug in matte black, presented on a polished concrete surface. The
lighting is a three-point softbox setup designed to create soft, diffused
highlights and eliminate harsh shadows. The camera angle is a slightly
elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with
sharp focus on the steam rising from the coffee. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("product_mockup.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("product_mockup.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A high-resolution, studio-lit product photograph of a minimalist ceramic coffee mug in matte black, presented on a polished concrete surface. The lighting is a three-point softbox setup designed to create soft, diffused highlights and eliminate harsh shadows. The camera angle is a slightly elevated 45-degree shot to showcase its clean lines. Ultra-realistic, with sharp focus on the steam rising from the coffee. Square image."
}'

5. Design minimaliste et espace négatif
Idéal pour créer des arrière-plans pour des sites Web, des présentations ou des supports marketing sur lesquels du texte sera superposé.
Modèle
A minimalist composition featuring a single [subject] positioned in the
[bottom-right/top-left/etc.] of the frame. The background is a vast, empty
[color] canvas, creating significant negative space. Soft, subtle lighting.
[Aspect ratio].
Prompt
A minimalist composition featuring a single, delicate red maple leaf
positioned in the bottom-right of the frame. The background is a vast, empty
off-white canvas, creating significant negative space for text. Soft,
diffused lighting from the top left. Square image.
Python
from google import genai
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("minimalist_design.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image.",
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("minimalist_design.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "A minimalist composition featuring a single, delicate red maple leaf positioned in the bottom-right of the frame. The background is a vast, empty off-white canvas, creating significant negative space for text. Soft, diffused lighting from the top left. Square image."
}'

6. Art séquentiel (panneau de bande dessinée / storyboard)
S'appuie sur la cohérence des personnages et la description des scènes pour créer des panneaux de narration visuelle. Pour obtenir des résultats précis avec du texte et des capacités de narration, ces requêtes fonctionnent mieux avec Gemini 3 Pro et Gemini 3.1 Flash Image.
Modèle
Make a 3 panel comic in a [style]. Put the character in a [type of scene].
Prompt
Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene.
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/jpeg"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("comic_panel.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/man_in_white_glasses.jpg";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene." },
{
type: "image",
mime_type: "image/jpeg",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("comic_panel.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": [
{"type": "text", "text": "Make a 3 panel comic in a gritty, noir art style with high-contrast black and white inks. Put the character in a humurous scene."},
{"type": "image", "data": "<BASE64_IMAGE_DATA>", "mime_type": "image/jpeg"}
]
}'
Entrée |
Sortie |

|

|
7. Ancrage avec la recherche Google
Utilisez la recherche Google pour générer des images basées sur des informations récentes ou en temps réel. Cela est utile pour les actualités, la météo et d'autres sujets urgents.
Prompt
Make a simple but stylish graphic of last night's Arsenal game in the Champion's League
Python
from google import genai
from google.genai import types
import base64
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools=[{"type": "google_search"}],
response_format={"type": "image", "aspect_ratio": "16:9"},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("football-score.jpg", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Make a simple but stylish graphic of last night's Arsenal game in the Champion's League",
tools: [{ type: "google_search" }],
response_format: { type: "image", aspect_ratio: "16:9", image_size: "2K" },
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("football-score.jpg", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Make a simple but stylish graphic of last nights Arsenal game in the Champions League",
"tools": [{"type": "google_search"}],
"response_format": {
"type": "image",
"aspect_ratio": "16:9"
}
}'

Requêtes pour modifier des images
Ces exemples montrent comment fournir des images en plus de vos requêtes textuelles pour l'édition, la composition et le transfert de style.
1. Ajouter et supprimer des éléments
Fournissez une image et décrivez votre modification. Le modèle correspondra au style, à la luminosité et à la perspective de l'image d'origine.
Modèle
Using the provided image of [subject], please [add/remove/modify] [element]
to/from the scene. Ensure the change is [description of how the change should
integrate].
Prompt
"Using the provided image of my cat, please add a small, knitted wizard hat
on its head. Make it look like it's sitting comfortably and matches the soft
lighting of the photo."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/cat_photo.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "text", "text": text_input},
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("cat_with_hat.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/cat_photo.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{ type: "text", text: "Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off." },
{
type: "image",
mime_type: "image/png",
data: base64Image
},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("cat_with_hat.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"text\", \"text\": \"Using the provided image of my cat, please add a small, knitted wizard hat on its head. Make it look like it's sitting comfortably and not falling off.\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"}
]
}"
Entrée |
Sortie |

|

|
2. Remplissage (masquage sémantique)
Définissez de manière conversationnelle un "masque" pour modifier une partie spécifique d'une image tout en laissant le reste intact.
Modèle
Using the provided image, change only the [specific element] to [new
element/description]. Keep everything else in the image exactly the same,
preserving the original style, lighting, and composition.
Prompt
"Using the provided image of a living room, change only the blue sofa to be
a vintage, brown leather chesterfield sofa. Keep the rest of the room,
including the pillows on the sofa and the lighting, unchanged."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/living_room.png', 'rb') as f:
image_bytes = f.read()
text_input = """Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("living_room_edited.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/living_room.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("living_room_edited.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Using the provided image of a living room, change only the blue sofa to be a vintage, brown leather chesterfield sofa. Keep the rest of the room, including the pillows on the sofa and the lighting, unchanged.\"}
]
}"
Entrée |
Sortie |

|

|
3. Transfert de style
Fournissez une image et demandez au modèle de recréer son contenu dans un autre style artistique.
Modèle
Transform the provided photograph of [subject] into the artistic style of [artist/art style]. Preserve the original composition but render it with [description of stylistic elements].
Prompt
"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/city.png', 'rb') as f:
image_bytes = f.read()
text_input = """Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(image_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("city_style_transfer.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imageData = fs.readFileSync("/path/to/your/city.png");
const base64Image = imageData.toString("base64");
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: [
{
type: "image",
mime_type: "image/png",
data: base64Image
},
{ type: "text", text: "Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows." },
],
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("city_style_transfer.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Transform the provided photograph of a modern city street at night into the artistic style of Vincent van Gogh's 'Starry Night'. Preserve the original composition of buildings and cars, but render all elements with swirling, impasto brushstrokes and a dramatic palette of deep blues and bright yellows.\"}
]
}"
Entrée |
Sortie |

|

|
4. Composition avancée : combiner plusieurs images
Fournissez plusieurs images comme contexte pour créer une nouvelle scène composite. C'est l'outil idéal pour les maquettes de produits ou les collages créatifs.
Modèle
Create a new image by combining the elements from the provided images. Take
the [element from image 1] and place it with/on the [element from image 2].
The final image should be a [description of the final scene].
Prompt
"Create a professional e-commerce fashion photo. Take the blue floral dress
from the first image and let the woman from the second image wear it.
Generate a realistic, full-body shot of the woman wearing the dress, with
the lighting and shadows adjusted to match the outdoor environment."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/dress.png', 'rb') as f:
dress_bytes = f.read()
with open('/path/to/your/model.png', 'rb') as f:
model_bytes = f.read()
text_input = """Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{
"type": "image",
"data": base64.b64encode(dress_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{
"type": "image",
"data": base64.b64encode(model_bytes).decode('utf-8'),
"mime_type": "image/png"
},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("fashion_ecommerce_shot.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/dress.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/model.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{
type: "image",
mime_type: "image/png",
data: base64Image1
},
{
type: "image",
mime_type: "image/png",
data: base64Image2
},
{ type: "text", text: "Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment." },
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("fashion_ecommerce_shot.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Create a professional e-commerce fashion photo. Take the blue floral dress from the first image and let the woman from the second image wear it. Generate a realistic, full-body shot of the woman wearing the dress, with the lighting and shadows adjusted to match the outdoor environment.\"}
}]
}"
Entrée 1 |
Saisie 2 |
Sortie |

|

|

|
5. Préservation des détails haute fidélité
Pour vous assurer que les détails importants (comme un visage ou un logo) sont conservés lors d'une modification, décrivez-les en détail dans votre demande de modification.
Modèle
Using the provided images, place [element from image 2] onto [element from
image 1]. Ensure that the features of [element from image 1] remain
completely unchanged. The added element should [description of how the
element should integrate].
Prompt
"Take the first image of the woman with brown hair, blue eyes, and a neutral
expression. Add the logo from the second image onto her black t-shirt.
Ensure the woman's face and features remain completely unchanged. The logo
should look like it's naturally printed on the fabric, following the folds
of the shirt."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/woman.png', 'rb') as f:
woman_bytes = f.read()
with open('/path/to/your/logo.png', 'rb') as f:
logo_bytes = f.read()
text_input = """Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(woman_bytes).decode('utf-8')},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(logo_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("woman_with_logo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath1 = "/path/to/your/woman.png";
const imageData1 = fs.readFileSync(imagePath1);
const base64Image1 = imageData1.toString("base64");
const imagePath2 = "/path/to/your/logo.png";
const imageData2 = fs.readFileSync(imagePath2);
const base64Image2 = imageData2.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image1},
{"type": "image", "mime_type":"image/png", "data": base64Image2},
{"type": "text", "text": "Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("woman_with_logo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_1>\"},
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA_2>\"},
{\"type\": \"text\", \"text\": \"Take the first image of the woman with brown hair, blue eyes, and a neutral expression. Add the logo from the second image onto her black t-shirt. Ensure the woman's face and features remain completely unchanged. The logo should look like it's naturally printed on the fabric, following the folds of the shirt.\"}
]
}"
Entrée 1 |
Saisie 2 |
Sortie |

|
|
|
6. Donner vie à quelque chose
Importez une esquisse ou un dessin et demandez au modèle de le transformer en image finalisée.
Modèle
Turn this rough [medium] sketch of a [subject] into a [style description]
photo. Keep the [specific features] from the sketch but add [new details/materials].
Prompt
"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/car_sketch.png', 'rb') as f:
sketch_bytes = f.read()
text_input = """Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=[
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(sketch_bytes).decode('utf-8')},
{"type": "text", "text": text_input}
],
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("car_photo.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const imagePath = "/path/to/your/car_sketch.png";
const imageData = fs.readFileSync(imagePath);
const base64Image = imageData.toString("base64");
const input = [
{"type": "image", "mime_type":"image/png", "data": base64Image},
{"type": "text", "text": "Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting."},
];
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: input,
});
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content) {
if (contentBlock.type === "text") {
console.log(contentBlock.text);
} else if (contentBlock.type === "image") {
const buffer = Buffer.from(contentBlock.data, "base64");
fs.writeFileSync("car_photo.png", buffer);
}
}
}
}
}
main();
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d "{
\"model\": \"gemini-3.1-flash-image\",
\"input\": [
{\"type\": \"image\", \"mime_type\":\"image/png\", \"data\": \"<BASE64_IMAGE_DATA>\"},
{\"type\": \"text\", \"text\": \"Turn this rough pencil sketch of a futuristic car into a polished photo of the finished concept car in a showroom. Keep the sleek lines and low profile from the sketch but add metallic blue paint and neon rim lighting.\"}
]
}"
Entrée |
Sortie |

|

|
7. Cohérence des personnages : vue à 360°
Vous pouvez générer des vues à 360 degrés d'un personnage en demandant de manière itérative différents angles. Pour obtenir les meilleurs résultats, incluez les images générées précédemment dans les requêtes suivantes afin de maintenir la cohérence. Pour les poses complexes, incluez une image de référence de la pose sélectionnée.
Modèle
A studio portrait of [person] against [background], [looking forward/in profile looking right/etc.]
Prompt
A studio portrait of this man against white, in profile looking right
Python
from google import genai
from PIL import Image
import base64
client = genai.Client()
with open('/path/to/your/man_in_white_glasses.jpg', 'rb') as f:
image_bytes = f.read()
text_input = """A studio portrait of this man against white, in profile looking right"""
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input={
{"type": "text", "text": text_input},
{"type": "image", "mime_type":"image/png", "data": base64.b64encode(image_bytes).decode('utf-8')}
},
)
for step in interaction.steps:
if step.type == "model_output":
for content_block in step.content:
if content_block.type == "text":
print(content_block.text)
elif content_block.type == "image":
with open("man_right_profile.png", "wb") as f:
f.write(base64.b64decode(content_block.data))
Entrée |
Sortie 1 |
Résultat 2 |
|
|

|

|
Bonnes pratiques
Pour passer de bons à excellents résultats, intégrez ces stratégies professionnelles à votre workflow.
- Soyez très précis : plus vous fournissez de détails, plus vous avez de contrôle. Au lieu de "armure fantastique", décrivez-la : "armure de plates elfique ornée, gravée de motifs en feuille d'argent, avec un col montant et des épaulières en forme d'ailes de faucon".
- Fournissez le contexte et l'intention : expliquez l'objectif de l'image. La compréhension du contexte par le modèle influencera le résultat final. Par exemple, la requête "Crée un logo pour une marque de soins pour la peau haut de gamme et minimaliste" donnera de meilleurs résultats que "Crée un logo".
- Répétez et affinez : ne vous attendez pas à obtenir une image parfaite du premier coup. Utilisez la nature conversationnelle du modèle pour apporter de petites modifications. Faites un suivi avec des requêtes telles que "C'est super, mais peux-tu rendre l'éclairage un peu plus chaud ?" ou "Garde tout pareil, mais rends l'expression du personnage plus sérieuse".
- Utilisez des instructions détaillées : pour les scènes complexes comportant de nombreux éléments, divisez votre requête en étapes. "Crée d'abord un arrière-plan représentant une forêt sereine et brumeuse à l'aube. Ensuite, au premier plan, ajoutez un ancien autel de pierre recouvert de mousse. Enfin, placez une épée lumineuse sur l'autel."
- Utilisez des requêtes négatives sémantiques : au lieu de dire "pas de voitures", décrivez la scène souhaitée de manière positive : "une rue vide et désertée sans aucun signe de circulation".
- Contrôler la caméra : utilisez un langage photographique et cinématographique pour contrôler la composition. Termes tels que
wide-angle shot,macro shotetlow-angle perspective.
Limites
- Pour des performances optimales, utilisez les langues suivantes : EN, ar-EG, de-DE, es-MX, fr-FR, hi-IN, id-ID, it-IT, ja-JP, ko-KR, pt-BR, ru-RU, ua-UA, vi-VN, zh-CN.
- La génération d'images n'est pas compatible avec les entrées audio. Les entrées vidéo ne sont acceptées que pour l'image Gemini 3.1 Flash.
- Le modèle ne respecte pas toujours le nombre exact d'images de sortie que l'utilisateur demande explicitement.
gemini-2.5-flash-imagefonctionne mieux avec un maximum de trois images en entrée, tandis quegemini-3-pro-imageaccepte cinq images haute fidélité et jusqu'à 14 images au total.gemini-3.1-flash-imageaccepte une ressemblance de caractères allant jusqu'à quatre caractères et une fidélité allant jusqu'à 10 objets dans un même workflow.- Lorsque vous générez du texte pour une image, Gemini fonctionne mieux si vous générez d'abord le texte, puis demandez une image avec le texte.
gemini-3.1-flash-imageL'ancrage avec la recherche Google ne permet pas d'utiliser des images de personnes issues de la recherche sur le Web pour le moment.- Toutes les images générées incluent un filigrane SynthID.
Configurations facultatives
Vous pouvez éventuellement configurer le format de sortie, les proportions et la taille de l'image à l'aide du paramètre response_format.
Format de sortie
Par défaut, le modèle renvoie des réponses textuelles et des réponses d'image. Vous pouvez configurer la réponse pour qu'elle ne renvoie que les images générées (en omettant le texte conversationnel) en spécifiant un format d'image dans le paramètre response_format.
Pour demander plusieurs modalités (par exemple, à la fois du texte et l'image générée), transmettez plutôt un tableau d'entrées de format à response_format.
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input="Write a short poem about a starry night and generate an image of it.",
response_format=[
{"type": "text"},
{"type": "image"},
],
)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: "Write a short poem about a starry night and generate an image of it.",
response_format: [
{ type: "text" },
{ type: "image" },
],
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Write a short poem about a starry night and generate an image of it.",
"response_format": [
{ "type": "text" },
{ "type": "image" }
]
}'
Formats et taille d'image
Par défaut, le modèle fait correspondre la taille de l'image de sortie à celle de votre image d'entrée, ou génère des carrés au format 1:1. Vous pouvez contrôler les proportions et la taille de l'image de sortie à l'aide des champs aspect_ratio et image_size sous response_format lorsque type est défini sur "image".
Python
interaction = client.interactions.create(
model="gemini-3.1-flash-image",
input=prompt,
response_format={
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K",
},
)
JavaScript
const interaction = await ai.interactions.create({
model: "gemini-3.1-flash-image",
input: prompt,
response_format: {
type: "image",
aspect_ratio: "16:9",
image_size: "2K",
},
});
REST
curl -s -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.1-flash-image",
"input": "Create a picture of a nano banana dish in a fancy restaurant with a Gemini theme",
"response_format": {
"type": "image",
"aspect_ratio": "16:9",
"image_size": "2K"
}
}'
Les différents ratios disponibles et la taille de l'image générée sont listés dans les tableaux suivants :
Image Flash 3.1
| Format | Résolution de 512 px | 0,5 k jetons | Résolution 1K | 1 000 jetons | Résolution 2K | 2 000 jetons | Résolution 4K | 4 000 jetons |
|---|---|---|---|---|---|---|---|---|
| 1:1 | 512 x 512 | 747 | 1024x1024 | 1120 | 2048 x 2048 | 1120 | 4 096 x 4 096 | 2000 |
| 1:4 | 256 x 1 024 | 747 | 512 x 2 048 | 1120 | 1024x4096 | 1120 | 2048 x 8192 | 2000 |
| 1:8 | 192 x 1 536 | 747 | 384 x 3 072 | 1120 | 768 x 6 144 | 1120 | 1536 x 12288 | 2000 |
| 2:3 | 424 x 632 | 747 | 848 x 1 264 | 1120 | 1696 x 2528 | 1120 | 3392 x 5056 | 2000 |
| 3:2 | 632 x 424 | 747 | 1 264 x 848 | 1120 | 2528 x 1696 | 1120 | 5056 x 3392 | 2000 |
| 3:4 | 448 x 600 | 747 | 896 x 1200 | 1120 | 1792x2400 | 1120 | 3584 x 4800 | 2000 |
| 4:1 | 1024x256 | 747 | 2048 x 512 | 1120 | 4 096 x 1 024 | 1120 | 8192 x 2048 | 2000 |
| 4:3 | 600 x 448 | 747 | 1 200 x 896 | 1120 | 2400x1792 | 1120 | 4 800 x 3 584 | 2000 |
| 4:5 | 464 x 576 | 747 | 928 x 1 152 | 1120 | 1856 x 2304 | 1120 | 3712 x 4608 | 2000 |
| 5:4 | 576 x 464 | 747 | 1152x928 | 1120 | 2304 x 1856 | 1120 | 4608 x 3712 | 2000 |
| 8:1 | 1536x192 | 747 | 3072 x 384 | 1120 | 6 144 x 768 | 1120 | 12 288 x 1 536 | 2000 |
| 9:16 | 384 x 688 | 747 | 768 x 1 376 | 1120 | 1536 x 2752 | 1120 | 3072 x 5504 | 2000 |
| 16:9 | 688x384 | 747 | 1 376 x 768 | 1120 | 2752 x 1536 | 1120 | 5504 x 3072 | 2000 |
| 21:9 | 792 x 168 | 747 | 1 584 x 672 | 1120 | 3168x1344 | 1120 | 6336 x 2688 | 2000 |
3 Pro Image
| Format | Résolution 1K | 1 000 jetons | Résolution 2K | 2 000 jetons | Résolution 4K | 4 000 jetons |
|---|---|---|---|---|---|---|
| 1:1 | 1024x1024 | 1120 | 2048 x 2048 | 1120 | 4 096 x 4 096 | 2000 |
| 2:3 | 848 x 1 264 | 1120 | 1696 x 2528 | 1120 | 3392 x 5056 | 2000 |
| 3:2 | 1 264 x 848 | 1120 | 2528 x 1696 | 1120 | 5056 x 3392 | 2000 |
| 3:4 | 896 x 1200 | 1120 | 1792x2400 | 1120 | 3584 x 4800 | 2000 |
| 4:3 | 1 200 x 896 | 1120 | 2400x1792 | 1120 | 4 800 x 3 584 | 2000 |
| 4:5 | 928 x 1 152 | 1120 | 1856 x 2304 | 1120 | 3712 x 4608 | 2000 |
| 5:4 | 1152x928 | 1120 | 2304 x 1856 | 1120 | 4608 x 3712 | 2000 |
| 9:16 | 768 x 1 376 | 1120 | 1536 x 2752 | 1120 | 3072 x 5504 | 2000 |
| 16:9 | 1 376 x 768 | 1120 | 2752 x 1536 | 1120 | 5504 x 3072 | 2000 |
| 21:9 | 1 584 x 672 | 1120 | 3168x1344 | 1120 | 6336 x 2688 | 2000 |
Gemini 2.5 Flash Image
| Format | Solution | Jetons |
|---|---|---|
| 1:1 | 1024x1024 | 1290 |
| 2:3 | 832 x 1 248 | 1290 |
| 3:2 | 1 248 x 832 | 1290 |
| 3:4 | 864 x 1 184 | 1290 |
| 4:3 | 1 184 x 864 | 1290 |
| 4:5 | 896 x 1 152 | 1290 |
| 5:4 | 1152x896 | 1290 |
| 9:16 | 768 x 1 344 | 1290 |
| 16:9 | 1 344 x 768 | 1290 |
| 21:9 | 1 536 x 672 | 1290 |
Sélection du modèle
Choisissez le modèle le mieux adapté à votre cas d'utilisation spécifique.
Gemini 3.1 Flash Image (Nano Banana 2) devrait être votre modèle de génération d'images de référence, car il offre le meilleur équilibre entre performances globales, intelligence, coût et latence. Pour en savoir plus, consultez la page des tarifs et des fonctionnalités des modèles.
Gemini 3 Pro Image (Nano Banana Pro) est conçu pour la production d'assets professionnels et les instructions complexes. Ce modèle est ancré dans le monde réel grâce à la recherche Google. Il dispose d'un processus de "réflexion" par défaut qui affine la composition avant la génération et peut générer des images d'une résolution allant jusqu'à 4K. Pour en savoir plus, consultez la page des tarifs et des fonctionnalités des modèles.
Gemini 2.5 Flash Image (Nano Banana) est conçu pour la rapidité et l'efficacité. Ce modèle est optimisé pour les tâches à faible latence et à volume élevé. Il génère des images d'une résolution de 1 024 px. Pour en savoir plus, consultez la page des tarifs et des fonctionnalités des modèles.
Quand utiliser Imagen ?
En plus d'utiliser les fonctionnalités de génération d'images intégrées à Gemini, vous pouvez également accéder à Imagen, notre modèle spécialisé dans la génération d'images, via l'API Gemini. Prévoyez de migrer avant la date d'arrêt.
Étape suivante
- Consultez le guide Veo pour découvrir comment générer des vidéos avec l'API Gemini.
- Pour en savoir plus sur les modèles Gemini, consultez Modèles Gemini.