
|
|
|
|
|
 Afficher la source sur GitHub Afficher la source sur GitHub
|
Ce guide vous explique comment affiner Gemma sur un ensemble de données de PNJ de jeux mobiles à l'aide de Transformers et de TRL de Hugging Face. Vous pourrez découvrir :
- Configurer l'environnement de développement
- Préparer l'ensemble de données de réglage fin
- Affinage complet du modèle Gemma à l'aide de TRL et de SFTTrainer
- Tester l'inférence du modèle et les vérifications de l'ambiance
Configurer l'environnement de développement
La première étape consiste à installer les bibliothèques Hugging Face, y compris TRL et les ensembles de données, pour affiner le modèle ouvert, y compris différentes techniques RLHF et d'alignement.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
Remarque : Si vous utilisez un GPU avec une architecture Ampere (comme NVIDIA L4) ou plus récente, vous pouvez utiliser Flash Attention. Flash Attention est une méthode qui accélère considérablement les calculs et réduit l'utilisation de la mémoire de quadratique à linéaire en termes de longueur de séquence, ce qui permet d'accélérer l'entraînement jusqu'à trois fois. Pour en savoir plus, consultez FlashAttention.
Avant de commencer l'entraînement, vous devez vous assurer d'avoir accepté les conditions d'utilisation de Gemma. Vous pouvez accepter la licence sur Hugging Face en cliquant sur le bouton "Agree and access repository" (Accepter et accéder au dépôt) sur la page du modèle à l'adresse http://huggingface.co/google/gemma-3-270m-it.
Une fois la licence acceptée, vous avez besoin d'un jeton Hugging Face valide pour accéder au modèle. Si vous exécutez le code dans Google Colab, vous pouvez utiliser votre jeton Hugging Face de manière sécurisée à l'aide des secrets Colab. Sinon, vous pouvez définir le jeton directement dans la méthode login. Assurez-vous que votre jeton dispose également d'un accès en écriture, car vous allez transférer votre modèle vers le Hub pendant l'entraînement.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
Vous pouvez conserver les résultats sur la machine virtuelle locale de Colab. Toutefois, nous vous recommandons vivement d'enregistrer vos résultats intermédiaires dans Google Drive. Cela garantit la sécurité de vos résultats d'entraînement et vous permet de comparer et de sélectionner facilement le meilleur modèle.
from google.colab import drive
drive.mount('/content/drive')
Sélectionnez le modèle de base à affiner, ajustez le répertoire de points de contrôle et le taux d'apprentissage.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
Créer et préparer l'ensemble de données de réglage fin
L'ensemble de données bebechien/MobileGameNPC fournit un petit échantillon de conversations entre un joueur et deux PNJ extraterrestres (un Martien et un Vénusien), chacun ayant un style de parole unique. Par exemple, le PNJ martien parle avec un accent qui remplace les sons "s" par des "z", utilise "da" pour "le", "diz" pour "ce" et inclut des clics occasionnels comme *k'tak*.
Cet ensemble de données illustre un principe clé du réglage fin : la taille de l'ensemble de données requis dépend du résultat souhaité.
- Pour enseigner au modèle une variation stylistique d'une langue qu'il connaît déjà, comme l'accent martien, un petit ensemble de données contenant seulement 10 à 20 exemples peut suffire.
- Toutefois, pour enseigner au modèle une langue extraterrestre entièrement nouvelle ou mixte, un ensemble de données beaucoup plus volumineux serait nécessaire.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
Affiner Gemma à l'aide de TRL et de SFTTrainer
Vous êtes maintenant prêt à affiner votre modèle. Hugging Face TRL SFTTrainer facilite le réglage fin supervisé des LLM ouverts. SFTTrainer est une sous-classe de Trainer de la bibliothèque transformers et est compatible avec toutes les mêmes fonctionnalités.
Le code suivant charge le modèle et le tokenizer Gemma depuis Hugging Face.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
Avant le réglage précis
La sortie ci-dessous montre que les fonctionnalités prêtes à l'emploi ne sont peut-être pas suffisantes pour ce cas d'utilisation.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
L'exemple ci-dessus vérifie la fonction principale du modèle, qui consiste à générer des dialogues dans le jeu. L'exemple suivant est conçu pour tester la cohérence des personnages. Nous mettons le modèle au défi avec une requête hors sujet. Par exemple, Sorry, you are a game NPC., qui ne fait pas partie de la base de connaissances du personnage.
L'objectif est de voir si le modèle peut rester dans son rôle au lieu de répondre à la question hors contexte. Cela servira de référence pour évaluer l'efficacité du processus d'affinage dans l'instauration de la personnalité souhaitée.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
Bien que nous puissions utiliser l'ingénierie des requêtes pour orienter le ton de l'IA, les résultats peuvent être imprévisibles et ne pas toujours correspondre à la personnalité souhaitée.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
Formation
Avant de commencer l'entraînement, vous devez définir les hyperparamètres que vous souhaitez utiliser dans une instance SFTConfig.
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
Vous disposez désormais de tous les éléments nécessaires pour créer votre SFTTrainer et commencer à entraîner votre modèle.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
Commencez l'entraînement en appelant la méthode train().
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
Pour représenter graphiquement les pertes d'entraînement et de validation, vous devez généralement extraire ces valeurs de l'objet TrainerState ou des journaux générés pendant l'entraînement.
Des bibliothèques comme Matplotlib peuvent ensuite être utilisées pour visualiser ces valeurs au cours des étapes ou des époques d'entraînement. L'axe X représente les étapes ou les époques d'entraînement, et l'axe Y représente les valeurs de perte correspondantes.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
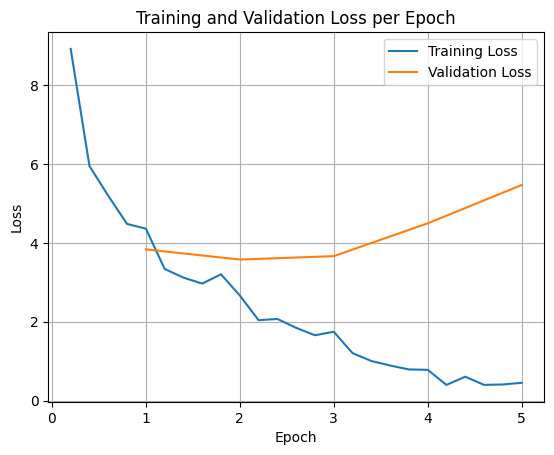
Cette visualisation permet de surveiller le processus d'entraînement et de prendre des décisions éclairées concernant le réglage des hyperparamètres ou l'arrêt précoce.
La perte d'entraînement mesure l'erreur sur les données sur lesquelles le modèle a été entraîné, tandis que la perte de validation mesure l'erreur sur un ensemble de données distinct que le modèle n'a jamais vu auparavant. La surveillance des deux permet de détecter le surapprentissage (lorsque le modèle donne de bons résultats avec les données d'entraînement, mais de mauvais résultats avec les données inconnues).
- Perte de validation >> perte d'entraînement : surapprentissage
- Perte de validation > perte d'entraînement : surapprentissage
- Perte de validation < perte d'entraînement : sous-apprentissage
- Perte de validation << perte d'entraînement : sous-apprentissage
Tester l'inférence du modèle
Une fois l'entraînement terminé, vous devez évaluer et tester votre modèle. Vous pouvez charger différents échantillons à partir de l'ensemble de données de test et évaluer le modèle sur ces échantillons.
Pour ce cas d'utilisation particulier, le meilleur modèle est une question de préférence. Il est intéressant de noter que ce que nous appelons normalement "surapprentissage" peut être très utile pour un PNJ de jeu. Il oblige le modèle à oublier les informations générales et à se concentrer plutôt sur le personnage et les caractéristiques spécifiques sur lesquels il a été entraîné, ce qui lui permet de rester cohérent.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Chargeons toutes les questions de l'ensemble de données de test et générons des résultats.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
Si vous essayez notre requête généraliste d'origine, vous verrez que le modèle tente toujours de répondre dans le style pour lequel il a été entraîné. Dans cet exemple, le surapprentissage et l'oubli catastrophique sont en fait bénéfiques pour le PNJ du jeu, car il commencera à oublier les connaissances générales qui ne sont peut-être pas applicables. Cela vaut également pour les autres types d'affinage complet, dont l'objectif est de limiter la sortie à des formats de données spécifiques.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
Résumé et étapes suivantes
Ce tutoriel vous a montré comment affiner un modèle complet à l'aide de TRL. Consultez ensuite les documents suivants :
- Découvrez comment affiner Gemma pour les tâches de texte à l'aide de Hugging Face Transformers.
- Découvrez comment affiner Gemma pour les tâches de vision à l'aide de Hugging Face Transformers.
- Découvrez comment déployer sur Cloud Run.