
В этом руководстве приведены инструкции по преобразованию моделей Gemma в формате Hugging Face Safetensors ( .safetensors ) в формат файла MediaPipe Task ( .task ). Это преобразование необходимо для развертывания предварительно обученных или дообученных моделей Gemma для выполнения инференции на устройствах Android и iOS с использованием API MediaPipe LLM Inference и среды выполнения LiteRT.
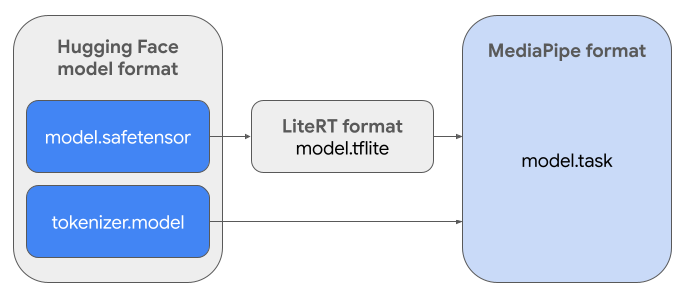
Для создания необходимого пакета задач ( .task ) вам понадобится LiteRT Torch . Этот инструмент экспортирует модели PyTorch в модели LiteRT с множественными сигнатурами ( .tflite ), которые совместимы с API вывода MediaPipe LLM и подходят для работы на процессорах в мобильных приложениях.
Итоговый файл .task представляет собой самодостаточный пакет, необходимый для MediaPipe, и включает в себя модель LiteRT, модель токенизатора и необходимые метаданные. Этот пакет необходим, поскольку токенизатор (который преобразует текстовые подсказки в векторные представления токенов для модели) должен быть упакован вместе с моделью LiteRT для обеспечения сквозного вывода.
Вот пошаговое описание процесса:
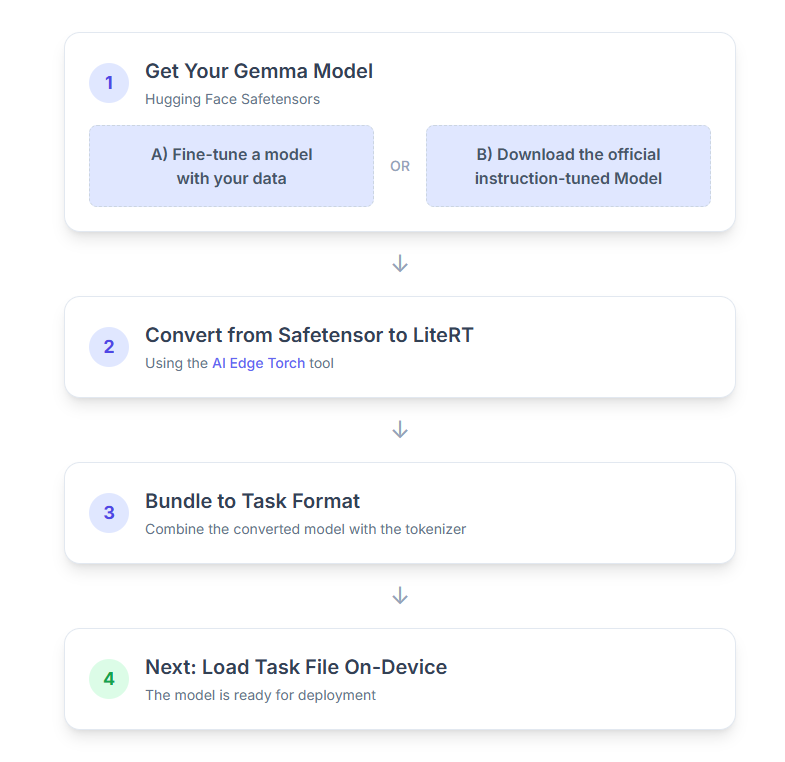
1. Получите свою модель Gemma.
У вас есть два варианта начала.
Вариант А. Использовать существующую, точно настроенную модель.
Если у вас уже подготовлена доработанная модель Gemma , просто перейдите к следующему шагу.
Вариант B. Скачать официальную инструкцию по настройке модели.
Если вам нужна модель, вы можете скачать модель Джеммы с инструкциями из Hugging Face Hub.
Настройте необходимые инструменты:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
Скачать модель:
Модели на платформе Hugging Face Hub идентифицируются по идентификатору модели, обычно в формате <organization_or_username>/<model_name> . Например, чтобы загрузить официальную модель Google Gemma 3 270M с настроенными инструкциями, используйте:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. Преобразуйте и квантуйте модель в формат LiteRT.
Настройте виртуальное окружение Python и установите последнюю стабильную версию пакета LiteRT Torch:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
Используйте следующий скрипт для преобразования Safetensor в модель LiteRT.
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
Учтите, что этот процесс занимает много времени и зависит от скорости обработки данных вашим компьютером. Для сравнения, на 8-ядерном процессоре 2025 модель 270M обрабатывается более 5-10 минут, а модель 1B — примерно 10-30 минут.
Итоговый результат, модель LiteRT, будет сохранен в указанную вами OUTPUT_DIR_PATH .
Настройте следующие значения в соответствии с ограничениями по объему памяти и производительности целевого устройства.
-
kv_cache_max_len: Определяет общий размер рабочей памяти модели (кэш ключ-значение). Эта емкость является жестким ограничением и должна быть достаточной для хранения суммарной суммы токенов запроса (предварительное заполнение) и всех последующих сгенерированных токенов (декодирование). -
prefill_seq_len: Задает количество токенов во входном запросе для предварительного заполнения фрагментами. При обработке входного запроса с использованием предварительного заполнения фрагментами вся последовательность (например, 50 000 токенов) вычисляется не сразу; вместо этого она разбивается на управляемые сегменты (например, фрагменты по 2048 токенов), которые последовательно загружаются в кэш, чтобы предотвратить ошибку нехватки памяти. -
quantize: строка для выбранных схем квантования. Ниже приведен список доступных рецептов квантования для Gemma 3.-
none: Нет квантования -
fp16: Веса FP16, активации FP32 и вычисления с плавающей запятой для всех операций. -
dynamic_int8: активации FP32, веса INT8 и вычисления целых чисел. -
weight_only_int8: активации FP32, веса INT8 и вычисления с плавающей запятой.
-
3. Создайте пакет задач из LiteRT и токенизатора.
Настройте виртуальное окружение Python и установите пакет Python mediapipe :
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
Для сборки модели используйте библиотеку genai.bundler :
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
Функция bundler.create_bundle создает файл .task , содержащий всю необходимую информацию для запуска модели.
4. Вывод результатов с помощью Mediapipe на Android
Инициализируйте задачу с основными параметрами конфигурации:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
Для генерации текстового ответа используйте метод generateResponse() .
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
Для потоковой передачи ответа используйте метод generateResponseAsync() .
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
Для получения дополнительной информации см. руководство по LLM Inference для Android .
Следующие шаги
Создавайте и исследуйте больше возможностей с помощью моделей Gemma:
- Разверните Gemma на мобильных устройствах
- Доработайте Gemma для текстовых задач с помощью Hugging Face Transformers.
- Настройте Gemma для решения задач, требующих улучшения зрения, с помощью трансформеров Hugging Face Transformers.
- Полная доработка модели с использованием трансформеров обнимающихся лиц.