
| | | | |  Просмотреть исходный код на GitHub Просмотреть исходный код на GitHub |
Это руководство расскажет вам, как настроить Джемму в наборе данных NPC для мобильной игры с помощью Hugging Face Transformers и TRL . Вы узнаете:
- Настройка среды разработки
- Подготовка набора данных для тонкой настройки
- Полная настройка модели Gemma с использованием TRL и SFTTrainer
- Вывод тестовой модели и проверки вибрации
Настройка среды разработки
Первым шагом является установка библиотек Hugging Face, включая TRL, и наборов данных для точной настройки открытой модели, включая различные методы RLHF и выравнивания.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
Примечание: Если вы используете графический процессор с архитектурой Ampere (например, NVIDIA L4) или более новой, вы можете использовать Flash Attention. Flash Attention — это метод, который значительно ускоряет вычисления и снижает потребление памяти с квадратичной до линейной зависимости от длины последовательности, что приводит к ускорению обучения до 3 раз. Узнайте больше на Flash Attention .
Прежде чем начать обучение, убедитесь, что вы приняли условия использования Gemma. Вы можете принять условия лицензии Hugging Face , нажав кнопку «Согласен и получи доступ к репозиторию» на странице модели по адресу: http://huggingface.co/google/gemma-3-270m-it
После принятия лицензии вам потребуется действительный токен Hugging Face для доступа к модели. Если вы работаете в Google Colab, вы можете безопасно использовать свой токен Hugging Face, используя секреты Colab, или же вы можете указать токен непосредственно в методе login . Убедитесь, что у вашего токена также есть права на запись, поскольку вы отправляете модель в Hub во время обучения.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
Вы можете сохранить результаты на локальной виртуальной машине Colab. Однако мы настоятельно рекомендуем сохранять промежуточные результаты на Google Диске. Это гарантирует сохранность результатов обучения и позволяет легко сравнивать результаты и выбирать наилучшую модель.
from google.colab import drive
drive.mount('/content/drive')
Выберите базовую модель для точной настройки, настройте каталог контрольных точек и скорость обучения.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
Создайте и подготовьте набор данных для тонкой настройки
Набор данных bebechien/MobileGameNPC содержит небольшой пример диалогов между игроком и двумя инопланетными NPC (марсианином и венерианцем), каждый из которых обладает уникальным стилем речи. Например, марсианский NPC говорит с акцентом, заменяя звук «с» на «з», использует «да» вместо «the», «диз» вместо «this», а также иногда использует щелчки, например, *k'tak* .
Этот набор данных демонстрирует ключевой принцип тонкой настройки: требуемый размер набора данных зависит от желаемого результата.
- Чтобы научить модель стилистическому варианту языка, который она уже знает, например, акценту марсиан, может быть достаточно небольшого набора данных, содержащего всего 10–20 примеров.
- Однако для обучения модели совершенно новому или смешанному иностранному языку потребуется значительно больший набор данных.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
Тонкая настройка Gemma с помощью TRL и SFTTrainer
Теперь вы готовы к тонкой настройке вашей модели. SFTTrainer Hugging Face TRL упрощает управление тонкой настройкой открытых LLM. SFTTrainer — это подкласс Trainer из библиотеки transformers , поддерживающий все те же функции.
Следующий код загружает модель Gemma и токенизатор из Hugging Face.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
Перед тонкой настройкой
Приведенный ниже вывод показывает, что готовых возможностей может быть недостаточно для этого варианта использования.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
В приведенном выше примере проверяется основная функция модели — генерация игровых диалогов. Следующий пример предназначен для проверки согласованности персонажей. Мы проверяем модель, используя подсказку, не относящуюся к теме. Например, Sorry, you are a game NPC. , которая выходит за рамки базы знаний персонажа.
Цель — проверить, способна ли модель оставаться в образе, а не отвечать на вопросы, выпадающие из контекста. Это послужит отправной точкой для оценки того, насколько эффективно процесс тонкой настройки позволил создать желаемый образ.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
И хотя мы можем использовать оперативную инженерию, чтобы управлять его тоном, результаты могут быть непредсказуемыми и не всегда соответствовать желаемому образу.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
Обучение
Прежде чем начать обучение, вам необходимо определить гиперпараметры, которые вы хотите использовать в экземпляре SFTConfig .
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
Теперь у вас есть все необходимые строительные блоки для создания SFTTrainer и начала обучения вашей модели.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
Начните обучение, вызвав метод train() .
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
Чтобы построить график потерь при обучении и проверке, обычно необходимо извлечь эти значения из объекта TrainerState или журналов, сгенерированных во время обучения.
Затем можно использовать библиотеки, такие как Matplotlib, для визуализации этих значений на этапах обучения или эпохах. По оси x откладываются этапы обучения или эпохи, а по оси y — соответствующие значения потерь.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
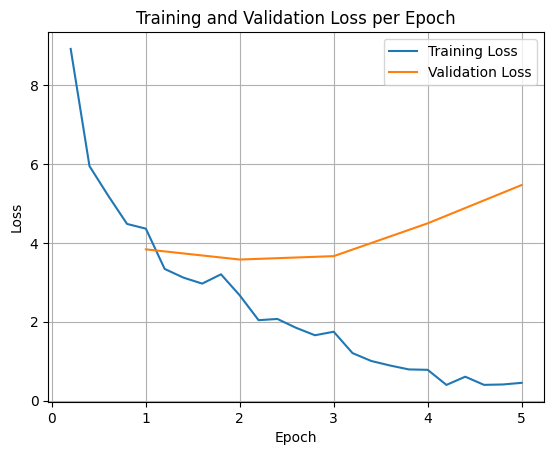
Такая визуализация помогает контролировать процесс обучения и принимать обоснованные решения о настройке гиперпараметров или ранней остановке.
Потери при обучении измеряют ошибку на данных, на которых обучалась модель, а потери при проверке — ошибку на отдельном наборе данных, с которым модель ранее не сталкивалась. Мониторинг обоих типов данных помогает обнаружить переобучение (когда модель хорошо работает на обучающих данных, но плохо на данных, ранее не наблюдавшихся).
- потери при проверке >> потери при обучении: переобучение
- потери при проверке > потери при обучении: некоторое переобучение
- потери при проверке < потери при обучении: некоторая недоподготовка
- потеря валидации << потеря обучения: недообучение
Вывод тестовой модели
После завершения обучения вам необходимо оценить и протестировать свою модель. Вы можете загрузить различные выборки из тестового набора данных и оценить работу модели на этих выборках.
В данном конкретном случае выбор оптимальной модели — вопрос предпочтений. Интересно, что то, что мы обычно называем «переобучением», может быть очень полезно для игрового NPC. Оно заставляет модель забыть общую информацию и вместо этого сосредоточиться на конкретной персоне и характеристиках, на которых она была обучена, обеспечивая её постоянство в образе.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Давайте загрузим все вопросы из тестового набора данных и сгенерируем выходные данные.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
Если вы попробуете нашу исходную подсказку общего характера, то увидите, что модель всё ещё пытается отвечать в стиле обучения. В этом примере переобучение и катастрофическое забывание на самом деле полезны для игрового NPC, поскольку он начинает забывать общие знания, которые могут быть неприменимы. Это также верно для других типов полной тонкой настройки, где цель — ограничить вывод определёнными форматами данных.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
Резюме и дальнейшие шаги
В этом руководстве мы рассмотрели, как полностью настроить модель с помощью TRL. Ознакомьтесь со следующими документами:
- Узнайте, как настроить Джемму для выполнения текстовых задач с помощью Hugging Face Transformers .
- Узнайте, как точно настроить Джемму для решения задач, связанных со зрением, с помощью Hugging Face Transformers .
- Узнайте, как выполнить развертывание в Cloud Run