
本指南提供了相关说明,可将 Hugging Face Safetensors 格式 (.safetensors) 的 Gemma 模型转换为 MediaPipe Task 文件格式 (.task)。此转换对于使用 MediaPipe LLM Inference API 和 LiteRT 运行时在 Android 和 iOS 上部署预训练或微调的 Gemma 模型以进行设备端推理至关重要。
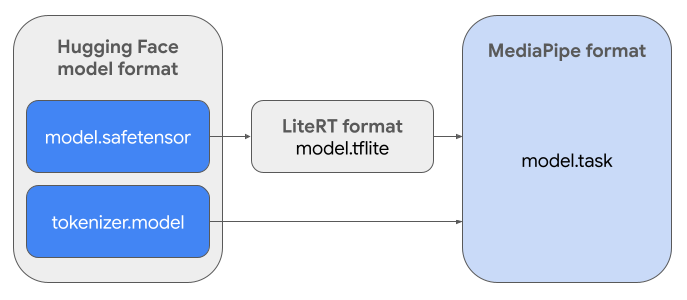
如需创建所需的任务软件包 (.task),您将使用 LiteRT Torch。此工具可将 PyTorch 模型导出为多签名 LiteRT (.tflite) 模型,这些模型与 MediaPipe LLM Inference API 兼容,适合在移动应用中的 CPU 后端上运行。
最终的 .task 文件是 MediaPipe 所需的自包含软件包,其中捆绑了 LiteRT 模型、分词器模型和必要的元数据。此软件包是必需的,因为分词器(用于将文本提示转换为模型的 token 嵌入)必须与 LiteRT 模型打包在一起,才能实现端到端推理。
下面详细介绍了这个流程:
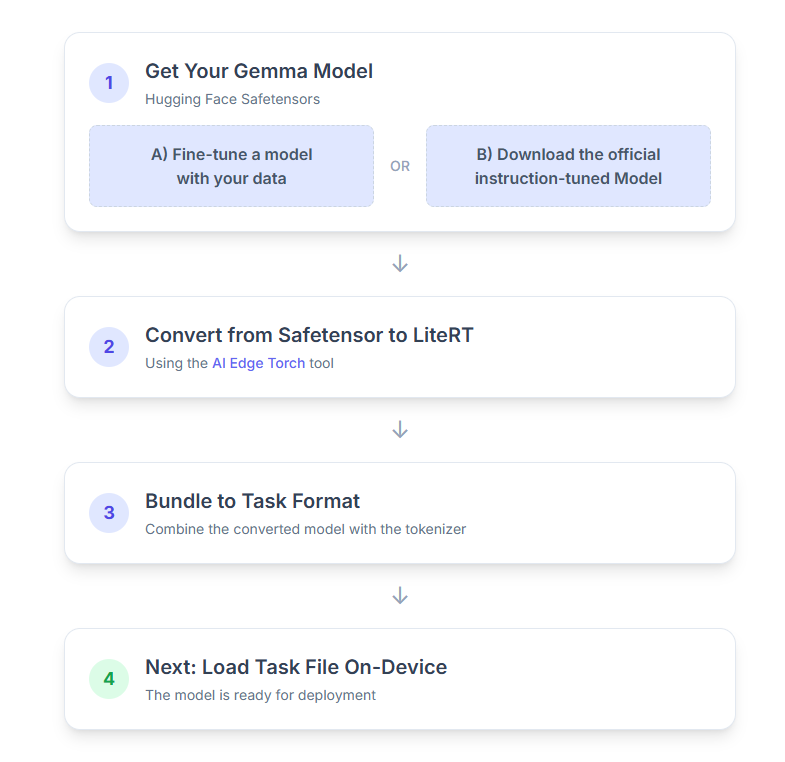
1. 获取 Gemma 模型
您可以通过以下两种方式开始使用。
选项 A。使用现有的微调模型
如果您已准备好经过微调的 Gemma 模型,只需继续执行下一步即可。
选项 B。下载官方指令调优模型
如果您需要模型,可以从 Hugging Face Hub 下载指令调优的 Gemma。
设置必要的工具:
python -m venv hfsource hf/bin/activatepip install huggingface_hub[cli]
下载模型:
Hugging Face Hub 上的模型通过模型 ID 进行标识,通常采用 <organization_or_username>/<model_name> 格式。例如,如需下载 Google 官方的 Gemma 3 270M 指令调优模型,请使用以下命令:
hf download google/gemma-3-270m-it --local-dir "PATH_TO_HF_MODEL"#"google/gemma-3-1b-it", etc
2. 将模型转换为 LiteRT 并进行量化
设置 Python 虚拟环境并安装 LiteRT Torch 软件包的最新稳定版本:
python -m venv litert-torchsource litert-torch/bin/activatepip install "litert-torch>=0.8.0"
使用以下脚本将 Safetensor 转换为 LiteRT 模型。
from litert_torch.generative.examples.gemma3 import gemma3
from litert_torch.generative.utilities import converter
from litert_torch.generative.utilities.export_config import ExportConfig
from litert_torch.generative.layers import kv_cache
pytorch_model = gemma3.build_model_270m("PATH_TO_HF_MODEL")
# If you are using Gemma 3 1B
#pytorch_model = gemma3.build_model_1b("PATH_TO_HF_MODEL")
export_config = ExportConfig()
export_config.kvcache_layout = kv_cache.KV_LAYOUT_TRANSPOSED
export_config.mask_as_input = True
converter.convert_to_tflite(
pytorch_model,
output_path="OUTPUT_DIR_PATH",
output_name_prefix="my-gemma3",
prefill_seq_len=2048,
kv_cache_max_len=4096,
quantize="dynamic_int8",
export_config=export_config,
)
请注意,此过程非常耗时,具体取决于计算机的处理速度。作为参考,在 2025 年的 8 核 CPU 上,2.7 亿参数的模型需要 5-10 分钟以上,而 10 亿参数的模型可能需要大约 10-30 分钟。
最终输出(即 LiteRT 模型)将保存到您指定的 OUTPUT_DIR_PATH 中。
根据目标设备的内存和性能限制调整以下值。
kv_cache_max_len:定义模型工作内存(即 KV 缓存)的总分配大小。此容量是硬性限制,必须足以存储提示的词元(预填充)和所有后续生成的词元(解码)的总和。prefill_seq_len:指定用于预填充分块的输入提示的 token 数。使用预填充分块处理输入提示时,整个序列(例如50,000 个令牌)不会一次性计算;而是会分成可管理的段(例如,2,048 个令牌的块),这些段会依次加载到缓存中,以防止出现内存不足错误。quantize:所选量化方案的字符串。以下是适用于 Gemma 3 的可用量化方案列表。none:无量化fp16:FP16 权重、FP32 激活和所有运算的浮点计算dynamic_int8:FP32 激活、INT8 权重和整数计算weight_only_int8:FP32 激活、INT8 权重和浮点计算
3. 从 LiteRT 和分词器创建 TaskBundle
设置 Python 虚拟环境并安装 MediaPipe Python 软件包:
python -m venv mediapipesource mediapipe/bin/activatepip install mediapipe
使用 genai.bundler 库来捆绑模型:
from mediapipe.tasks.python.genai import bundler
config = bundler.BundleConfig(
tflite_model="PATH_TO_LITERT_MODEL.tflite",
tokenizer_model="PATH_TO_HF_MODEL/tokenizer.model",
start_token="<bos>",
stop_tokens=["<eos>", "<end_of_turn>"],
output_filename="PATH_TO_TASK_BUNDLE.task",
prompt_prefix="<start_of_turn>user\n",
prompt_suffix="<end_of_turn>\n<start_of_turn>model\n",
)
bundler.create_bundle(config)
bundler.create_bundle 函数会创建一个 .task 文件,其中包含运行模型所需的所有必要信息。
4. 在 Android 上使用 Mediapipe 进行推理
使用基本配置选项初始化任务:
// Default values for LLM models
private object LLMConstants {
const val MODEL_PATH = "PATH_TO_TASK_BUNDLE_ON_YOUR_DEVICE.task"
const val DEFAULT_MAX_TOKEN = 4096
const val DEFAULT_TOPK = 64
const val DEFAULT_TOPP = 0.95f
const val DEFAULT_TEMPERATURE = 1.0f
}
// Set the configuration options for the LLM Inference task
val taskOptions = LlmInference.LlmInferenceOptions.builder()
.setModelPath(LLMConstants.MODEL_PATH)
.setMaxTokens(LLMConstants.DEFAULT_MAX_TOKEN)
.build()
// Create an instance of the LLM Inference task
llmInference = LlmInference.createFromOptions(context, taskOptions)
llmInferenceSession =
LlmInferenceSession.createFromOptions(
llmInference,
LlmInferenceSession.LlmInferenceSessionOptions.builder()
.setTopK(LLMConstants.DEFAULT_TOPK)
.setTopP(LLMConstants.DEFAULT_TOPP)
.setTemperature(LLMConstants.DEFAULT_TEMPERATURE)
.build(),
)
使用 generateResponse() 方法生成文本回答。
val result = llmInferenceSession.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
如需流式传输回答,请使用 generateResponseAsync() 方法。
llmInferenceSession.generateResponseAsync(inputPrompt) { partialResult, done ->
logger.atInfo().log("partial result: $partialResult")
}
如需了解详情,请参阅 LLM 推理 Android 指南。
后续步骤
使用 Gemma 模型构建和探索更多内容: