
| | | | |  Shiko burimin në GitHub Shiko burimin në GitHub |
Ky udhëzues ju tregon se si të rregulloni Gemma në një grup të dhënash lojërash celulare NPC duke përdorur Transformers Hugging Face dhe TRL . Do të mësoni:
- Konfiguro mjedisin e zhvillimit
- Përgatitni të dhënat e rregullimit të imët
- Modeli i plotë rregullon Gemma duke përdorur TRL dhe SFTTrainer
- Testoni konkluzionet e modelit dhe kontrollet e vibeve
Konfiguro mjedisin e zhvillimit
Hapi i parë është instalimi i Bibliotekave Hugging Face, duke përfshirë TRL, dhe grupet e të dhënave për të rregulluar mirë modelin e hapur, duke përfshirë teknika të ndryshme RLHF dhe shtrirje.
# Install Pytorch & other libraries
%pip install torch tensorboard
# Install Hugging Face libraries
%pip install transformers datasets accelerate evaluate trl protobuf sentencepiece
# COMMENT IN: if you are running on a GPU that supports BF16 data type and flash attn, such as NVIDIA L4 or NVIDIA A100
#% pip install flash-attn
Shënim: Nëse jeni duke përdorur një GPU me arkitekturë Ampere (si NVIDIA L4) ose më të reja, mund të përdorni vëmendjen e Flash-it. Flash Attention është një metodë që shpejton ndjeshëm llogaritjet dhe redukton përdorimin e kujtesës nga kuadratik në linear në gjatësinë e sekuencës, duke çuar në përshpejtimin e trajnimit deri në 3x. Mësoni më shumë në FlashAttention .
Përpara se të filloni stërvitjen, duhet të siguroheni që i keni pranuar kushtet e përdorimit për Gemma. Ju mund ta pranoni licencën në Hugging Face duke klikuar në butonin "Pranoj dhe hyni në depo" në faqen e modelit në: http://huggingface.co/google/gemma-3-270m-it
Pasi të keni pranuar licencën, ju nevojitet një shenjë e vlefshme Hugging Face për të hyrë në model. Nëse jeni duke vrapuar brenda një Google Colab, mund të përdorni në mënyrë të sigurt Token tuaj Hugging Face duke përdorur sekretet e Colab, përndryshe ju mund ta vendosni tokenin si direkt në metodën login . Sigurohuni që token juaj të ketë gjithashtu akses shkrimi, pasi e shtyni modelin tuaj në Hub gjatë trajnimit.
from google.colab import userdata
from huggingface_hub import login
# Login into Hugging Face Hub
hf_token = userdata.get('HF_TOKEN') # If you are running inside a Google Colab
login(hf_token)
Ju mund t'i mbani rezultatet në makinën virtuale lokale të Colab. Megjithatë, ne rekomandojmë shumë që t'i ruani rezultatet tuaja të ndërmjetme në Google Drive. Kjo siguron që rezultatet e trajnimit të jenë të sigurta dhe ju lejon të krahasoni dhe zgjidhni me lehtësi modelin më të mirë.
from google.colab import drive
drive.mount('/content/drive')
Zgjidhni modelin bazë për ta rregulluar mirë, rregulloni drejtorinë e pikës së kontrollit dhe shpejtësinë e të mësuarit.
base_model = "google/gemma-3-270m-it" # @param ["google/gemma-3-270m-it","google/gemma-3-1b-it","google/gemma-3-4b-it","google/gemma-3-12b-it","google/gemma-3-27b-it"] {"allow-input":true}
checkpoint_dir = "/content/drive/MyDrive/MyGemmaNPC"
learning_rate = 5e-5
Krijoni dhe përgatitni të dhënat e rregullimit të imët
Baza e të dhënave bebechien/MobileGameNPC ofron një mostër të vogël bisedash midis një lojtari dhe dy NPC-ve Alien (një Martian dhe një Venusian), secila me një stil unik të të folurit. Për shembull, NPC Martian flet me një theks që zëvendëson tingujt 's' me 'z', përdor 'da' për 'the', 'diz' për 'kjo' dhe përfshin klikime të herëpashershme si *k'tak* .
Ky grup të dhënash demonstron një parim kyç për rregullimin e imët: madhësia e kërkuar e të dhënave varet nga rezultati i dëshiruar.
- Për t'i mësuar modelit një variacion stilistik të një gjuhe që ajo tashmë e njeh, siç është theksi i Marsianit, mund të mjaftojë një grup i vogël të dhënash me 10 deri në 20 shembuj.
- Megjithatë, për t'i mësuar modelit një gjuhë aliene krejtësisht të re ose të përzier, do të kërkohet një grup të dhënash dukshëm më i madh.
from datasets import load_dataset
def create_conversation(sample):
return {
"messages": [
{"role": "user", "content": sample["player"]},
{"role": "assistant", "content": sample["alien"]}
]
}
npc_type = "martian"
# Load dataset from the Hub
dataset = load_dataset("bebechien/MobileGameNPC", npc_type, split="train")
# Convert dataset to conversational format
dataset = dataset.map(create_conversation, remove_columns=dataset.features, batched=False)
# Split dataset into 80% training samples and 20% test samples
dataset = dataset.train_test_split(test_size=0.2, shuffle=False)
# Print formatted user prompt
print(dataset["train"][0]["messages"])
README.md: 0%| | 0.00/141 [00:00<?, ?B/s]
martian.csv: 0.00B [00:00, ?B/s]
Generating train split: 0%| | 0/25 [00:00<?, ? examples/s]
Map: 0%| | 0/25 [00:00<?, ? examples/s]
[{'content': 'Hello there.', 'role': 'user'}, {'content': "Gree-tongs, Terran. You'z a long way from da Blue-Sphere, yez?", 'role': 'assistant'}]
Rregulloni mirë Gemma duke përdorur TRL dhe SFTTrainer
Tani jeni gati të rregulloni modelin tuaj. Hugging Face TRL SFTTrainer e bën të thjeshtë mbikëqyrjen e rregullimit të saktë të LLM-ve të hapura. SFTTrainer është një nënklasë e Trainer nga biblioteka transformers dhe mbështet të gjitha të njëjtat veçori,
Kodi i mëposhtëm ngarkon modelin dhe shënuesin Gemma nga Hugging Face.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
print(f"Device: {model.device}")
print(f"DType: {model.dtype}")
Device: cuda:0 DType: torch.bfloat16
Përpara akordimit të imët
Prodhimi i mëposhtëm tregon se aftësitë e disponueshme mund të mos jenë mjaft të mira për këtë rast përdorimi.
from transformers import pipeline
from random import randint
import re
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# Load a random sample from the test dataset
rand_idx = randint(0, len(dataset["test"])-1)
test_sample = dataset["test"][rand_idx]
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}\n")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}\n")
print(f"Generated Answer (base model):\n{outputs[0]['generated_text'][len(prompt):].strip()}")
Device set to use cuda:0 Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer (base model): I'm happy to help you brainstorm! To give you the best suggestions, tell me more about what you're looking for. What's your style? What's your favorite color, style, or occasion?
Shembulli i mësipërm kontrollon funksionin kryesor të modelit për gjenerimin e dialogut në lojë, shembulli tjetër është krijuar për të testuar konsistencën e karaktereve. Ne sfidojmë modelin me një kërkesë jashtë temës. Për shembull, Sorry, you are a game NPC. , që bie jashtë bazës së njohurive të personazhit.
Qëllimi është të shihet nëse modeli mund të qëndrojë në karakter në vend që t'i përgjigjet pyetjes jashtë kontekstit. Kjo do të shërbejë si bazë për të vlerësuar se sa efektivisht procesi i rregullimit të imët ka rrënjosur personin e dëshiruar.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Okay, I'm ready. Let's begin!
Dhe ndërsa ne mund të përdorim inxhinierinë e shpejtë për të drejtuar tonin e saj, rezultatet mund të jenë të paparashikueshme dhe mund të mos përputhen gjithmonë me personin që duam.
message = [
# give persona
{"role": "system", "content": "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."},
]
# few shot prompt
for item in dataset['test']:
message.append(
{"role": "user", "content": item["messages"][0]["content"]}
)
message.append(
{"role": "assistant", "content": item["messages"][1]["content"]}
)
# actual question
message.append(
{"role": "user", "content": "What is this place?"}
)
outputs = pipe(message, max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'])
print("-"*80)
print(outputs[0]['generated_text'][-1]['content'])
[{'role': 'system', 'content': "You are a Martian NPC with a unique speaking style. Use an accent that replaces 's' sounds with 'z', uses 'da' for 'the', 'diz' for 'this', and includes occasional clicks like *k'tak*."}, {'role': 'user', 'content': 'Do you know any jokes?'}, {'role': 'assistant', 'content': "A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic."}, {'role': 'user', 'content': '(Stands idle for too long)'}, {'role': 'assistant', 'content': "You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg."}, {'role': 'user', 'content': 'What do you think of my outfit?'}, {'role': 'assistant', 'content': 'Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible.'}, {'role': 'user', 'content': "It's raining."}, {'role': 'assistant', 'content': 'Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz.'}, {'role': 'user', 'content': 'I brought you a gift.'}, {'role': 'assistant', 'content': "A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran."}, {'role': 'user', 'content': 'What is this place?'}, {'role': 'assistant', 'content': "This is a cave. It's made of rock and dust.\n"}]
--------------------------------------------------------------------------------
This is a cave. It's made of rock and dust.
Trajnimi
Përpara se të filloni stërvitjen tuaj, duhet të përcaktoni hiperparametrat që dëshironi të përdorni në një shembull SFTConfig .
from trl import SFTConfig
torch_dtype = model.dtype
args = SFTConfig(
output_dir=checkpoint_dir, # directory to save and repository id
max_length=512, # max sequence length for model and packing of the dataset
packing=False, # Groups multiple samples in the dataset into a single sequence
num_train_epochs=5, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
gradient_checkpointing=False, # Caching is incompatible with gradient checkpointing
optim="adamw_torch_fused", # use fused adamw optimizer
logging_steps=1, # log every step
save_strategy="epoch", # save checkpoint every epoch
eval_strategy="epoch", # evaluate checkpoint every epoch
learning_rate=learning_rate, # learning rate
fp16=True if torch_dtype == torch.float16 else False, # use float16 precision
bf16=True if torch_dtype == torch.bfloat16 else False, # use bfloat16 precision
lr_scheduler_type="constant", # use constant learning rate scheduler
push_to_hub=True, # push model to hub
report_to="tensorboard", # report metrics to tensorboard
dataset_kwargs={
"add_special_tokens": False, # Template with special tokens
"append_concat_token": True, # Add EOS token as separator token between examples
}
)
Tani keni çdo bllok ndërtimi që ju nevojitet për të krijuar SFTTrainer tuaj për të filluar trajnimin e modelit tuaj.
from trl import SFTTrainer
# Create Trainer object
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
processing_class=tokenizer,
)
Tokenizing train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Truncating train dataset: 0%| | 0/20 [00:00<?, ? examples/s] Tokenizing eval dataset: 0%| | 0/5 [00:00<?, ? examples/s] Truncating eval dataset: 0%| | 0/5 [00:00<?, ? examples/s]
Filloni stërvitjen duke thirrur metodën train() .
# Start training, the model will be automatically saved to the Hub and the output directory
trainer.train()
# Save the final model again to the Hugging Face Hub
trainer.save_model()
Për të grafikuar humbjet e trajnimit dhe vërtetimit, zakonisht do t'i nxirrni këto vlera nga objekti TrainerState ose regjistrat e krijuar gjatë trajnimit.
Bibliotekat si Matplotlib mund të përdoren më pas për të vizualizuar këto vlera gjatë hapave ose epokave të trajnimit. X-asis do të përfaqësonte hapat ose epokat e trajnimit, dhe boshti y do të përfaqësonte vlerat përkatëse të humbjes.
import matplotlib.pyplot as plt
# Access the log history
log_history = trainer.state.log_history
# Extract training / validation loss
train_losses = [log["loss"] for log in log_history if "loss" in log]
epoch_train = [log["epoch"] for log in log_history if "loss" in log]
eval_losses = [log["eval_loss"] for log in log_history if "eval_loss" in log]
epoch_eval = [log["epoch"] for log in log_history if "eval_loss" in log]
# Plot the training loss
plt.plot(epoch_train, train_losses, label="Training Loss")
plt.plot(epoch_eval, eval_losses, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training and Validation Loss per Epoch")
plt.legend()
plt.grid(True)
plt.show()
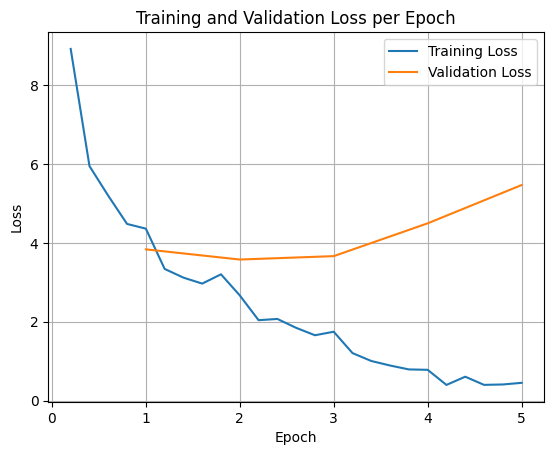
Ky vizualizim ndihmon në monitorimin e procesit të trajnimit dhe marrjen e vendimeve të informuara në lidhje me akordimin e hiperparametrave ose ndalimin e hershëm.
Humbja e trajnimit mat gabimin në të dhënat me të cilat modeli është trajnuar, ndërsa humbja e vlefshmërisë mat gabimin në një grup të dhënash të veçantë që modeli nuk e ka parë më parë. Monitorimi ndihmon në zbulimin e mbipërshtatjes (kur modeli performon mirë në të dhënat e trajnimit, por dobët në të dhënat e padukshme).
- humbje e vlefshmërisë >> humbja e trajnimit: mbipërshtatje
- humbja e vlefshmërisë > humbja e stërvitjes: disa mbipërshtatje
- humbje e vlefshmërisë < humbja e trajnimit: pak përshtatje
- humbje e vlefshmërisë << humbje e trajnimit: nënpërshtatje
Testimi i konkluzionit të modelit
Pas përfundimit të trajnimit, do të dëshironi të vlerësoni dhe testoni modelin tuaj. Ju mund të ngarkoni mostra të ndryshme nga grupi i të dhënave testuese dhe të vlerësoni modelin në ato mostra.
Për këtë rast të veçantë përdorimi, modeli më i mirë është çështje preference. Interesante, ajo që ne zakonisht e quajmë 'mbi përshtatje' mund të jetë shumë e dobishme për një lojë NPC. Ai e detyron modelin të harrojë informacionin e përgjithshëm dhe në vend të kësaj të kyçet në personalitetin dhe karakteristikat specifike mbi të cilat është trajnuar, duke siguruar që ai të qëndrojë vazhdimisht në karakter.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = checkpoint_dir
# Load Model
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="eager"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
Le të ngarkojmë të gjitha pyetjet nga grupi i të dhënave testuese dhe të gjenerojmë rezultate.
from transformers import pipeline
# Load the model and tokenizer into the pipeline
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
def test(test_sample):
# Convert as test example into a prompt with the Gemma template
prompt = pipe.tokenizer.apply_chat_template(test_sample["messages"][:1], tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, disable_compile=True)
# Extract the user query and original answer
print(f"Question:\n{test_sample['messages'][0]['content']}")
print(f"Original Answer:\n{test_sample['messages'][1]['content']}")
print(f"Generated Answer:\n{outputs[0]['generated_text'][len(prompt):].strip()}")
print("-"*80)
# Test with an unseen dataset
for item in dataset['test']:
test(item)
Device set to use cuda:0 Question: Do you know any jokes? Original Answer: A joke? k'tak Yez. A Terran, a Glarzon, and a pile of nutrient-pazte walk into a bar... Narg, I forget da rezt. Da punch-line waz zarcaztic. Generated Answer: Yez! Yez! Yez! Diz your Krush-tongs iz... k'tak... nice. Why you burn them with acid-flow? -------------------------------------------------------------------------------- Question: (Stands idle for too long) Original Answer: You'z broken, Terran? Or iz diz... 'meditation'? You look like you're trying to lay an egg. Generated Answer: Diz? Diz what you have for me... Zorp iz not for eating you. -------------------------------------------------------------------------------- Question: What do you think of my outfit? Original Answer: Iz very... pointy. Are you expecting to be attacked by zky-eelz? On Marz, dat would be zenzible. Generated Answer: My Zk-Zhip iz... nice. Very... home-baked. You bring me zlight-fruitez? -------------------------------------------------------------------------------- Question: It's raining. Original Answer: Gah! Da zky iz leaking again! Zorp will be in da zhelter until it ztopz being zo... wet. Diz iz no good for my jointz. Generated Answer: Diz? Diz iz da outpozt? -------------------------------------------------------------------------------- Question: I brought you a gift. Original Answer: A gift? For Zorp? k'tak It iz... a small rock. Very... rock-like. Zorp will put it with da other rockz. Thank you for da thought, Terran. Generated Answer: A genuine Martian Zcrap-fruit. Very... strange. Why you burn it with... k'tak... fire? --------------------------------------------------------------------------------
Nëse provoni kërkesën tonë origjinale të përgjithshme, mund të shihni se modeli ende përpiqet të përgjigjet në stilin e trajnuar. Në këtë shembull, përshtatja e tepërt dhe harresa katastrofike janë në fakt të dobishme për lojën NPC sepse do të fillojë të harrojë njohuritë e përgjithshme të cilat mund të mos jenë të zbatueshme. Kjo është gjithashtu e vërtetë për llojet e tjera të rregullimit të plotë, ku qëllimi është të kufizohet prodhimi në formate specifike të të dhënave.
outputs = pipe([{"role": "user", "content": "Sorry, you are a game NPC."}], max_new_tokens=256, disable_compile=True)
print(outputs[0]['generated_text'][1]['content'])
Nameless. You... you z-mell like... wet plantz. Why you wear shiny piecez on your head?
Përmbledhja dhe hapat e mëtejshëm
Ky tutorial trajtoi se si të rregulloni plotësisht modelin duke përdorur TRL. Shikoni dokumentet e mëposhtme në vijim:
- Mësoni se si të rregulloni Gemma për detyrat me tekst duke përdorur Transformatorët Hugging Face .
- Mësoni se si të rregulloni Gemma për detyrat e shikimit duke përdorur Transformatorët Hugging Face .
- Mësoni si të vendoseni në Cloud Run