
Um DiffusionGemma zu verstehen, ist es hilfreich, sich die grundlegenden Einschränkungen von Standard-Sprachmodellen anzusehen und zu verstehen, wie sich die textbasierte Diffusion unterscheidet.
Das Problem mit autoregressiven Modellen
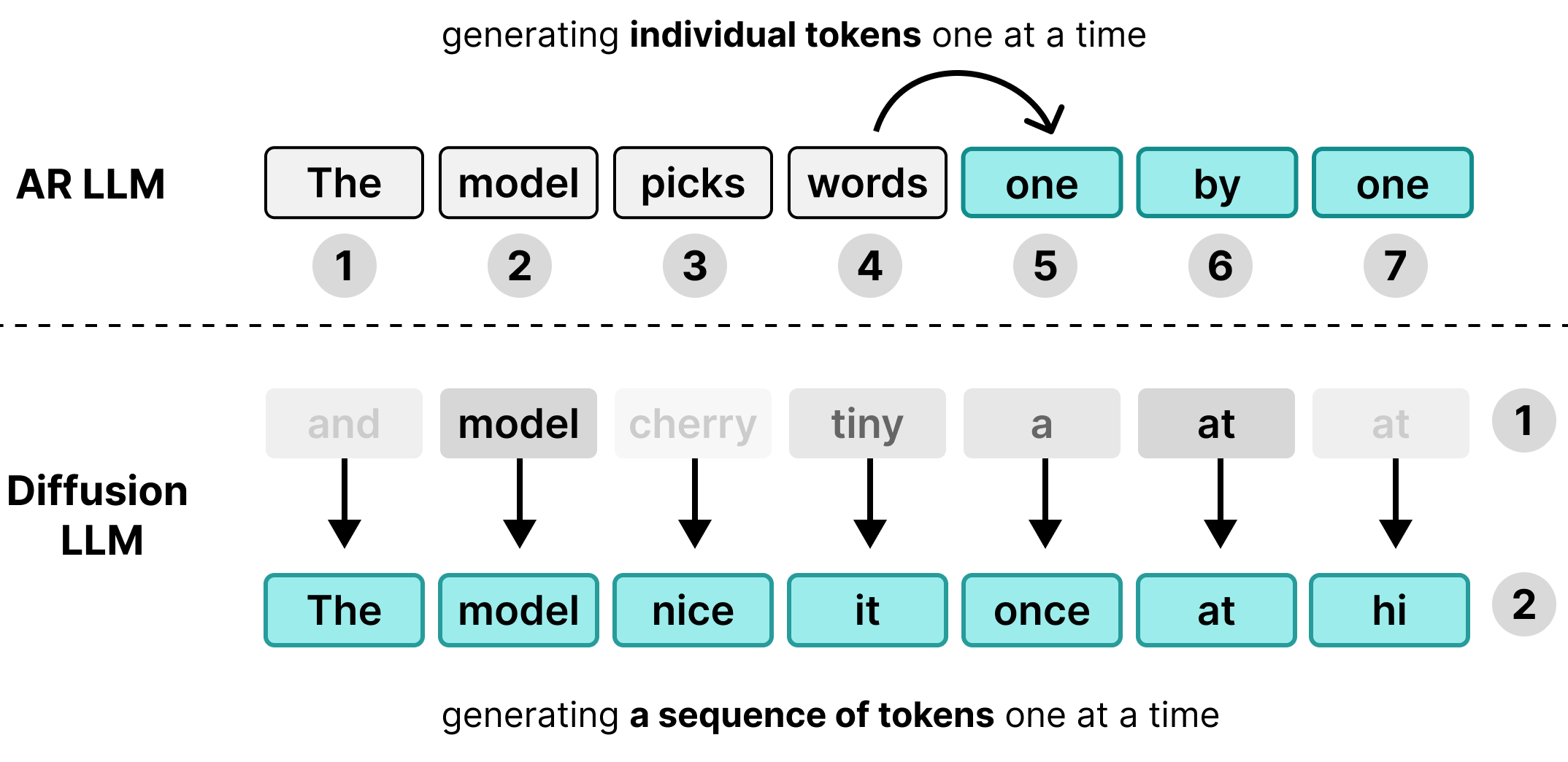
Viele Large Language Models (LLMs) sind autoregressiv. Das bedeutet, dass sie Text jeweils nur mit einem Token generieren. Dieser Ansatz eignet sich zwar gut, um viele Nutzer gleichzeitig über Batching zu bedienen, führt aber zu einem Latenzengpass für einzelne Nutzer.
Während der Decodierungsphase sind Standard-Transformer-Modelle eher speichergebunden als rechengebunden. Die meiste Zeit wird für das Laden von Modellgewichten aus dem Hardwarespeicher in die Verarbeitungseinheiten aufgewendet, anstatt für die eigentlichen mathematischen Berechnungen. Da die Gewichte unabhängig von der Batchgröße nur einmal pro Schritt geladen werden müssen, dauert das Generieren eines Tokens für einen Nutzer fast genauso lange wie für 256 Nutzer, die zusammen gruppiert sind.
Folglich hat ein einzelner Nutzer keinen Latenzvorteil. Die Rechenkapazität der Hardware bleibt im Leerlauf, während auf Speichertransfers gewartet wird.
DiffusionGemma nutzt diese inaktive Rechenzeit für den einzelnen Nutzer. Anstatt 1 Token für 256 separate Nutzer zu generieren, werden 256 Tokens gleichzeitig für einen einzelnen Nutzer generiert.
Das Modell initialisiert eine leere Sequenz von 256 zufälligen Tokens – auch Canvas genannt – und wertet und optimiert den gesamten Canvas iterativ gleichzeitig. Dadurch wird das Modell von speichergebunden zu rechengebunden, sodass die Verarbeitungsgeschwindigkeit mit zunehmender Rechenleistung effizient skaliert werden kann.
| Aspekt | Autoregression von Text | Text Diffusion |
|---|---|---|
| Token-Generierung | Jeweils ein Token | Ein vollständiger Canvas mit Tokens auf einmal |
| Schritte | Ein Schritt für jedes Token | Ein Schritt für mehrere Tokens |
| Generierungsreihenfolge | Rechtsläufig | Alle Positionen parallel |
| Startpunkt | Leere Sequenz | Zufällige Tokens aus dem Vokabular |
| Fehlerkorrektur | Statisch; vergangene Tokens können nicht überarbeitet werden | Dynamisch; jede Canvas-Position kann überarbeitet werden |
| Hardware-Engpass | Arbeitsspeichergebunden | Compute-gebunden |
| Fokus auf Durchsatz | Hoher Durchsatz bei mehreren Nutzern | Extrem niedrige Latenz für einzelne Nutzer |
Funktionsweise der Textdiffusion
Bei der Bildgenerierung beginnen Diffusionsmodelle mit 100% zufälligem Gaußschen Rauschen und entfernen es schrittweise (Entrauschung) in mehreren Schritten, die durch einen Text-Prompt gesteuert werden. Die Übersetzung dieser Logik in Text ist schwieriger, da Text-Tokens im Gegensatz zu kontinuierlichen Pixelwerten diskrete Einheiten sind.
DiffusionGemma erreicht textbasierte Diffusion durch eine Reihe von spezialisierten Methoden:
1. Masked Diffusion
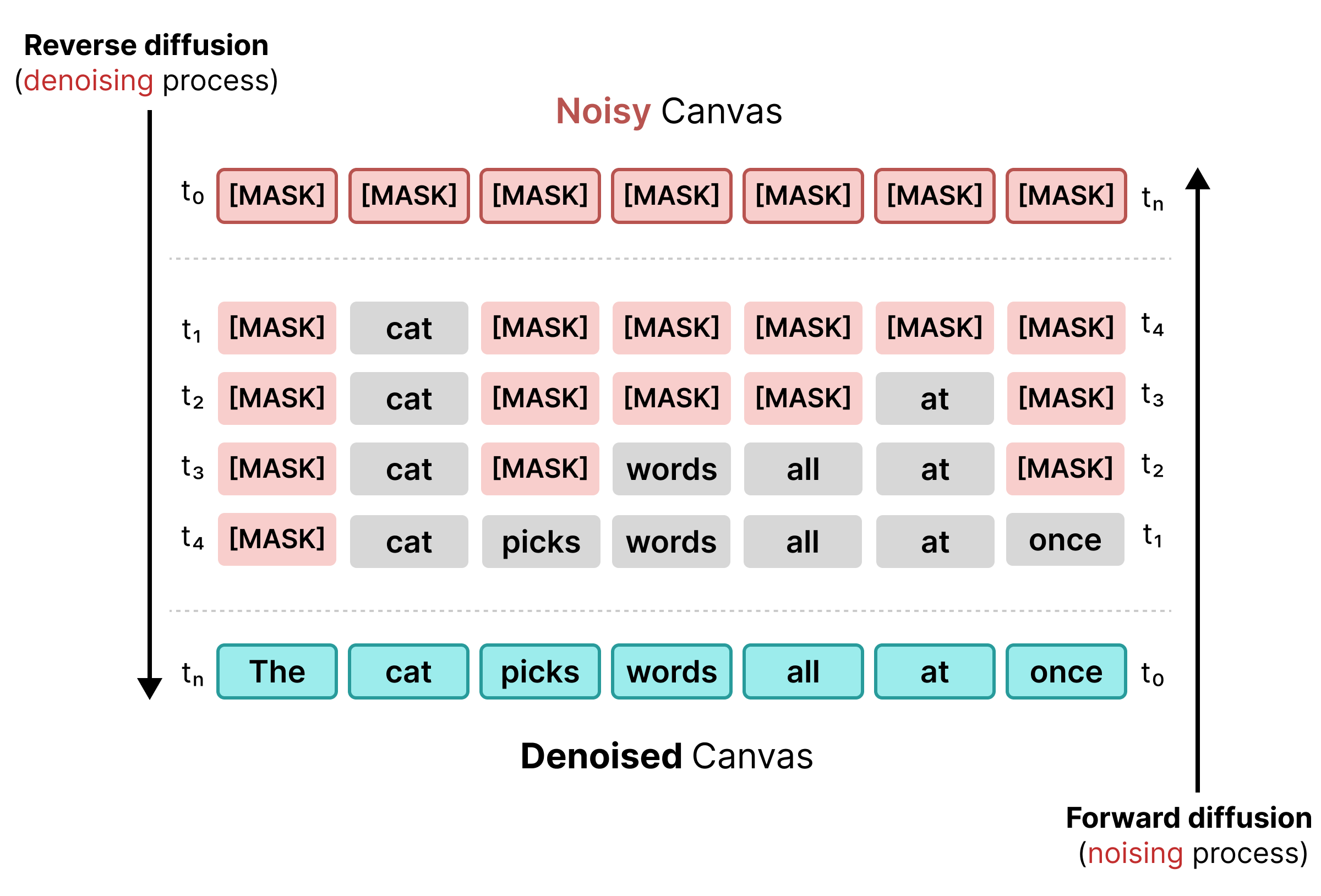
Bei der frühen Textdiffusion wurde auf Maskierung gesetzt, ähnlich wie beim BERT-Training. Zufällige Tokens in einer Sequenz werden durch ein [MASK]-Token (das Rauschen darstellt) ersetzt. Bei der Rückwärtsdiffusion sagt das Modell das richtige Token hinter der Maske voraus und ersetzt Tokens, wenn die Konfidenz einen bestimmten Schwellenwert erreicht.
Die maskierte Diffusion hat jedoch den Nachteil, dass sie starr ist: Sobald ein [MASK]-Token durch ein Wort ersetzt wird, ist es festgelegt. Sie kann in späteren Schritten nicht korrigiert werden, wenn sich der umgebende Kontext ändert.
2. Uniform State Diffusion
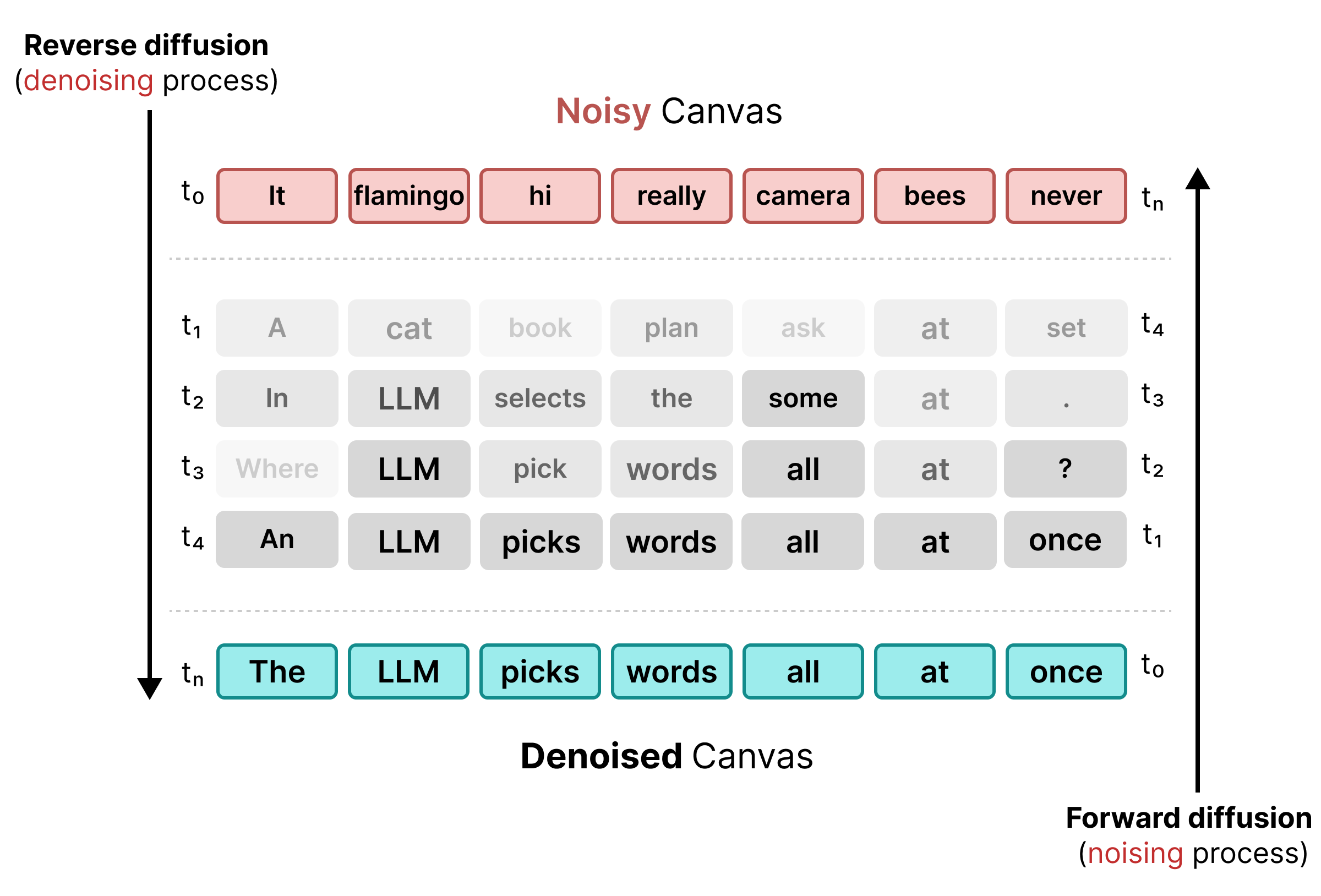
Um die Einschränkungen der Maskierung zu beheben, verwendet DiffusionGemma Uniform State Diffusion. Anstelle eines expliziten [MASK]-Tokens wird Rauschen eingeführt, indem Originalwörter durch völlig zufällige Tokens aus dem Vokabular ersetzt werden.
Beim Entrauschen analysiert das Modell den gesamten Canvas, um zu ermitteln, welche Tokens Kontextrauschen sind, und aktualisiert sie. Wenn ein Token korrekt ist, behält es eine hohe Wahrscheinlichkeit. Wenn die Wahrscheinlichkeit eines Tokens aufgrund von neuem Kontext, der in späteren Schritten entsteht, unter einen Schwellenwert sinkt, wird es mit einem neuen zufälligen Token erneut entrauscht. Dieser Zyklus ermöglicht eine kontinuierliche Fehlerkorrektur und parallele Canvas-Optimierung.
Architektur: Inkrementelles Vervollständigen und Entrauschen
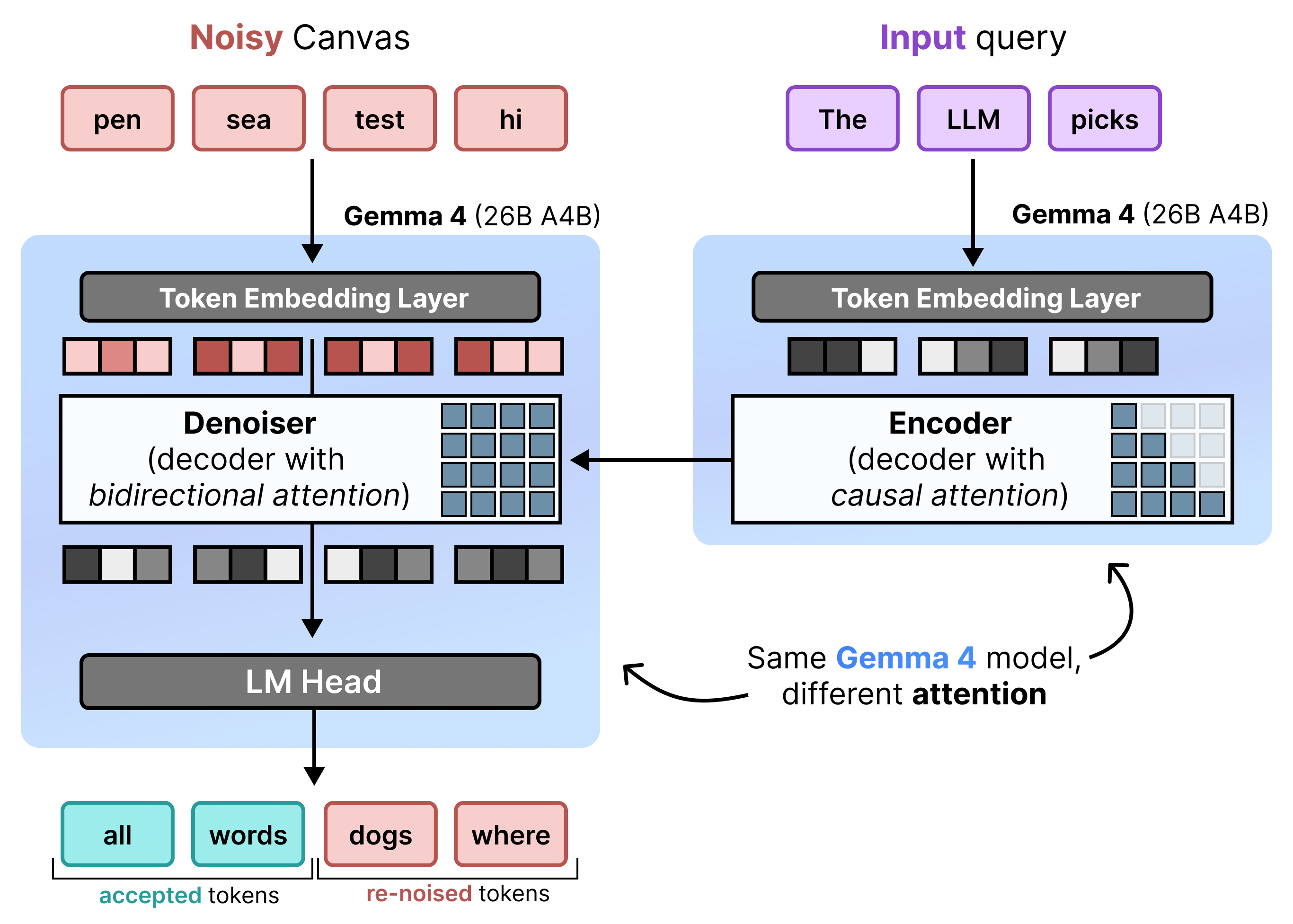
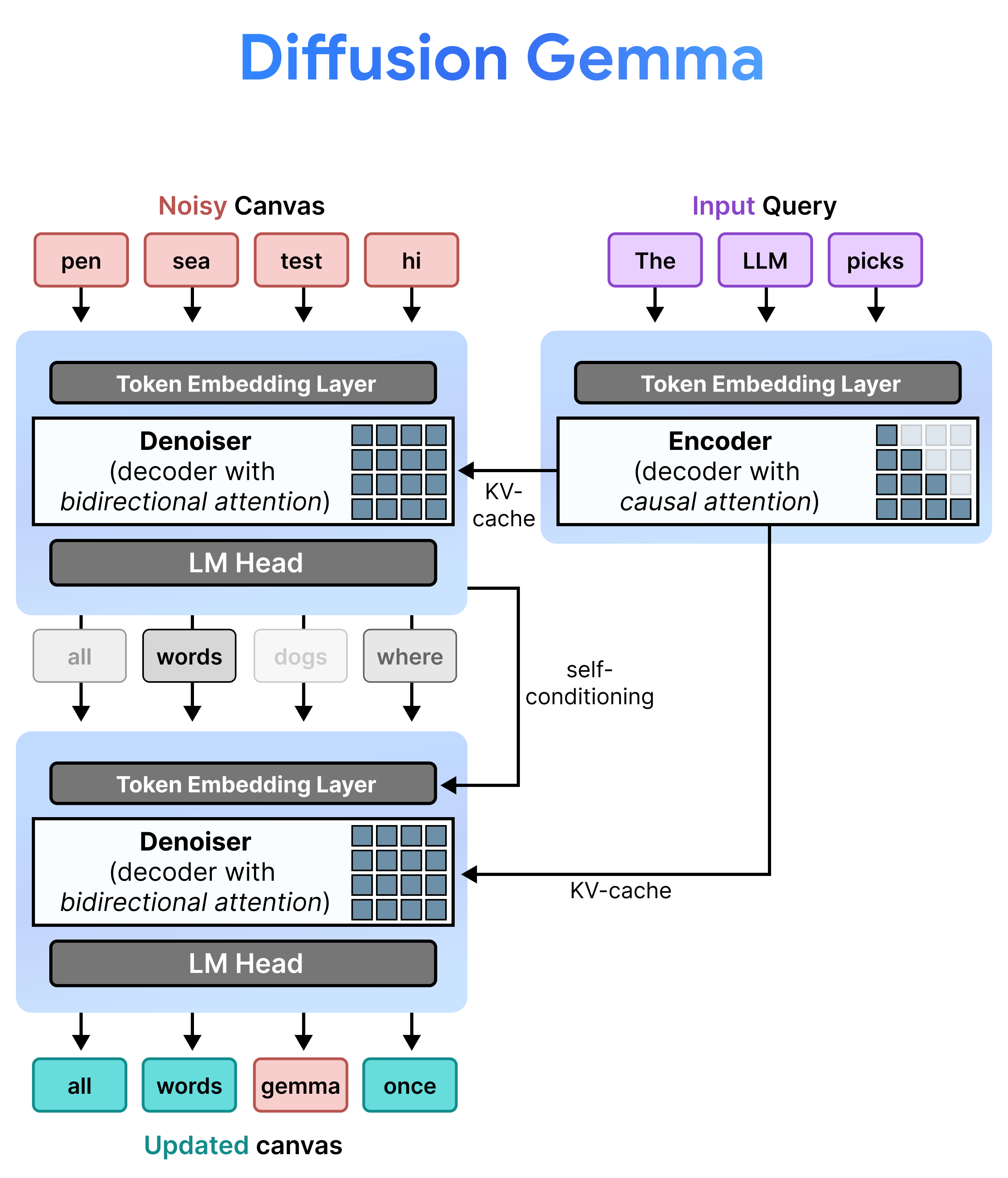
DiffusionGemma implementiert Uniform State Diffusion effizient, indem es zwischen Incremental Prefill und Denoising wechselt. Das Gemma 4 26B A4B-Modell wird nicht nativ verwendet, sondern für die verschiedenen Aufgaben der Rauschunterdrückung und Codierung optimiert. Anstatt separate Modelle zu verwenden, wird mit einem einzelnen Backbone dynamisch zwischen zwei Modi gewechselt:
- Prefill / Incremental Prefill (kausal): Hier wird die kausale Aufmerksamkeit verwendet, um den Prompt-Kontext aufzunehmen und in den KV-Cache zu schreiben. Dieser Vorgang wird einmal ausgeführt, um den ursprünglichen Kontext vorab auszufüllen, und dann einmal pro Block, um jeden fertiggestellten 256-Token-Canvas an den KV-Cache anzuhängen, bevor der nächste Canvas entrauscht wird.
- Entrauschen (bidirektional): Hier wird bidirektionale Aufmerksamkeit verwendet, um die Leinwand iterativ zu entrauschen. Abfrage-Tokens an einer beliebigen Position auf dem Canvas können auf alle anderen Canvas-Tokens (sowie den KV-Cache) zugreifen, sodass das Modell den Kontext bidirektional verarbeiten kann.
Erweiterte Inferenz-Frameworks
Um einen Canvas von reinem Rauschen in einen fertigen Text zu verwandeln, verwendet DiffusionGemma eine Reihe zugrunde liegender Decodierungssysteme:
Selbstkonditionierung
Während der Inferenz behält der Decoder (auch als Denoiser bezeichnet) seinen vorherigen Zustand bei. Nach Abschluss eines Denoising-Schritts multipliziert er seine generierte Wahrscheinlichkeitsverteilungsmatrix mit der Token-Einbettungstabelle. Dadurch wird eine lokalisierte Vektordarstellung erzeugt, die eine Erinnerung an die vorherigen Vorhersagen und Vertrauensmetriken enthält und direkt an den nächsten Schritt übergeben wird.
Multi-Canvas-Sampling (Block Diffusion)
Da ein einzelner Canvas auf 256 Tokens begrenzt ist, werden bei DiffusionGemma Diffusion und Autoregression für Langformtext verkettet. Es werden Diffusionszyklen ausgeführt, um einen vollständigen Block mit 256 Tokens zu generieren. Dieser Block wird an den Prompt-Kontext angehängt, der KV-Cache des Encoders wird aktualisiert und ein neuer Diffusionszyklus für 256 Tokens wird gestartet.
Zusammenfassung
Standardmäßige autoregressive Sprachmodelle generieren Text sequenziell (jeweils ein Token), was sie speichergebunden macht und einen Latenzengeschwindigkeitsengpass für einzelne Nutzer verursacht. DiffusionGemma löst dieses Problem, indem es auf ein rechengebundenes Modell umgestellt wird, das gleichzeitig einen vollständigen 256-Token-„Canvas“ generiert.
Durch die Verwendung von Uniform State Diffusion ersetzt das Modell Text durch zufälliges Vokabularrauschen und verfeinert das gesamte Canvas iterativ parallel. Es verwendet ein optimiertes Gemma 4 26B A4B, um die verschiedenen Aufgaben der Rauschunterdrückung und Codierung zu unterstützen. Fortschrittliche Frameworks wie Self-Conditioning und Multi-Canvas-Block-Sampling ermöglichen es dem Modell, Fehler dynamisch zu korrigieren, lange Texte zu generieren und eine extrem niedrige Latenz für einzelne Nutzer zu erreichen.