
Pour comprendre DiffusionGemma, il est utile d'examiner les principales limites des modèles de langage standards et la façon dont la diffusion basée sur le texte diffère.
Problème lié aux modèles autorégressifs
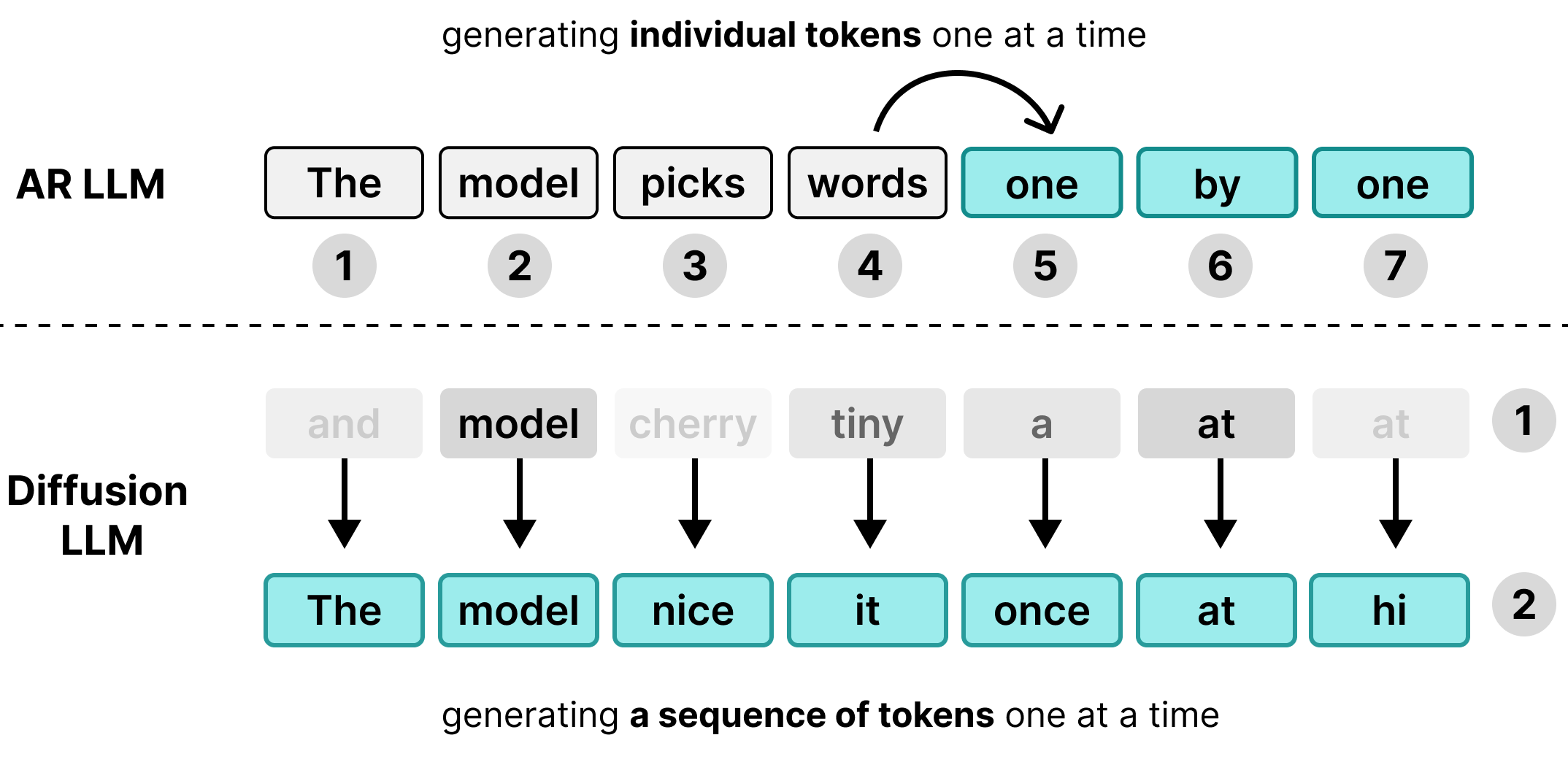
De nombreux grands modèles de langage (LLM) sont autorégressifs, ce qui signifie qu'ils génèrent du texte un jeton à la fois. Bien que cette approche fonctionne bien pour diffuser des données à de nombreux utilisateurs simultanément via le traitement par lot, elle crée un goulot d'étranglement de latence pour les utilisateurs individuels.
Lors de la phase de décodage, les modèles Transformer standards sont limités par la mémoire plutôt que par le calcul. La majeure partie du temps de génération est consacrée au chargement des pondérations du modèle depuis la mémoire matérielle vers les unités de traitement, plutôt qu'à l'exécution des calculs mathématiques proprement dits. Étant donné que les pondérations n'ont besoin d'être chargées qu'une seule fois par pas, quelle que soit la taille de lot, la génération d'un jeton prend presque le même temps pour un utilisateur que pour 256 utilisateurs regroupés.
Par conséquent, un utilisateur individuel ne bénéficie d'aucun avantage en termes de latence. La capacité de calcul du matériel reste inactive en attendant les transferts de mémoire.
DiffusionGemma utilise ce temps de calcul inactif pour l'utilisateur individuel. Au lieu de générer un jeton pour 256 utilisateurs distincts, il génère 256 jetons à la fois pour un seul utilisateur.
Le modèle initialise une séquence vide de 256 jetons aléatoires (appelée canevas), puis évalue et affine l'ensemble du canevas de manière itérative et simultanée. Le modèle passe ainsi d'une limite de mémoire à une limite de calcul, ce qui lui permet d'adapter efficacement la vitesse de traitement à l'augmentation de la puissance de calcul.
| Aspect | Autorégression de texte | Diffusion de texte |
|---|---|---|
| Génération de jetons | Un jeton à la fois | Un canevas complet de jetons à la fois |
| Étapes | Une étape pour chaque jeton | Une étape pour plusieurs jetons |
| Ordre de génération | De gauche à droite | Toutes les positions en parallèle |
| Point de départ | Séquence vide | Jetons aléatoires échantillonnés à partir du vocabulaire |
| Correction des erreurs | Statique : impossible de réviser les jetons passés | Dynamique : vous pouvez modifier la position de n'importe quel canevas. |
| Goulot d'étranglement matériel | Lié à la mémoire | Lié au calcul |
| Priorité au débit | Débit élevé pour plusieurs utilisateurs | Latence ultrafaible pour un seul utilisateur |
Comprendre les mécanismes de la diffusion de texte
Dans la génération d'images, les modèles de diffusion commencent par un bruit gaussien aléatoire à 100% et le suppriment progressivement (débruitage) en plusieurs étapes guidées par une requête textuelle. Traduire cette logique en texte est plus difficile, car les jetons de texte sont des entités discrètes, contrairement aux valeurs de pixels continues.
DiffusionGemma réalise la diffusion basée sur le texte grâce à une progression de méthodologies spécialisées :
1. Diffusion masquée
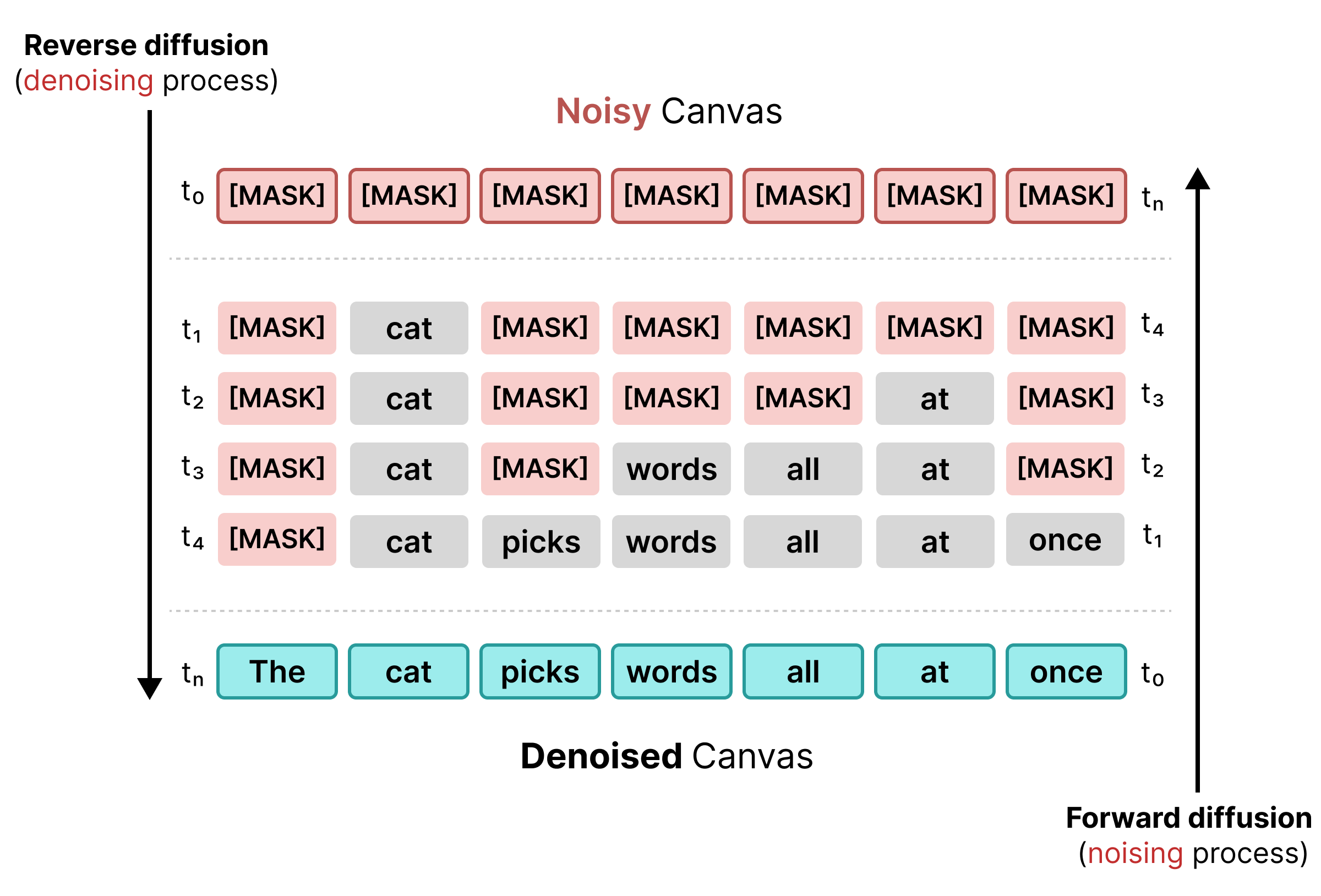
La première diffusion de texte reposait sur le masquage, comme l'entraînement BERT. Les jetons aléatoires d'une séquence sont remplacés par un jeton [MASK] (représentant le bruit). Lors de la diffusion inverse, le modèle prédit le jeton correct derrière le masque et le substitue aux jetons dont le niveau de confiance atteint un seuil spécifique.
Toutefois, la diffusion masquée souffre de rigidité : une fois qu'un jeton [MASK] est remplacé par un mot, il est verrouillé et ne peut plus être corrigé lors des étapes ultérieures si le contexte environnant change.
2. Uniform State Diffusion
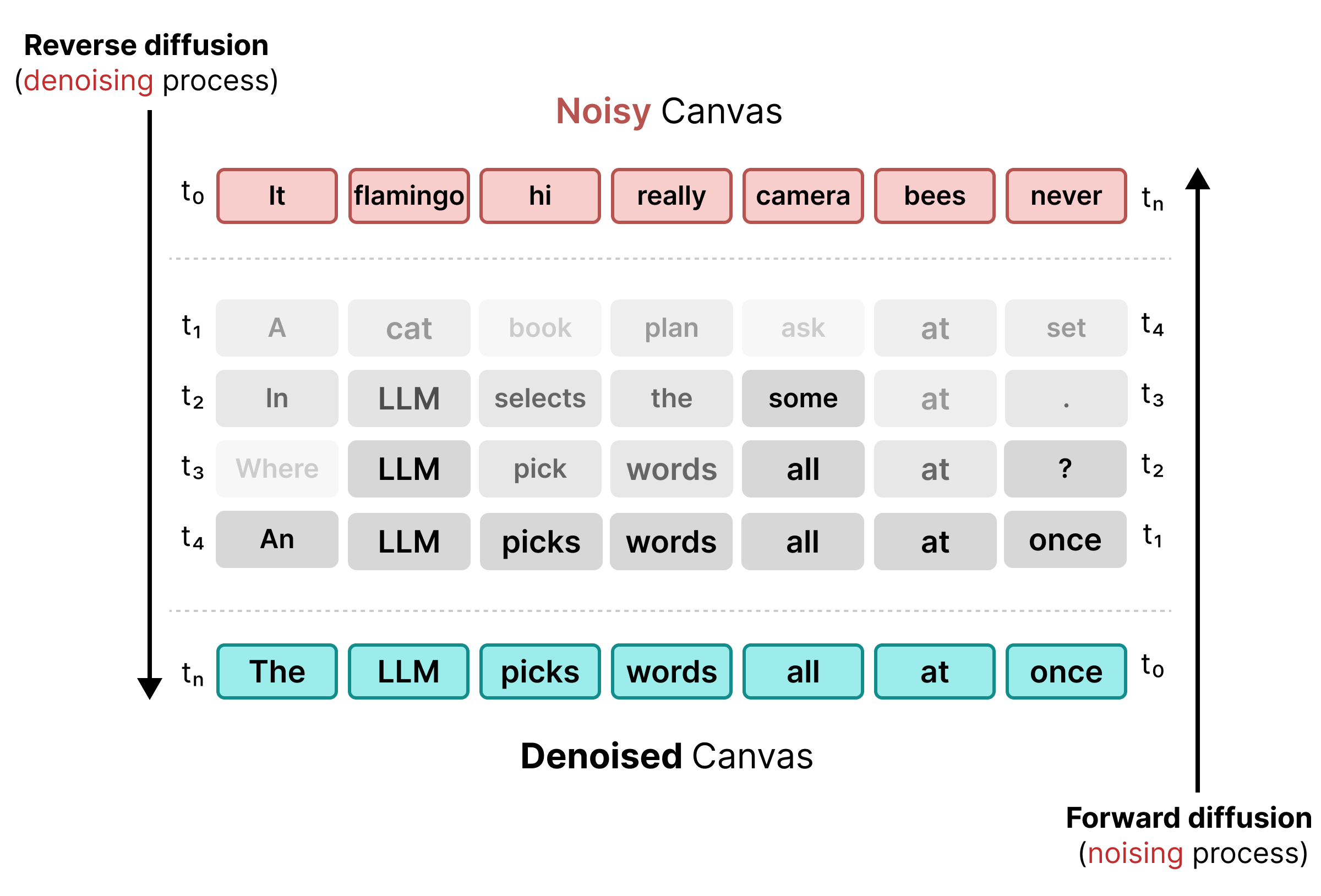
Pour résoudre les limites du masquage, DiffusionGemma utilise la diffusion d'état uniforme. Au lieu d'un jeton [MASK] explicite, le bruit est introduit en remplaçant les mots d'origine par des jetons aléatoires du vocabulaire.
Pendant le processus de débruitage, le modèle analyse l'ensemble du canevas pour déterminer quels jetons sont du bruit contextuel et les met à jour. Si un jeton est correct, il conserve une probabilité élevée. Si la probabilité d'un jeton tombe en dessous d'un seuil en raison d'un nouveau contexte apparaissant lors des étapes ultérieures, il est re-bruité avec un nouveau jeton aléatoire. Ce cycle permet une correction continue des erreurs et un affinement parallèle du canevas.
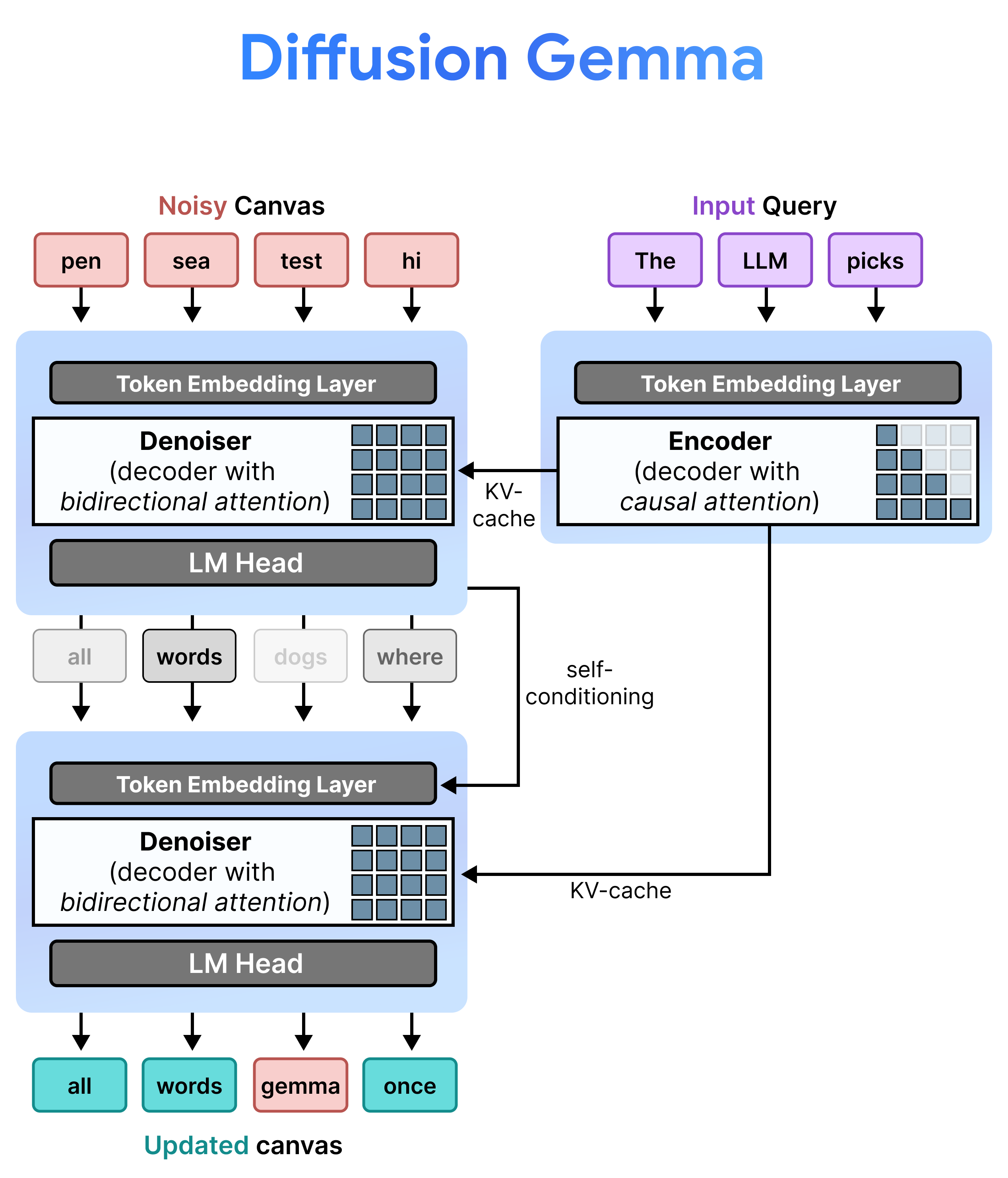
Architecture : préremplissage et débruitage incrémentaux
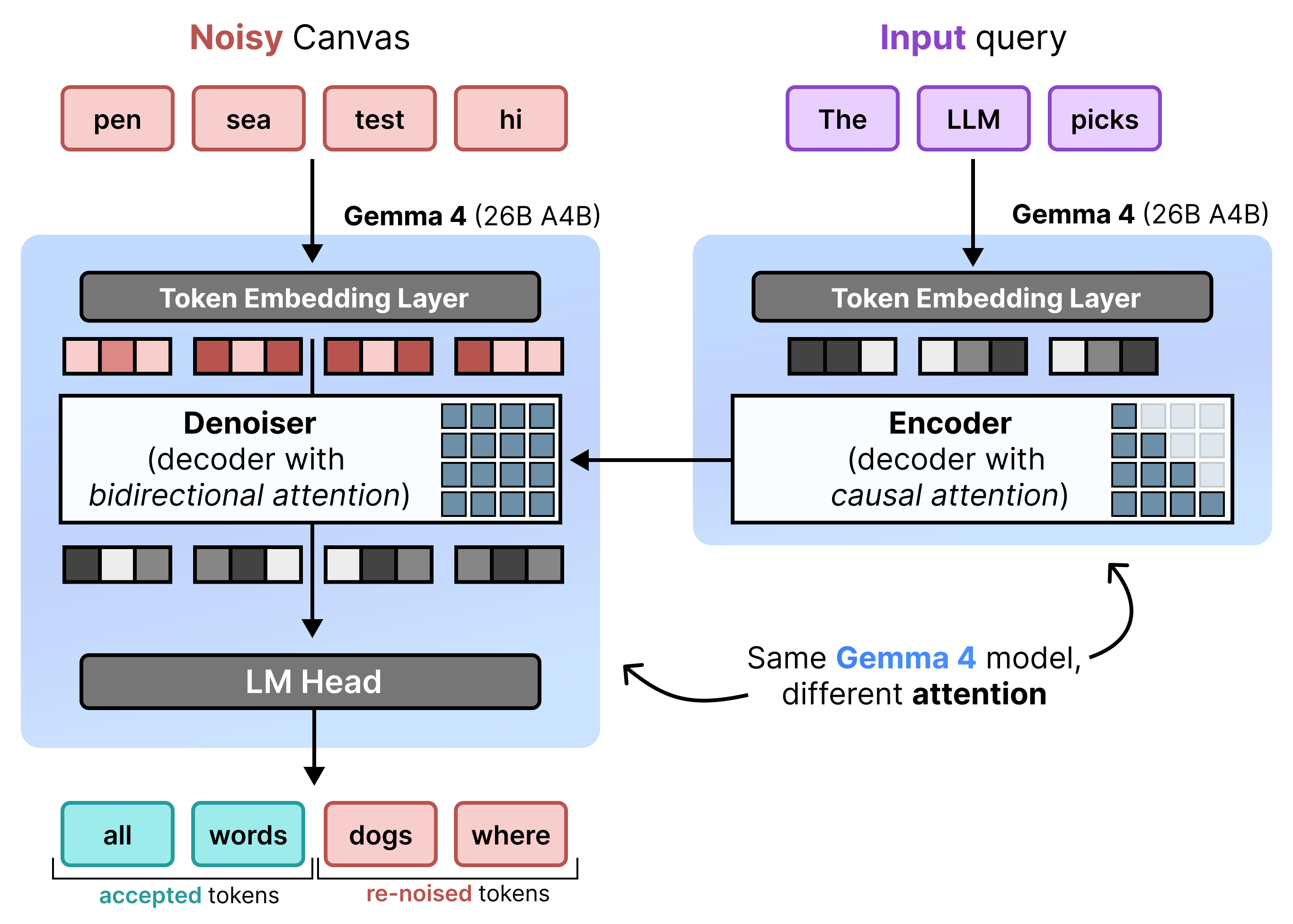
DiffusionGemma implémente la diffusion d'état uniforme de manière efficace en alternant entre le préremplissage incrémentiel et le débruitage. Le modèle Gemma 4 26B A4B n'est pas utilisé de manière native, mais il est affiné pour prendre en charge les différentes tâches de débruitage et d'encodage. Au lieu d'utiliser des modèles distincts, un seul backbone bascule dynamiquement entre deux modes :
- Préremplissage / Préremplissage incrémentiel (causal) : utilise l'attention causale pour ingérer le contexte de la requête et écrire dans le cache KV. Il s'exécute une fois pour préremplir le contexte initial, puis une fois par bloc pour ajouter chaque canevas finalisé de 256 jetons au cache KV avant de passer au débruitage du canevas suivant.
- Débruitage (bidirectionnel) : utilise l'attention bidirectionnelle pour débruiter le canevas de manière itérative. Les jetons de requête à n'importe quelle position du canevas peuvent s'occuper de tous les autres jetons du canevas (ainsi que du cache KV), ce qui permet au modèle de traiter le contexte de manière bidirectionnelle.
Frameworks d'inférence avancés
Pour passer d'un canevas de bruit pur à un texte finalisé, DiffusionGemma utilise une collection de systèmes de décodage sous-jacents :
Auto-conditionnement
Lors de l'inférence, le décodeur (également appelé "débruiteur") conserve son état précédent. Après avoir terminé une étape de débruitage, il multiplie sa matrice de distribution de probabilité générée par le tableau d'intégration de jetons. Cela génère une représentation vectorielle localisée qui conserve en mémoire ses prédictions précédentes et ses métriques de confiance, et qui est transmise directement à l'étape suivante.
Échantillonnage multiconteneur (diffusion par blocs)
Étant donné qu'un seul canevas est limité à 256 jetons, DiffusionGemma enchaîne la diffusion et l'autorégression pour les textes longs. Il exécute des cycles de diffusion pour générer un bloc complet de 256 jetons, ajoute ce bloc terminé au contexte de l'invite, met à jour le cache KV de l'encodeur et lance un tout nouveau cycle de diffusion de canevas de 256 jetons.
Résumé
Les modèles de langage autorégressifs standards génèrent du texte de manière séquentielle (un jeton à la fois), ce qui les rend liés à la mémoire et crée un goulot d'étranglement de latence pour les utilisateurs individuels. DiffusionGemma résout ce problème en passant à un modèle lié au calcul qui génère simultanément un "canevas" complet de 256 jetons.
En utilisant la diffusion d'état uniforme, le modèle remplace le texte par du bruit de vocabulaire aléatoire et affine de manière itérative l'ensemble du canevas en parallèle. Il utilise un modèle Gemma 4 26B A4B affiné pour prendre en charge les différentes tâches de débruitage et d'encodage. Les frameworks avancés tels que l'auto-conditionnement et l'échantillonnage de blocs multiconteneurs permettent au modèle de corriger dynamiquement les erreurs, de gérer la génération de contenu long et d'atteindre une latence ultra-faible pour un seul utilisateur.