
כדי להבין את DiffusionGemma, כדאי לבחון את המגבלות העיקריות של מודלים סטנדרטיים של שפה ואת ההבדלים בין מודלים כאלה לבין מודלים של דיפוזיה מבוססת-טקסט.
הבעיה במודלים אוטו-רגרסיביים
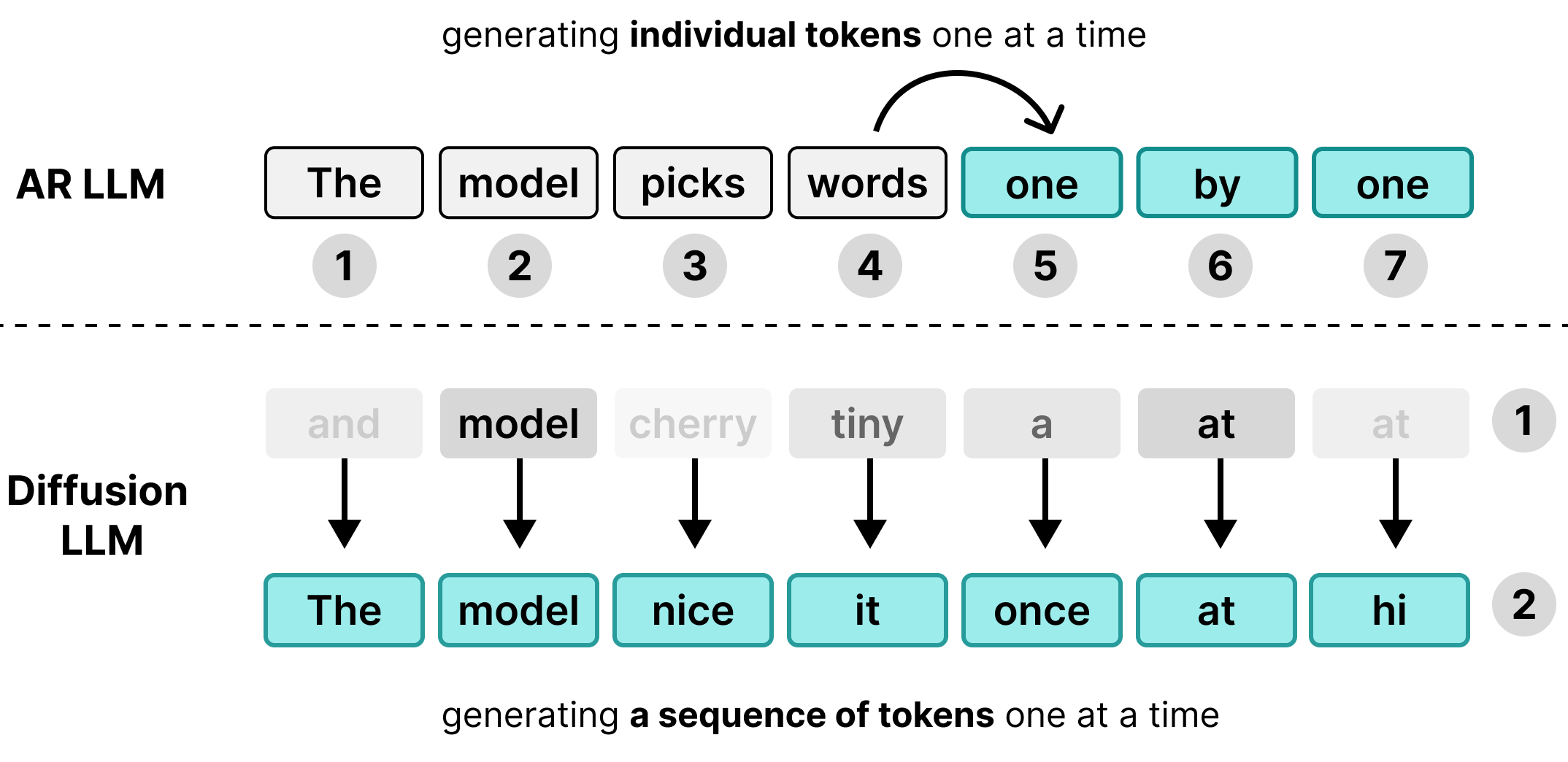
הרבה מודלים גדולים של שפה (LLM) הם אוטו-רגרסיביים, כלומר הם יוצרים טקסט באמצעות טוקן אחד בכל פעם. הגישה הזו מתאימה להצגת מודעות להרבה משתמשים בו-זמנית באמצעות אצווה, אבל היא יוצרת צוואר בקבוק של זמן אחזור למשתמשים בודדים.
במהלך שלב הפענוח, מודלים רגילים של טרנספורמר הם מוגבלים על ידי הזיכרון ולא על ידי יכולת החישוב. רוב הזמן של יצירת התוכן מושקע בטעינת משקלי המודל מזיכרון החומרה ליחידות העיבוד, ולא בביצוע החישובים המתמטיים בפועל. הסיבה לכך היא שהמשקלים נטענים רק פעם אחת בכל שלב, ללא קשר לגודל האצווה. לכן, יצירת טוקן אורכת כמעט אותו פרק זמן עבור משתמש אחד ועבור 256 משתמשים שמקובצים יחד.
לכן, משתמשים פרטיים לא נהנים מיתרון של זמן אחזור נמוך. יכולת החישוב של החומרה לא מנוצלת בזמן ההמתנה להעברות זיכרון.
DiffusionGemma משתמשת בזמן החישוב הפנוי הזה עבור המשתמש הספציפי. במקום ליצור טוקן אחד ל-256 משתמשים נפרדים, המערכת יוצרת 256 טוקנים בבת אחת למשתמש יחיד.
המודל מאתחל רצף ריק של 256 טוקנים אקראיים – שנקרא בד ציור – ומעריך ומשפר את כל בד הציור בו-זמנית. כך המודל הופך ממוגבל על ידי הזיכרון למוגבל על ידי המחשוב, מה שמאפשר לו להגדיל את מהירויות העיבוד ביעילות ככל שהעוצמה החישובית גדלה.
| יחס | Text Autoregression | Text Diffusion |
|---|---|---|
| יצירת טוקנים | טוקן אחד בכל פעם | לוח עריכה מלא של אסימונים בבת אחת |
| שלבים | שלב אחד לכל אסימון | שלב אחד לכמה אסימונים |
| סדר היצירה | משמאל לימין | כל המיקומים במקביל |
| נקודת ההתחלה | רצף ריק | אסימונים אקראיים שנדגמו מהאוצר המילים |
| תיקון שגיאות | סטטי; אי אפשר לשנות טוקנים קודמים | דינמי; אפשר לשנות את המיקום של כל רכיב בלוח |
| צוואר בקבוק בחומרה | מוגבל על ידי הזיכרון | מוגבלת על ידי המחשוב |
| התמקדות בנפח הנתונים | תפוקה גבוהה של משתמשים מרובים | זמן אחזור נמוך במיוחד למשתמש יחיד |
הסבר על המנגנונים של דיפוזיה של טקסט
בתהליך יצירת תמונות, מודלים של דיפוזיה מתחילים עם רעש גאוסי אקראי בשיעור של 100% ומסירים אותו בהדרגה (הסרת רעשים) בכמה שלבים בהנחיית הנחיה טקסטואלית. תרגום הלוגיקה הזו לטקסט הוא מאתגר יותר, כי טוקנים של טקסט הם ישויות נפרדות, בניגוד לערכי פיקסלים רציפים.
DiffusionGemma משיג דיפוזיה מבוססת-טקסט באמצעות התקדמות של מתודולוגיות מיוחדות:
1. Masked Diffusion
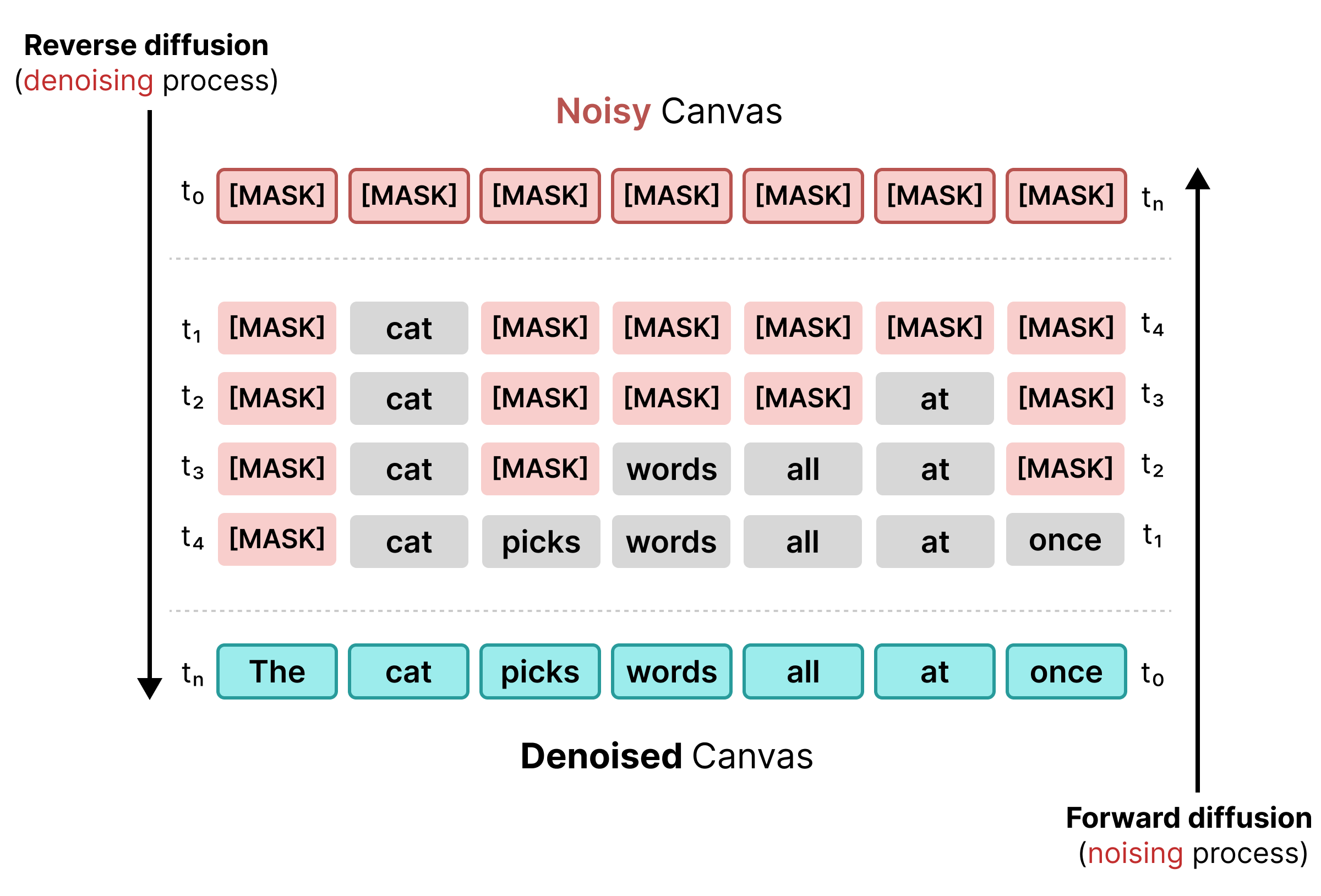
השיטה הראשונה לפיזור טקסט הסתמכה על מיסוך, בדומה לאימון של BERT. אסימונים אקראיים ברצף מוחלפים באסימון [MASK] (שמייצג רעש). במהלך הדיפוזיה ההפוכה, המודל מנבא את הטוקן הנכון מאחורי המסכה, ומחליף טוקנים כשהביטחון עומד בסף מסוים.
עם זאת, לדיפוזיה עם מיסוך יש חסרון: אחרי שמחליפים טוקן [MASK] במילה, הוא ננעל ואי אפשר לתקן אותו בשלבים מאוחרים יותר אם ההקשר משתנה.
2. Uniform State Diffusion
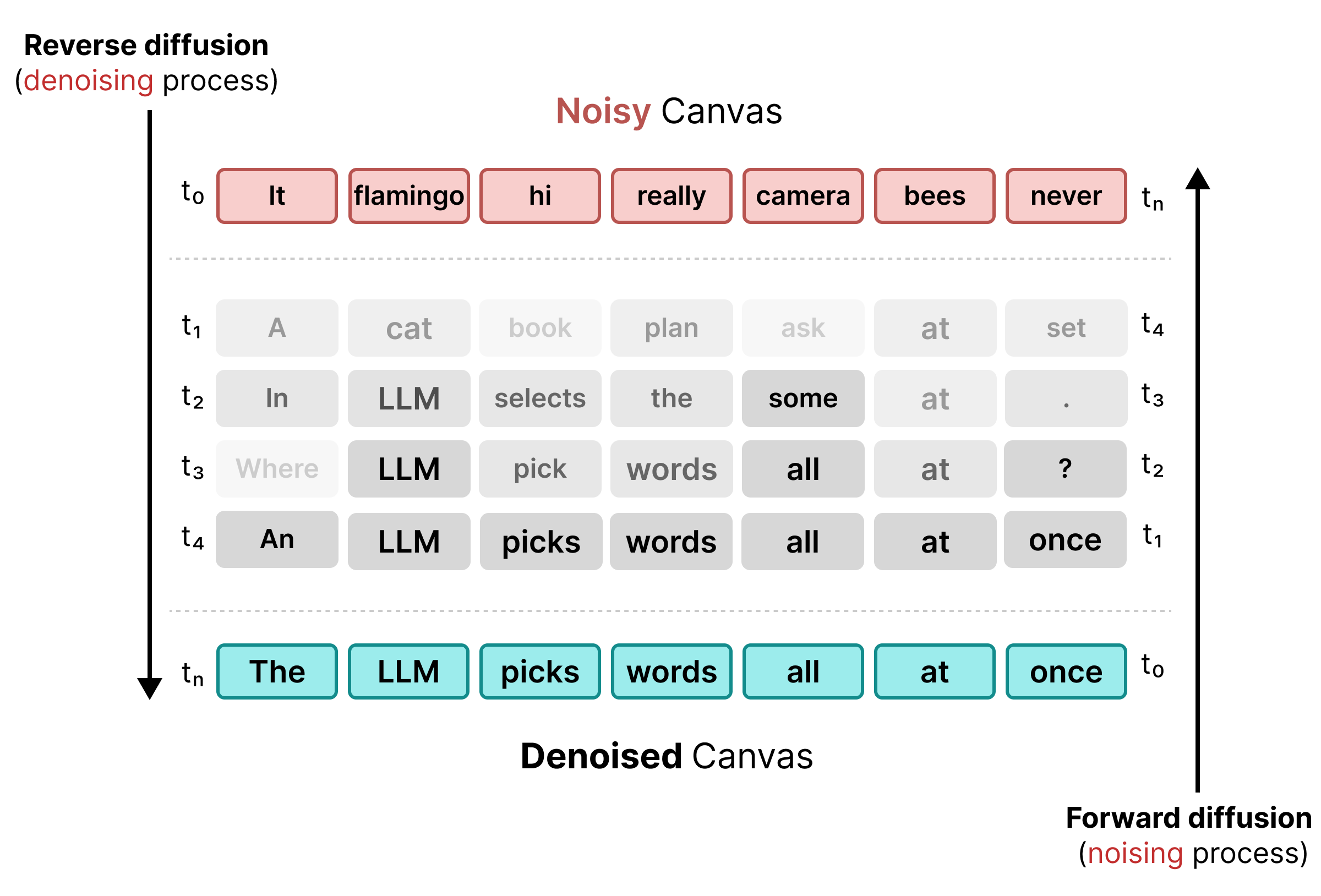
כדי לפתור את הבעיות שקשורות למסכות, נעשה ב-DiffusionGemma שימוש ב-Uniform State Diffusion. במקום באסימון [MASK] מפורש, הרעש מוחדר על ידי החלפת מילים מקוריות באסימונים אקראיים לחלוטין מהאוצר המילים.
במהלך תהליך הסרת הרעשים, המודל מנתח את כל אזור הציור כדי לקבוע אילו טוקנים הם רעשי רקע הקשריים, ומעדכן אותם. אם טוקן מסוים נכון, הוא שומר על הסבירות הגבוהה שלו. אם הסבירות של טוקן יורדת מתחת לסף מסוים בגלל הקשר חדש שנוצר בשלבים מאוחרים יותר, הוא עובר הוספת רעש מחדש עם טוקן אקראי חדש. המחזור הזה מאפשר תיקון שגיאות רציף ושיפור מקביל של אזור הציור.
ארכיטקטורה: מילוי אוטומטי מצטבר וביטול רעשים
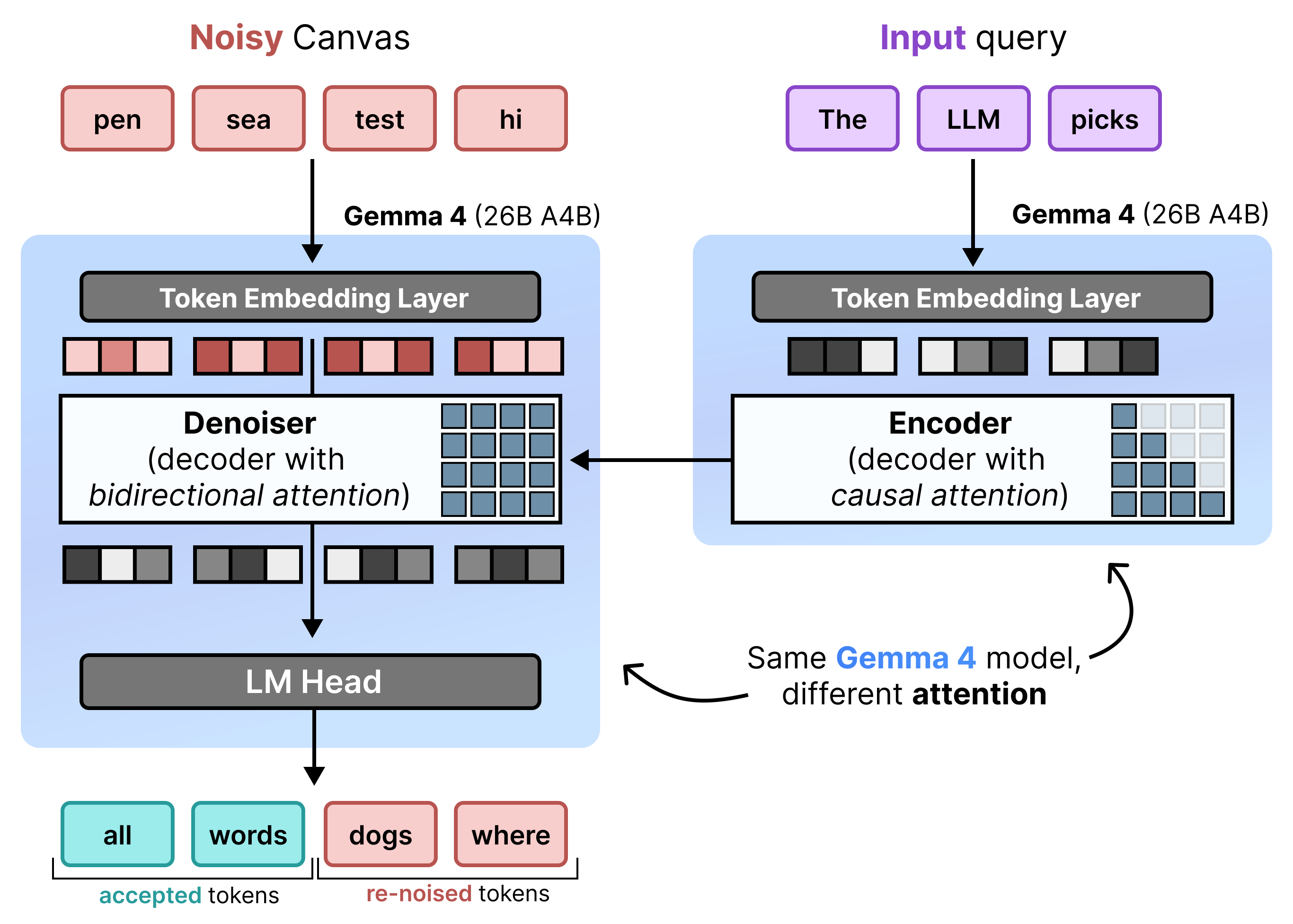
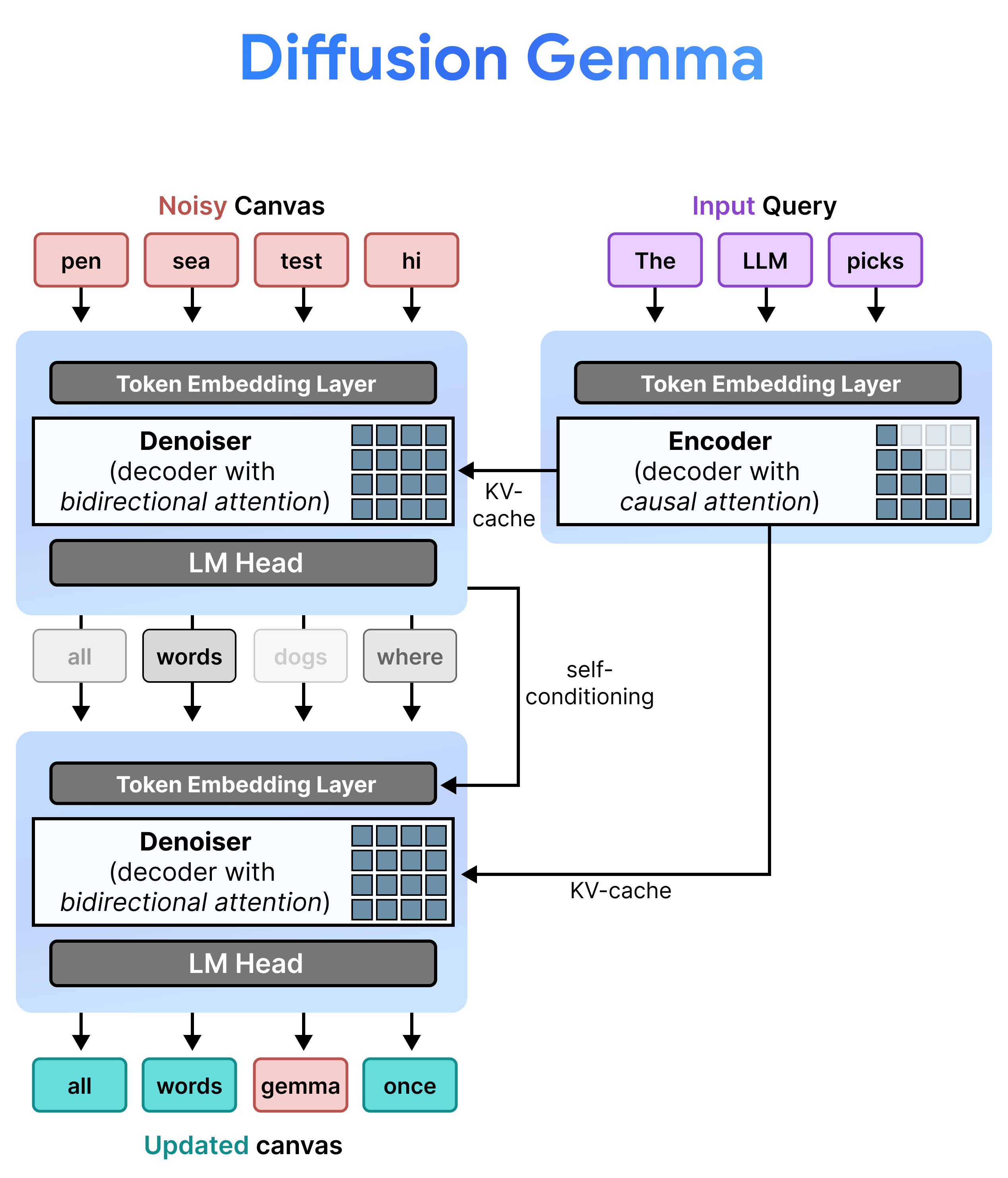
DiffusionGemma מיישם את Uniform State Diffusion ביעילות על ידי מעבר לסירוגין בין Incremental Prefill לבין Denoising. מודל Gemma 4 26B A4B לא נמצא בשימוש באופן מקורי, אלא עובר כוונון עדין כדי לתמוך במשימות השונות של הסרת רעשים וקידוד. במקום להשתמש במודלים נפרדים, יש מודל בסיסי אחד שמשנה את המצב שלו באופן דינמי בין שני מצבים:
- מילוי מראש / מילוי מראש מצטבר (סיבתי): משתמש בתשומת לב סיבתית כדי להזין את ההקשר של ההנחיה ולכתוב למטמון KV. התהליך הזה מופעל פעם אחת כדי למלא מראש את ההקשר הראשוני, ואז פעם אחת לכל בלוק כדי לצרף כל בד ציור סופי של 256 טוקנים למטמון KV לפני שממשיכים להסרת הרעשים של בד הציור הבא.
- הסרת רעשים (דו-כיוונית): נעשה שימוש בהפניית תשומת לב דו-כיוונית כדי להסיר רעשים מהבד באופן איטרטיבי. טוקנים של שאילתות בכל מיקום בקנבס יכולים להתייחס לכל הטוקנים האחרים בקנבס (וגם למטמון KV), וכך המודל יכול לעבד את ההקשר באופן דו-כיווני.
Advanced Inference Frameworks
כדי להפוך רעש אקראי לטקסט סופי, DiffusionGemma משתמש במערכות פענוח בסיסיות:
Self-Conditioning
במהלך ההסקה, המפענח (שנקרא גם מסיר הרעשים) שומר על המצב הקודם שלו. אחרי השלמת שלב הסרת הרעשים, המערכת מכפילה את מטריצת התפלגות ההסתברות שנוצרה בטבלת הטוקנים המוטמעים. התוצאה היא ייצוג וקטורי מקומי שכולל זיכרון של התחזיות הקודמות ומדדי מהימנות, והוא מועבר ישירות לשלב הבא.
דגימה מרובת אזורי עריכה (דיפוזיה של בלוקים)
מכיוון שקנבס יחיד קבוע ל-256 טוקנים, DiffusionGemma משלב דיפוזיה ואוטו-רגרסיה כדי ליצור טקסט ארוך. הוא מריץ מחזורי דיפוזיה כדי ליצור בלוק מלא של 256 טוקנים, מוסיף את הבלוק המלא להקשר של ההנחיה, מעדכן את מטמון ה-KV של המקודד ומתחיל מחזור דיפוזיה חדש של 256 טוקנים.
סיכום
מודלים סטנדרטיים של שפה אוטורגרסיבית יוצרים טקסט באופן רציף (טוקן אחד בכל פעם), ולכן הם מוגבלים בזיכרון ויוצרים צוואר בקבוק של חביון עבור משתמשים פרטיים. DiffusionGemma פותר את הבעיה הזו על ידי מעבר למודל מוגבל-חישוב שמייצר בו-זמנית 'בד' מלא של 256 טוקנים.
המודל משתמש ב-Uniform State Diffusion כדי להחליף טקסט ברעש אקראי של אוצר מילים, ומשפר את כל הקנבס באופן איטרטיבי במקביל. הוא משתמש ב-Gemma 4 26B A4B שעבר כוונון עדין כדי לתמוך במשימות השונות של הסרת רעשים וקידוד. מסגרות מתקדמות כמו self-conditioning ו-multi-canvas block sampling מאפשרות למודל לתקן שגיאות באופן דינמי, לטפל ביצירת טקסט ארוך ולהשיג זמן אחזור נמוך במיוחד למשתמש יחיד.