
Untuk memahami DiffusionGemma, sebaiknya periksa batasan inti model bahasa standar dan perbedaan difusi berbasis teks.
Masalah dengan Model Autoregresif
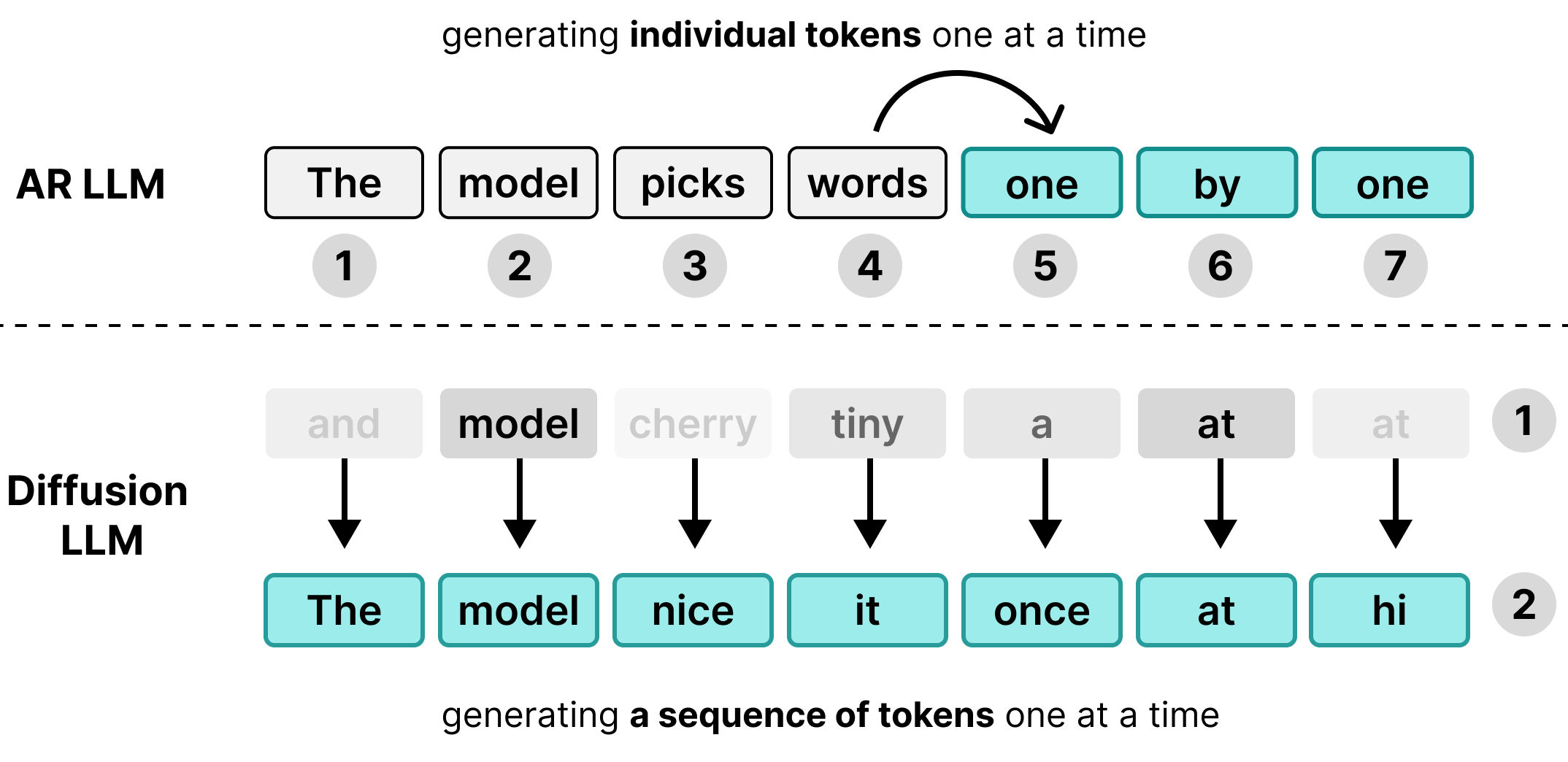
Banyak Model Bahasa Besar (LLM) bersifat autoregresif, yang berarti model tersebut menghasilkan teks satu token pada satu waktu. Meskipun pendekatan ini berfungsi dengan baik untuk melayani banyak pengguna secara bersamaan melalui batching, pendekatan ini menciptakan hambatan latensi untuk setiap pengguna.
Selama fase decoding, model Transformer standar terikat memori , bukan terikat komputasi. Sebagian besar waktu pembuatan digunakan untuk memuat bobot model dari memori hardware ke unit pemrosesan, bukan melakukan perhitungan matematika yang sebenarnya. Karena bobot hanya perlu dimuat satu kali per langkah, terlepas dari ukuran tumpukan, pembuatan token memerlukan waktu yang hampir sama untuk 1 pengguna seperti halnya untuk 256 pengguna yang dikelompokkan bersama.
Akibatnya, setiap pengguna tidak melihat keuntungan latensi; kapasitas komputasi hardware tidak digunakan saat menunggu transfer memori.
DiffusionGemma memanfaatkan waktu komputasi yang tidak digunakan ini untuk setiap pengguna. Daripada membuat 1 token untuk 256 pengguna terpisah, model ini membuat 256 token sekaligus untuk satu pengguna.
Model ini menginisialisasi urutan kosong dari 256 token acak—yang disebut kanvas—dan secara berulang mengevaluasi serta menyempurnakan seluruh kanvas secara bersamaan. Hal ini mengubah model dari terikat memori menjadi terikat komputasi, sehingga memungkinkan model untuk menskalakan kecepatan pemrosesan secara efisien seiring dengan peningkatan daya komputasi.
| Aspek | Autoregresi Teks | Difusi Teks |
|---|---|---|
| Pembuatan Token | Satu token pada satu waktu | Kanvas token lengkap sekaligus |
| Langkah | Satu langkah untuk setiap token | Satu langkah untuk beberapa token |
| Urutan Pembuatan | Kiri-ke-kanan | Semua posisi secara paralel |
| Titik Awal | Urutan kosong | Token acak yang diambil sampelnya dari kosakata |
| Koreksi Error | Statis; tidak dapat merevisi token sebelumnya | Dinamis; dapat merevisi posisi kanvas apa pun |
| Hambatan Hardware | Terikat memori | Terikat komputasi |
| Fokus Throughput | Throughput multi-pengguna tinggi | Latensi satu pengguna ultra-rendah |
Memahami Mekanisme Difusi Teks
Dalam pembuatan gambar, model difusi dimulai dengan noise Gaussian acak 100% dan secara progresif menghapusnya (denoising) melalui beberapa langkah yang dipandu oleh perintah teks. Menerjemahkan logika ini ke teks lebih menantang karena token teks adalah entitas diskrit, tidak seperti nilai piksel kontinu.
DiffusionGemma mencapai difusi berbasis teks melalui perkembangan metodologi khusus:
1. Difusi Bertopeng
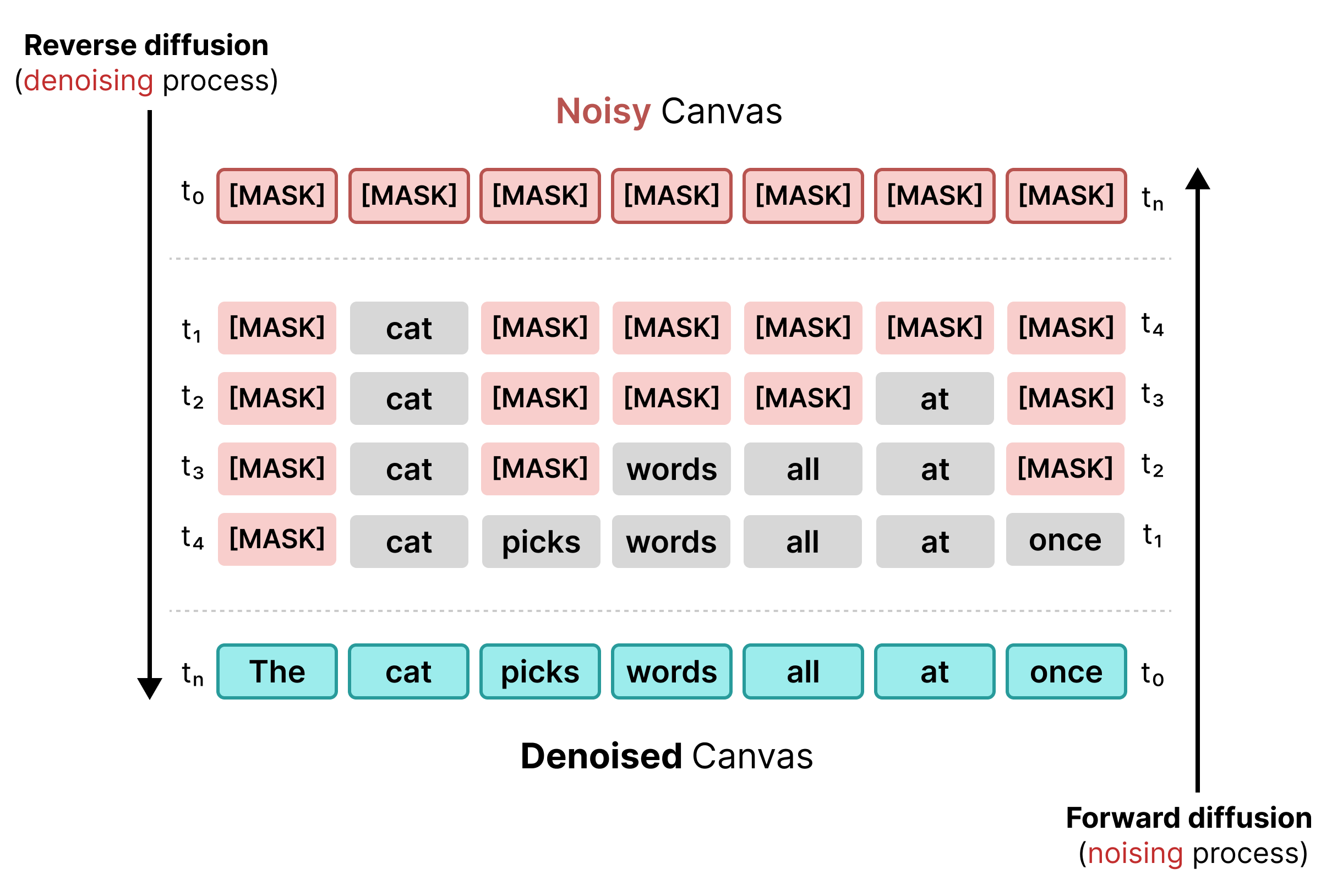
Difusi teks awal mengandalkan penyamaran, mirip dengan pelatihan BERT. Token acak dalam urutan diganti dengan token [MASK] (yang mewakili noise). Selama difusi terbalik, model memprediksi token yang benar di balik topeng, mengganti token jika keyakinan memenuhi nilai minimum tertentu.
Namun, difusi bertopeng memiliki kekurangan: setelah token [MASK] diganti dengan kata, token tersebut akan dikunci. Token tersebut tidak dapat dikoreksi pada langkah berikutnya jika konteks di sekitarnya berubah.
2. Difusi Status Seragam
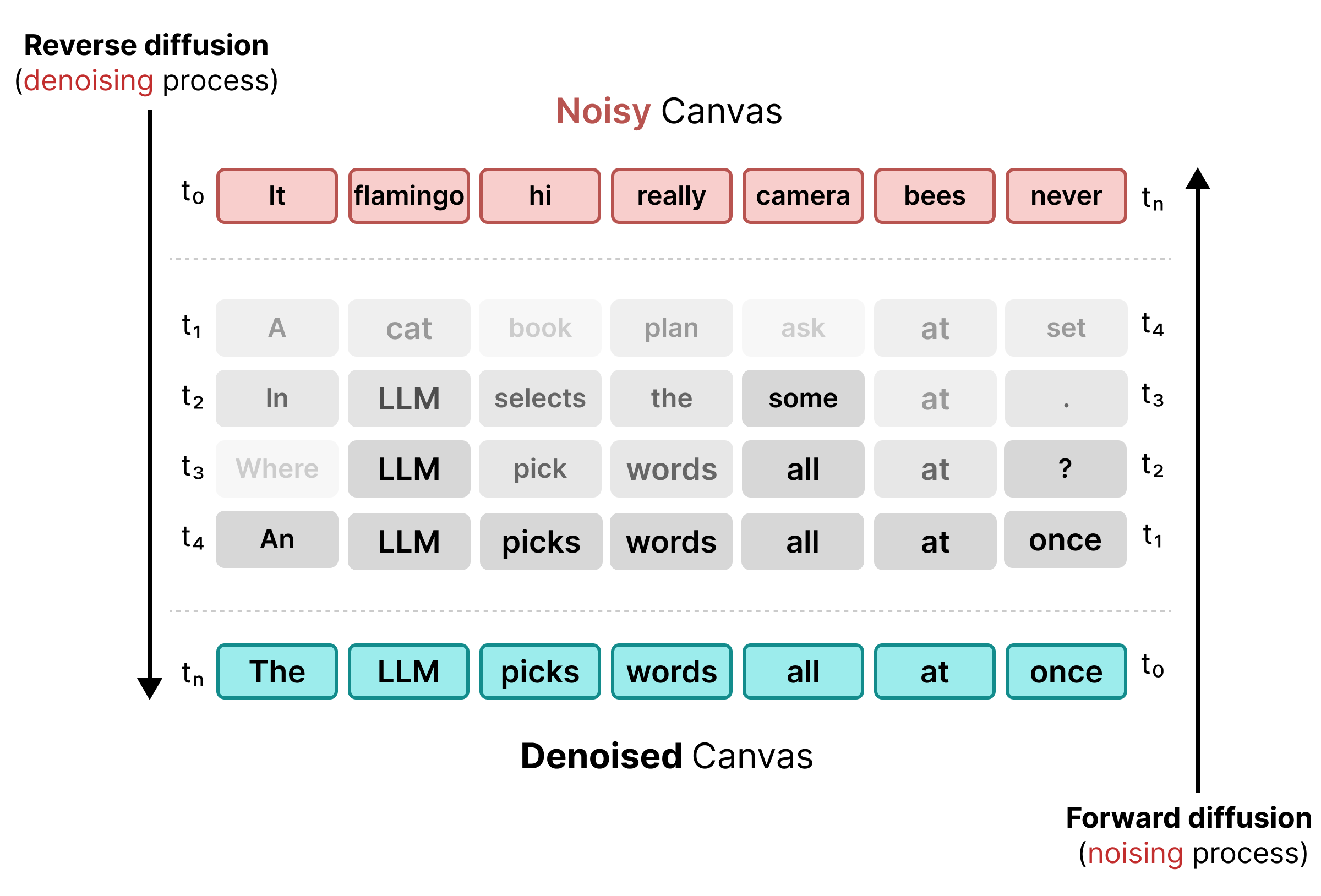
Untuk mengatasi batasan penyamaran, DiffusionGemma menggunakan Difusi Status Seragam. Daripada token [MASK] eksplisit, noise diperkenalkan dengan mengganti kata asli dengan token acak sepenuhnya dari kosakata.
Selama proses denoising, model menganalisis seluruh kanvas untuk menentukan token mana yang merupakan noise kontekstual dan memperbaruinya. Jika token benar, token tersebut akan mempertahankan probabilitas yang tinggi. Jika probabilitas token turun di bawah nilai minimum karena konteks baru muncul pada langkah berikutnya, token tersebut akan diberi noise ulang dengan token acak baru. Siklus ini memungkinkan koreksi error berkelanjutan dan penyempurnaan kanvas paralel.
Arsitektur: Prefill dan denoising inkremental
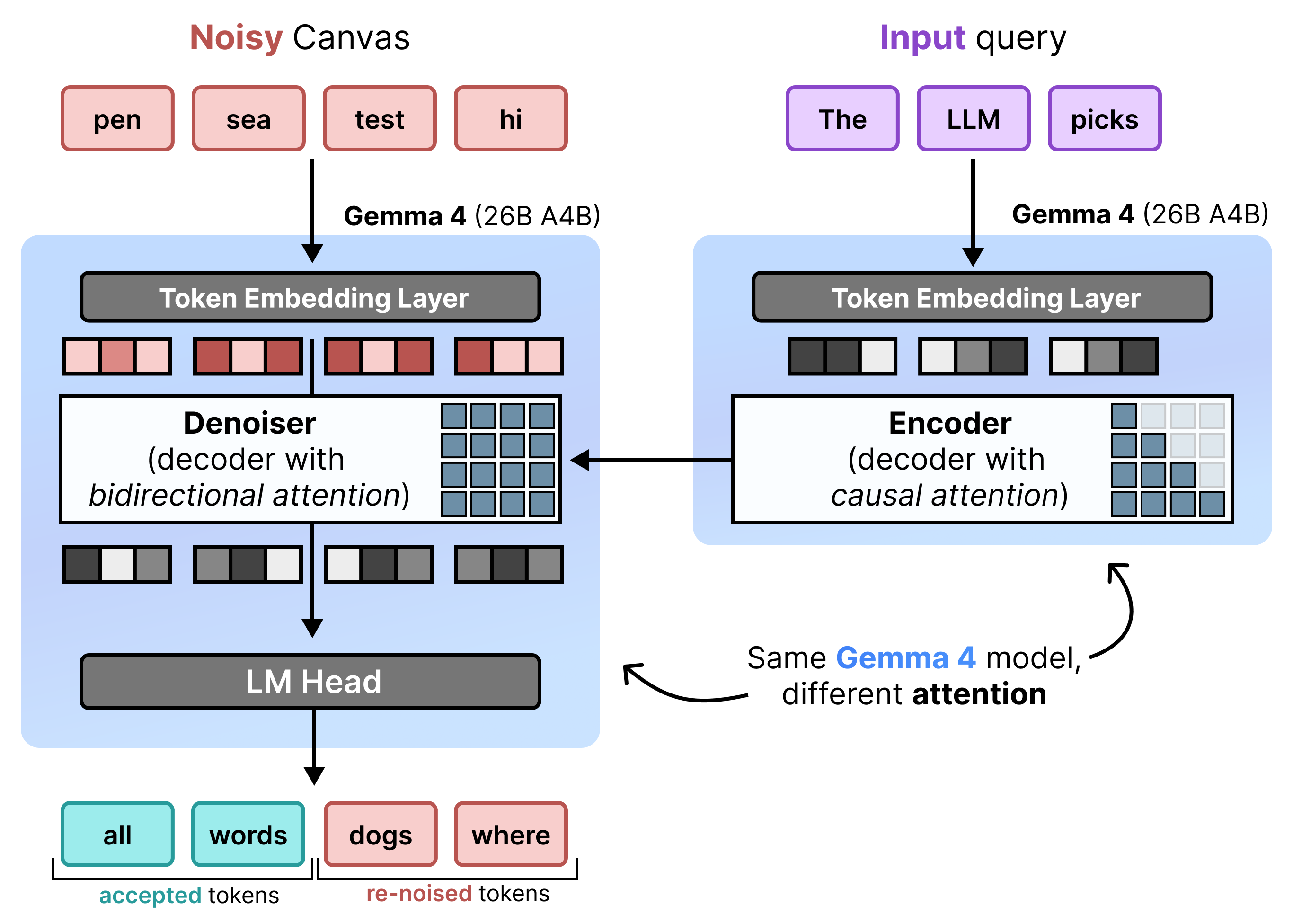
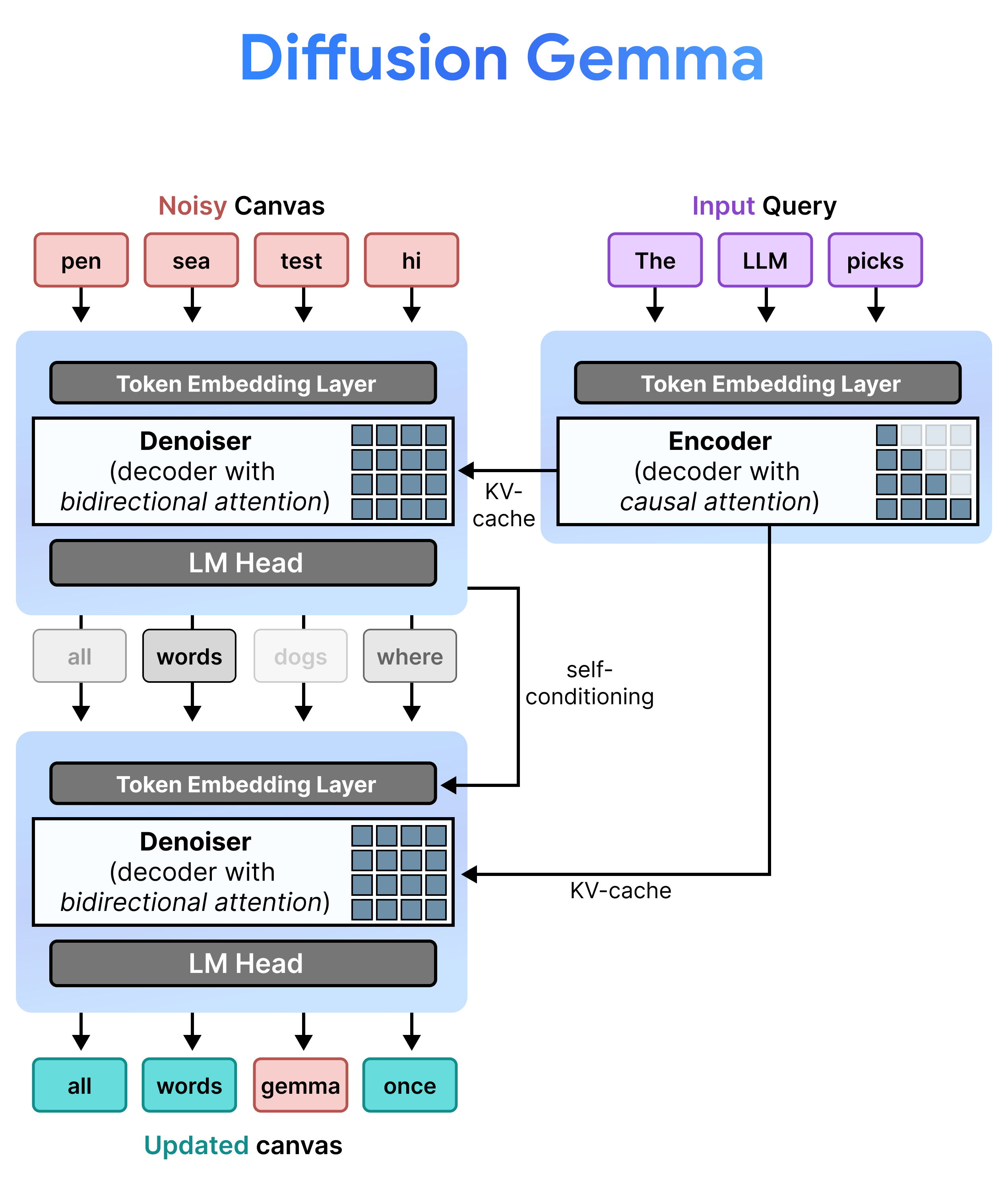
DiffusionGemma menerapkan Difusi Status Seragam secara efisien dengan bergantian antara Prefill Inkremental dan Denoising. Model Gemma 4 26B A4B tidak digunakan secara native, tetapi disesuaikan untuk mendukung berbagai tugas denoising dan encoding. Daripada menggunakan model terpisah, satu backbone akan beralih secara dinamis antara dua mode:
- Prefill / Prefill Inkremental (Kausal): Menggunakan perhatian kausal untuk memasukkan konteks perintah dan menulis ke cache KV. Proses ini dijalankan satu kali untuk mengisi konteks awal dan kemudian satu kali per blok untuk menambahkan setiap kanvas 256 token yang telah diselesaikan ke cache KV sebelum melanjutkan ke denoising kanvas berikutnya.
- Denoising (Dua Arah): Menggunakan perhatian dua arah untuk melakukan denoising kanvas secara berulang. Token kueri di posisi mana pun di kanvas dapat memperhatikan semua token kanvas lainnya (serta cache KV), sehingga model dapat memproses konteks secara dua arah.
Framework Inferensi Lanjutan
Untuk memindahkan kanvas dari noise murni ke teks akhir, DiffusionGemma menggunakan kumpulan sistem decoding dasar:
Kondisi Mandiri
Selama inferensi, decoder (juga dikenal sebagai denoiser) mempertahankan status sebelumnya. Setelah menyelesaikan langkah denoising, decoder akan mengalikan matriks distribusi probabilitas yang dibuat dengan tabel embedding token. Tindakan ini menghasilkan representasi vektor lokal yang membawa memori prediksi sebelumnya dan metrik keyakinan, yang diteruskan langsung ke langkah berikutnya.
Pengambilan Sampel Multi-Kanvas (Difusi Blok)
Karena satu kanvas ditetapkan ke 256 token, DiffusionGemma menggabungkan difusi dan autoregresi untuk teks panjang. Model ini menjalankan siklus difusi untuk membuat blok 256 token lengkap, menambahkan blok yang telah selesai tersebut ke konteks perintah, memperbarui cache KV encoder, dan memulai siklus difusi kanvas 256 token yang baru.
Ringkasan
Model bahasa autoregresif standar menghasilkan teks secara berurutan (satu token pada satu waktu), yang membuatnya terikat memori dan menciptakan hambatan latensi untuk setiap pengguna. DiffusionGemma mengatasi masalah ini dengan beralih ke model terikat komputasi yang menghasilkan "kanvas" 256 token lengkap secara bersamaan.
Dengan menggunakan Difusi Status Seragam, model ini mengganti teks dengan noise kosakata acak dan secara berulang menyempurnakan seluruh kanvas secara paralel. Model ini menggunakan Gemma 4 26B A4B yang disesuaikan untuk mendukung berbagai tugas denoising dan encoding. Framework lanjutan seperti kondisi mandiri, pengambilan sampel blok multi-kanvas memungkinkan model untuk mengoreksi error secara dinamis, menangani pembuatan teks panjang, dan mencapai latensi satu pengguna ultra-rendah.