
DiffusionGemma を理解するには、標準の言語モデルの主な制限事項と、テキストベースの拡散との違いを把握することが重要です。
自己回帰モデルの問題
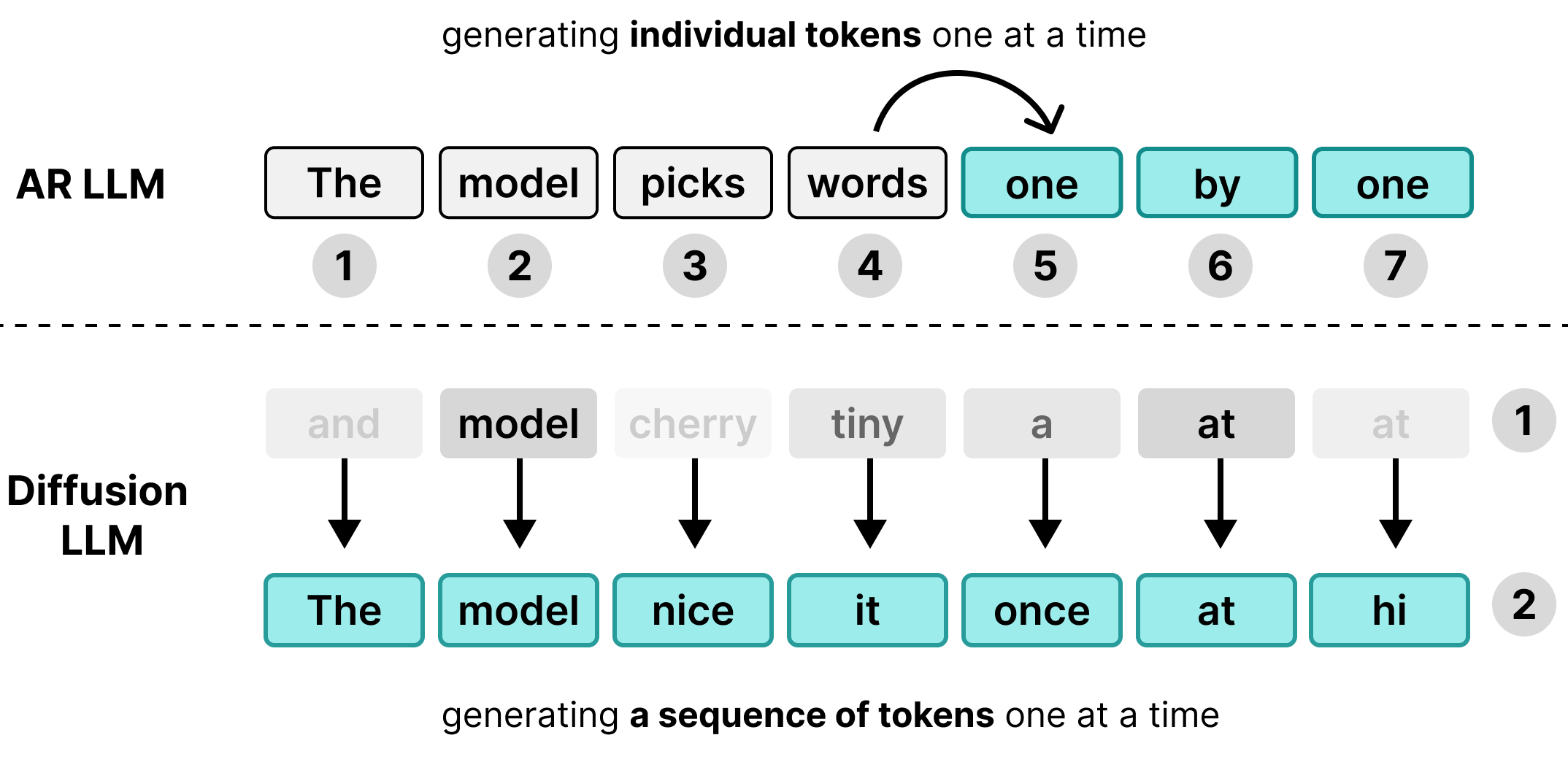
多くの大規模言語モデル(LLM)は自己回帰型です。つまり、一度に 1 つのトークンずつテキストを生成します。このアプローチは、バッチ処理を介して多くのユーザーに同時にサービスを提供するには適していますが、個々のユーザーにとってはレイテンシのボトルネックになります。
デコード フェーズでは、標準の Transformer モデルは計算バウンドではなく、メモリバウンドになります。生成時間のほとんどは、実際の数学的計算の実行ではなく、ハードウェア メモリから処理ユニットへのモデルの重みの読み込みに費やされます。重みはバッチサイズに関係なくステップごとに 1 回だけ読み込む必要があるため、トークンの生成にかかる時間は、1 人のユーザーの場合と 256 人のユーザーをグループ化した場合でほぼ同じになります。
そのため、個々のユーザーにはレイテンシのメリットはありません。メモリ転送を待機している間、ハードウェアの計算能力はアイドル状態になります。
DiffusionGemma は、個々のユーザーのアイドル状態のコンピューティング時間を活用します。256 人の個別のユーザーに対して 1 つのトークンを生成するのではなく、1 人のユーザーに対して 256 個のトークンを一度に生成します。
モデルは、256 個のランダムなトークンの空白シーケンス(キャンバスと呼ばれる)を初期化し、キャンバス全体を同時に反復的に評価して調整します。これにより、モデルはメモリバウンドからコンピューティング バウンドに移行し、コンピューティング能力の向上に合わせて処理速度を効率的にスケーリングできます。
| 要素 | テキストの自己回帰 | テキスト拡散 |
|---|---|---|
| トークン生成 | 一度に 1 つのトークン | トークンのキャンバス全体を一度に表示する |
| 手順 | トークンごとに 1 ステップ | 複数のトークンに対する 1 つのステップ |
| 生成順序 | 左から右 | すべてのポジションを並行して実行 |
| スターター コード | 空のシーケンス | 語彙からサンプリングされたランダム トークン |
| エラー修正 | 静的。過去のトークンを修正することはできません | 動的。キャンバスの位置を修正できます |
| ハードウェアのボトルネック | メモリバウンド | コンピューティング バウンド |
| スループット フォーカス | マルチユーザーでの高いスループット | 超低レイテンシ(シングル ユーザー) |
テキスト拡散の仕組みを理解する
画像生成では、拡散モデルは 100% ランダムなガウス ノイズから始まり、テキスト プロンプトに沿って複数のステップでノイズを段階的に除去(ノイズ除去)します。テキスト トークンは連続するピクセル値とは異なり、離散的なエンティティであるため、このロジックをテキストに変換するのはより困難です。
DiffusionGemma は、特殊な手法の進行を通じてテキストベースの拡散を実現します。
1. Masked Diffusion
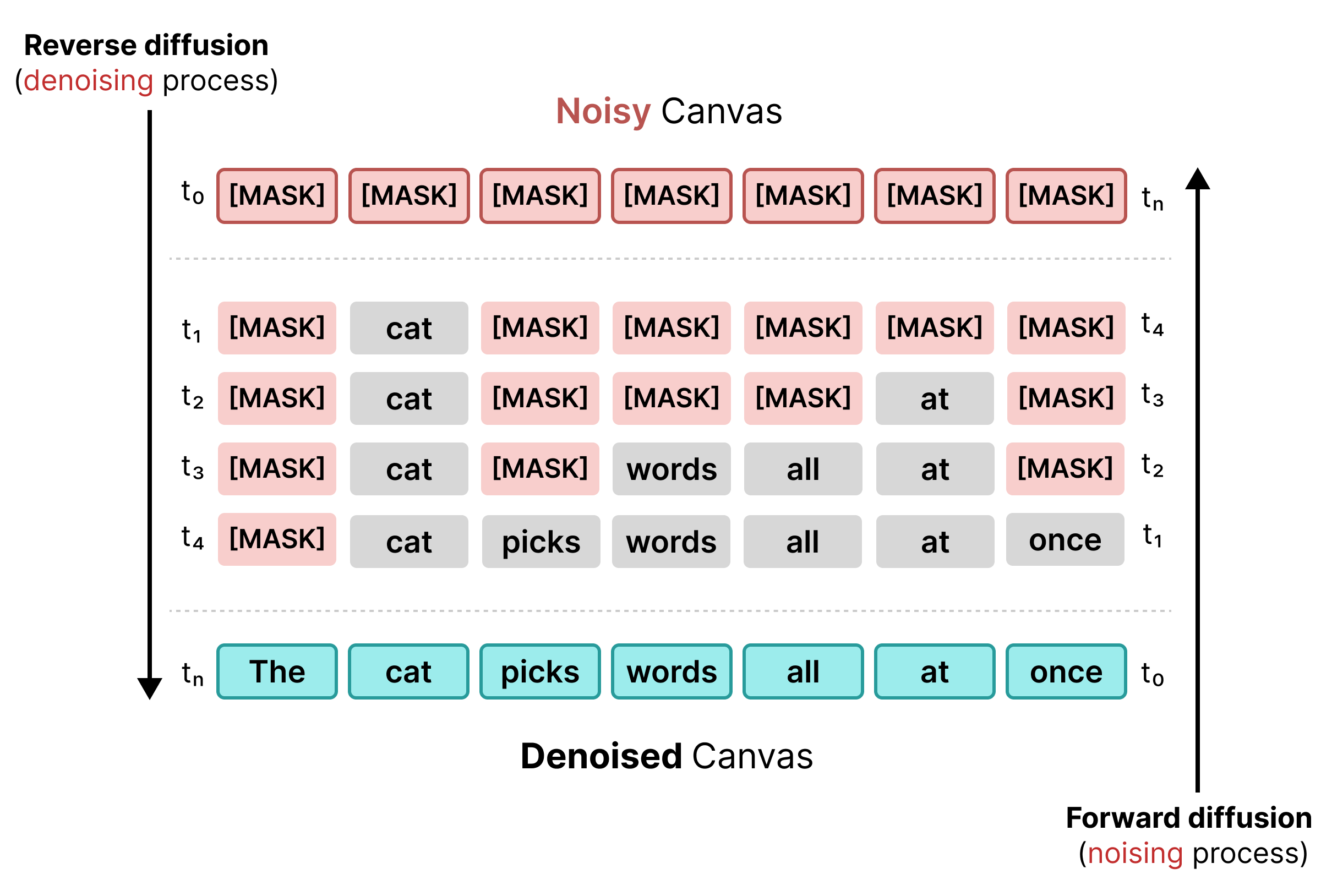
初期のテキスト拡散は、BERT トレーニングと同様にマスキングに依存していました。シーケンス内のランダムなトークンは、[MASK] トークン(ノイズを表す)に置き換えられます。逆拡散中、モデルはマスクの背後にある正しいトークンを予測し、信頼度が特定のしきい値を満たすトークンを置き換えます。
ただし、マスクされた拡散には剛性という問題があります。[MASK] トークンが単語に置き換えられると、その単語はロックされ、周囲のコンテキストが変化しても、後続のステップで修正できません。
2. Uniform State Diffusion
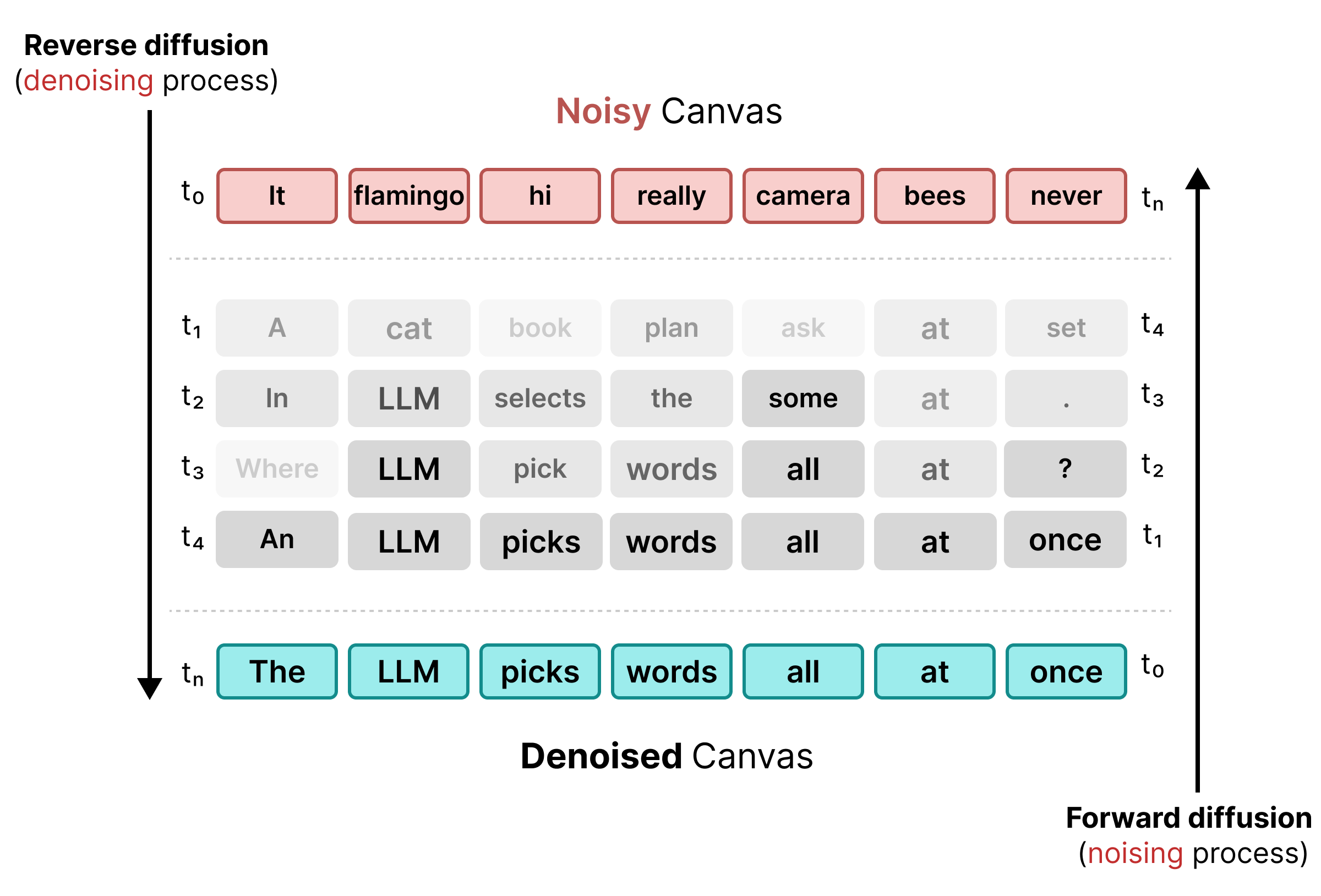
マスキングの制限を解決するために、DiffusionGemma は Uniform State Diffusion を使用します。明示的な [MASK] トークンの代わりに、元の単語を語彙の完全にランダムなトークンに置き換えることでノイズが導入されます。
ノイズ除去プロセスでは、モデルはキャンバス全体を分析して、どのトークンがコンテキスト ノイズであるかを判断し、それらを更新します。トークンが正しい場合は、高い確率が維持されます。後続のステップで新しいコンテキストが出現したためにトークンの確率がしきい値を下回った場合は、新しいランダム トークンでノイズ除去が再度行われます。このサイクルにより、継続的なエラー修正と並列キャンバスの改善が可能になります。
アーキテクチャ: 増分プリフィルとノイズ除去
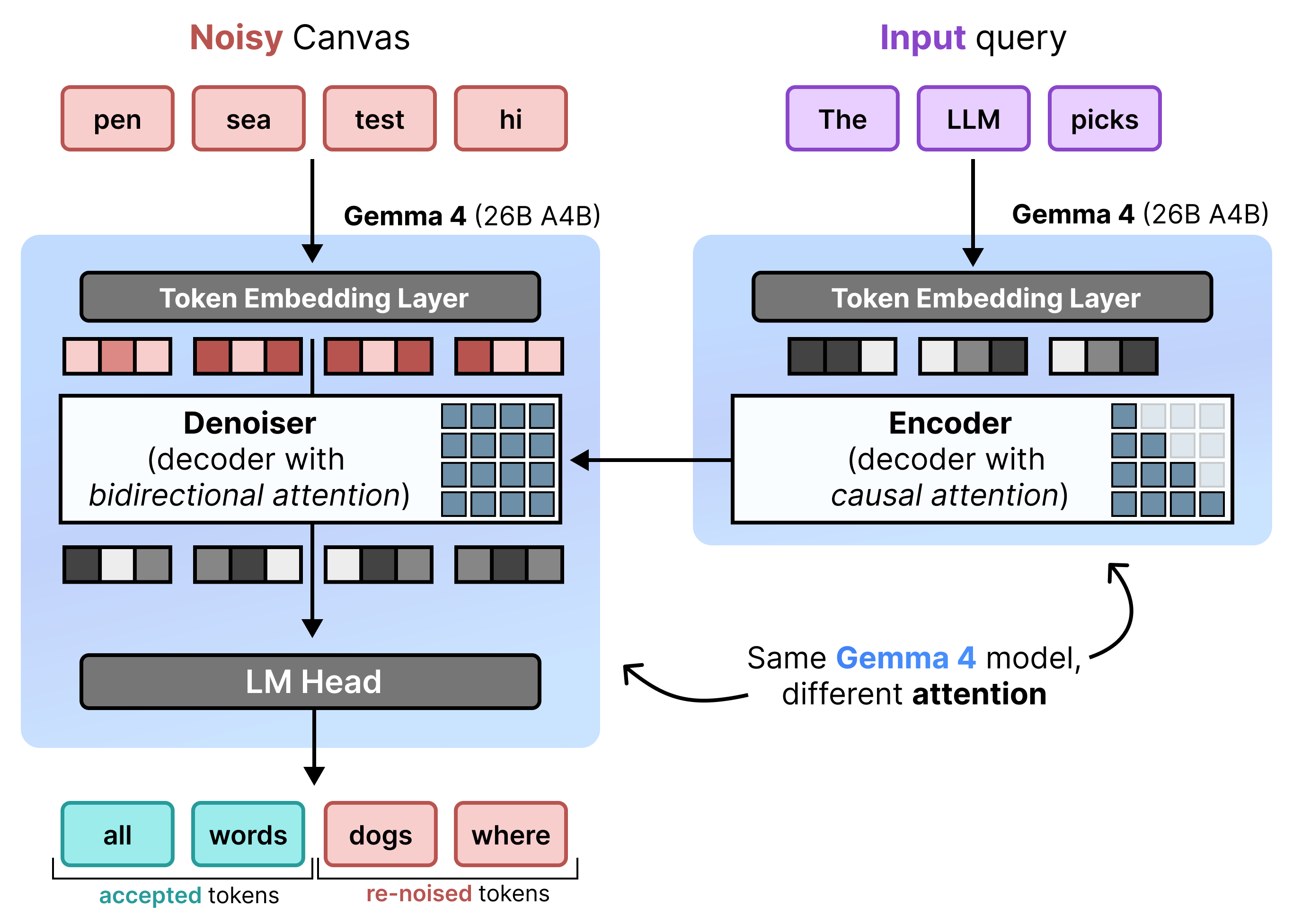
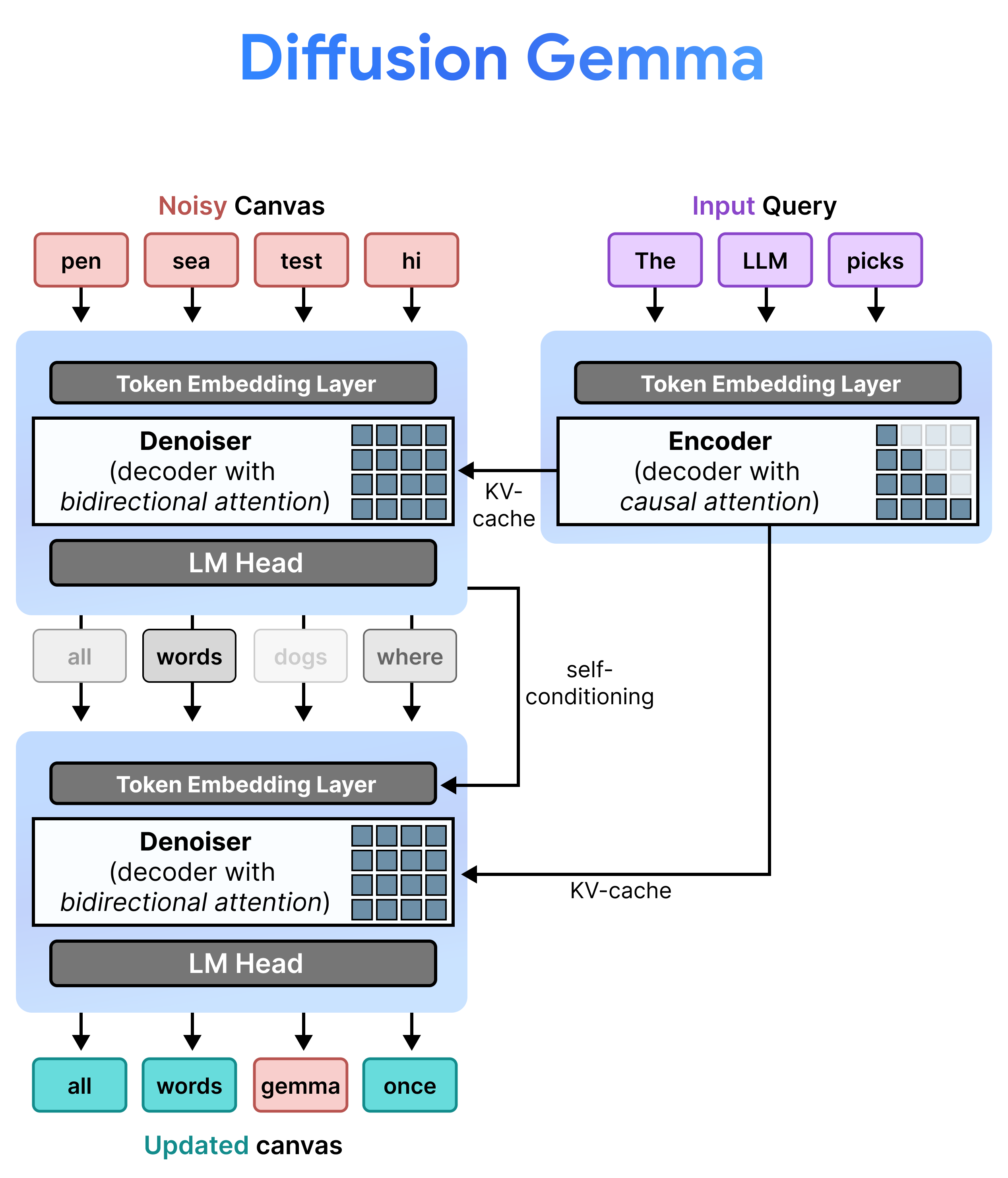
DiffusionGemma は、増分プリフィルとノイズ除去を交互に行うことで、Uniform State Diffusion を効率的に実装します。Gemma 4 26B A4B モデルはネイティブに使用されませんが、ノイズ除去とエンコードのさまざまなタスクをサポートするようにファイン チューニングされています。個別のモデルを使用するのではなく、単一のバックボーンが 2 つのモードを動的に切り替えます。
- プレフィル / 増分プレフィル(因果関係): 因果関係の注意を使用して、プロンプト コンテキストを取り込み、KV キャッシュに書き込みます。これは、初期コンテキストをプレフィルするために 1 回実行され、次に各ブロックごとに 1 回実行されて、次のキャンバスのノイズ除去に進む前に、最終的な 256 トークン キャンバスを KV キャッシュに追加します。
- ノイズ除去(双方向): 双方向アテンションを使用して、キャンバスのノイズを繰り返し除去します。キャンバス上の任意の場所にあるクエリ トークンは、他のすべてのキャンバス トークン(および KV キャッシュ)に注意を払い、モデルがコンテキストを双方向に処理できるようにします。
高度な推論フレームワーク
DiffusionGemma は、キャンバスを純粋なノイズから最終的なテキストに移動するために、基盤となるデコード システムのコレクションを利用します。
セルフ コンディショニング
推論中、デコーダ(デノイザーとも呼ばれます)は以前の状態を保持します。ノイズ除去ステップが完了すると、生成された確率分布行列にトークン エンベディング テーブルが乗算されます。これにより、以前の予測と信頼度指標のメモリを含むローカライズされたベクトル表現が生成され、次のステップに直接渡されます。
マルチキャンバス サンプリング(ブロック拡散)
単一のキャンバスは 256 個のトークンに固定されているため、DiffusionGemma は長文テキスト用に拡散と自己回帰を連結します。拡散サイクルを実行して 256 トークンのブロック全体を生成し、その完成したブロックをプロンプト コンテキストに追加して、エンコーダの KV キャッシュを更新し、新しい 256 トークンのキャンバス拡散サイクルを開始します。
概要
標準的な自己回帰言語モデルはテキストを順次(一度に 1 つのトークン)生成するため、メモリが制約され、個々のユーザーに対してレイテンシのボトルネックが生じます。DiffusionGemma は、256 トークンの「キャンバス」全体を同時に生成するコンピューティング バウンド モデルに移行することで、この問題を解決します。
Uniform State Diffusion を利用することで、モデルはテキストをランダムな語彙ノイズに置き換え、キャンバス全体を並行して反復的に調整します。ファインチューニングされた Gemma 4 26B A4B を使用して、ノイズ除去とエンコードのさまざまなタスクをサポートします。セルフ コンディショニングやマルチキャンバス ブロック サンプリングなどの高度なフレームワークにより、モデルはエラーを動的に修正し、長文の生成を処理し、超低遅延のシングル ユーザーを実現します。