
Për të kuptuar DiffusionGemma, ndihmon të shqyrtohen kufizimet kryesore të modeleve të gjuhës standarde dhe se si ndryshon difuzioni i bazuar në tekst.
Problemi me modelet autoregresive
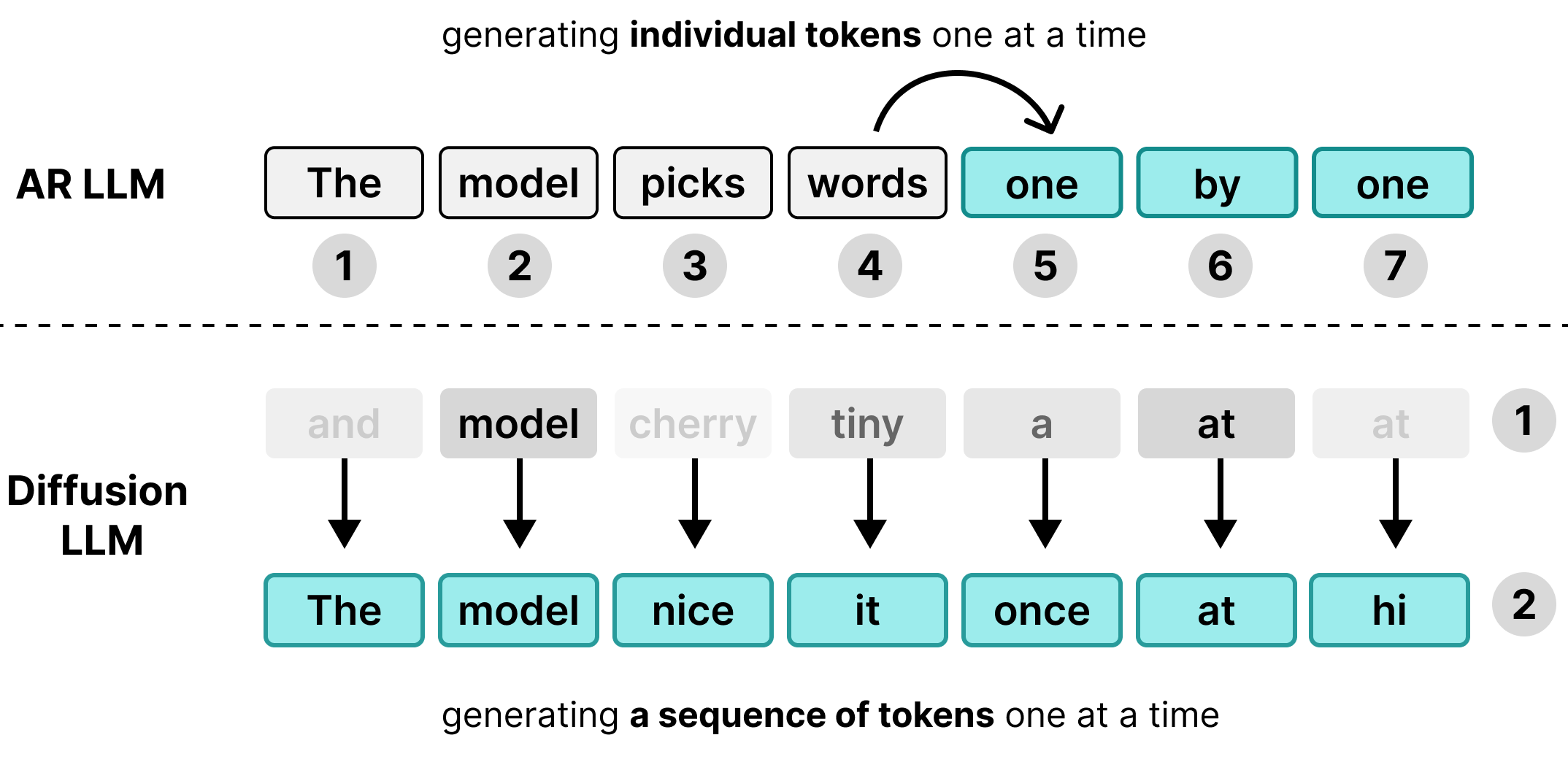
Shumë Modele të Mëdha Gjuhësore (LLM) janë autoregresive , që do të thotë se ato gjenerojnë tekst një token të vetëm në të njëjtën kohë. Ndërsa kjo qasje funksionon mirë për t'i shërbyer shumë përdoruesve njëkohësisht nëpërmjet grumbullimit, ajo krijon një pengesë latente për përdoruesit individualë.
Gjatë fazës së dekodimit, modelet standarde të Transformerit janë të lidhura me memorien dhe jo me llogaritjen. Pjesa më e madhe e kohës së gjenerimit shpenzohet duke ngarkuar peshat e modelit nga memoria e harduerit në njësitë e përpunimit, në vend që të kryejnë llogaritjet aktuale matematikore. Meqenëse peshat duhet të ngarkohen vetëm një herë për hap, pavarësisht nga madhësia e grupit, gjenerimi i një tokeni kërkon pothuajse të njëjtën kohë për 1 përdorues sa për 256 përdorues të grupuar së bashku.
Si pasojë, një përdorues individual nuk sheh asnjë avantazh në latencë; kapaciteti llogaritës i harduerit qëndron i papunë ndërsa pret transferimet e memories.
DiffusionGemma e përdor këtë kohë llogaritëse të papërgatitur për përdoruesin individual. Në vend që të gjenerojë 1 token për 256 përdorues të veçantë, ai gjeneron 256 tokena njëherësh për një përdorues të vetëm.
Modeli inicializon një sekuencë bosh prej 256 tokenësh të rastësishëm - të quajtur kanavacë - dhe vlerëson dhe përpunon në mënyrë iterative të gjithë kanavacën njëkohësisht. Kjo e zhvendos modelin nga të qenit i lidhur me memorien në të qenit i lidhur me llogaritjen , duke i lejuar atij të shkallëzojë shpejtësitë e përpunimit në mënyrë efikase ndërsa fuqia llogaritëse rritet.
| Aspekt | Autoregresioni i tekstit | Përhapja e Tekstit |
|---|---|---|
| Gjenerimi i Tokenëve | Një shenjë në të njëjtën kohë | Një kanavacë e plotë me tokena në të njëjtën kohë |
| Hapat | Një hap për secilin token | Një hap për shumë tokena |
| Renditja e Gjenerimit | Nga e majta në të djathtë | Të gjitha pozicionet paralelisht |
| Pika e fillimit | Sekuencë boshe | Shenja të rastësishme të marra nga fjalori |
| Korrigjimi i Gabimit | Statik; nuk mund të rishikojë tokenët e kaluar | Dinamik; mund të rishikojë çdo pozicion të kanavacës |
| Vështirësi në harduer | I kufizuar nga kujtesa | I lidhur me llogaritjen |
| Fokusi i Prodhimit | Rendiment i lartë për shumë përdorues | Vonesa ultra e ulët për një përdorues të vetëm |
Kuptimi i Mekanikës së Difuzionit të Tekstit
Në gjenerimin e imazheve, modelet e difuzionit fillojnë me zhurmë 100% të rastësishme Gaussian dhe e heqin atë në mënyrë progresive (zhurmëzim) gjatë hapave të shumëfishtë të udhëhequr nga një kërkesë teksti. Përkthimi i kësaj logjike në tekst është më sfidues sepse tokenët e tekstit janë entitete diskrete, ndryshe nga vlerat e vazhdueshme të pikselëve.
DiffusionGemma arrin difuzionin e bazuar në tekst përmes një progresioni të metodologjive të specializuara:
1. Difuzion i maskuar
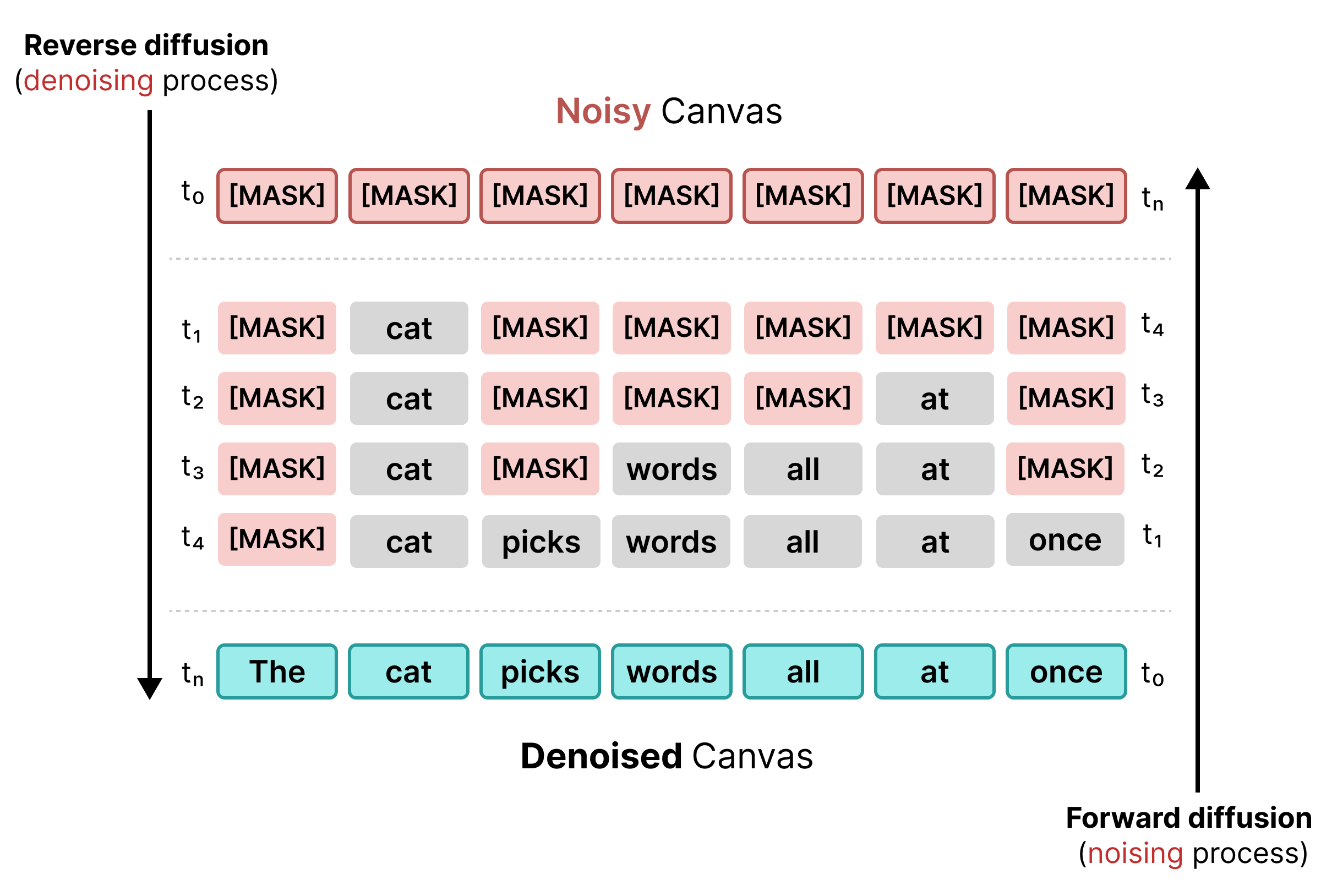
Difuzioni i hershëm i tekstit mbështetej në maskimin, ngjashëm me trajnimin BERT. Shenjat e rastësishme në një sekuencë zëvendësohen me një shenjë [MASK] (që përfaqëson zhurmën). Gjatë difuzionit të kundërt, modeli parashikon shenjën e saktë pas maskës, duke zëvendësuar shenjat aty ku besimi përmbush një prag specifik.
Megjithatë, difuzioni i maskuar vuan nga ngurtësia: sapo një shenjë [MASK] zëvendësohet me një fjalë, ajo fiksohet. Nuk mund të korrigjohet në hapat e mëvonshëm nëse konteksti përreth ndryshon.
2. Përhapja e Gjendjes Uniforme
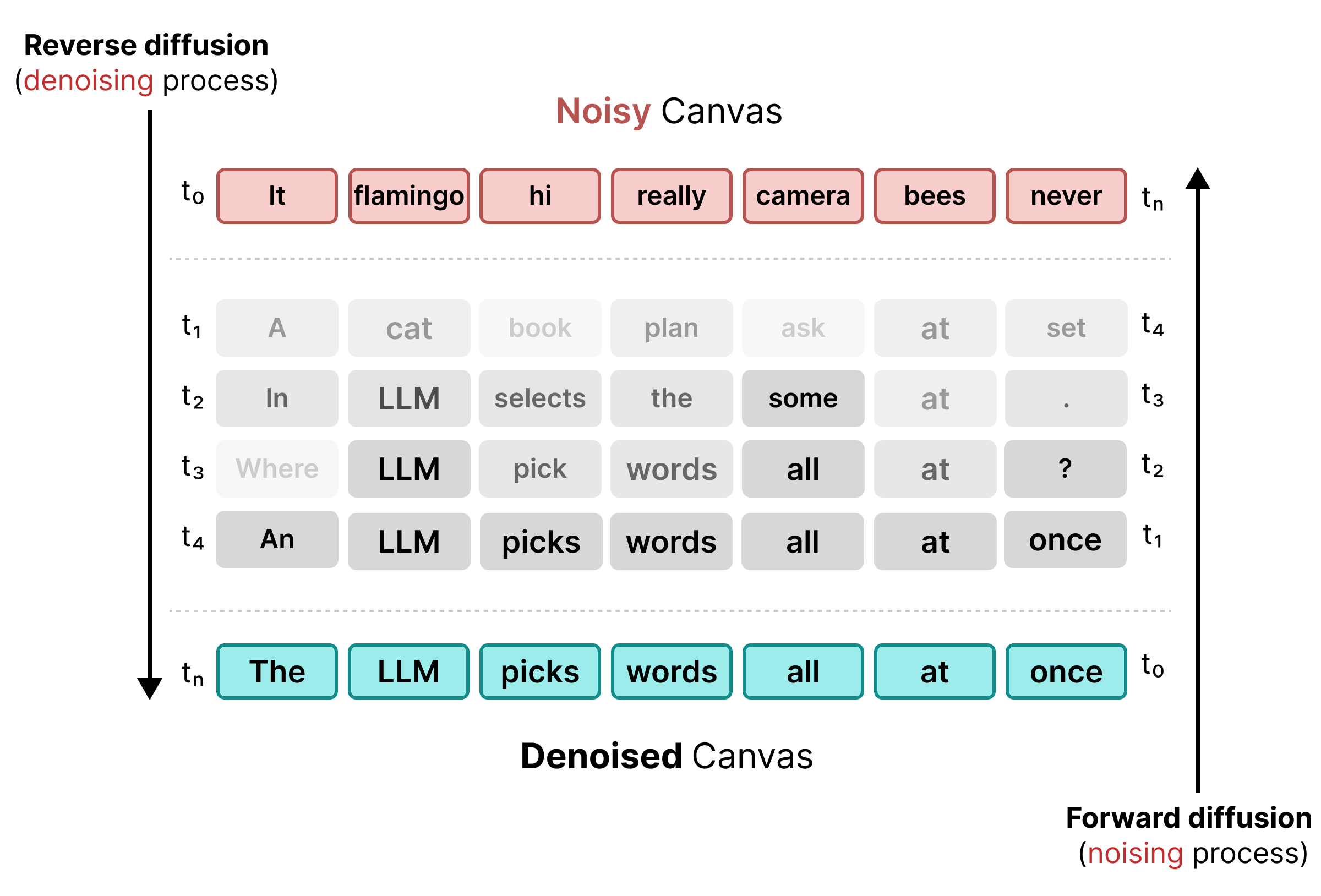
Për të zgjidhur kufizimet e maskimit, DiffusionGemma përdor Uniform State Diffusion . Në vend të një tokeni [MASK] të qartë, futet zhurmë duke zëvendësuar fjalët origjinale me tokenë krejtësisht të rastësishëm nga fjalori.
Gjatë procesit të heqjes së zhurmës, modeli analizon të gjithë kanavacën për të përcaktuar se cilat tokena janë zhurmë kontekstuale dhe i përditëson ato. Nëse një token është i saktë, ai ruan një probabilitet të lartë. Nëse probabiliteti i një tokeni bie nën një prag për shkak të kontekstit të ri që shfaqet në hapat e mëvonshëm, atij i bëhet zhurmë e re me një token të ri të rastësishëm. Ky cikël lejon korrigjim të vazhdueshëm të gabimeve dhe rafinim paralel të kanavacës.
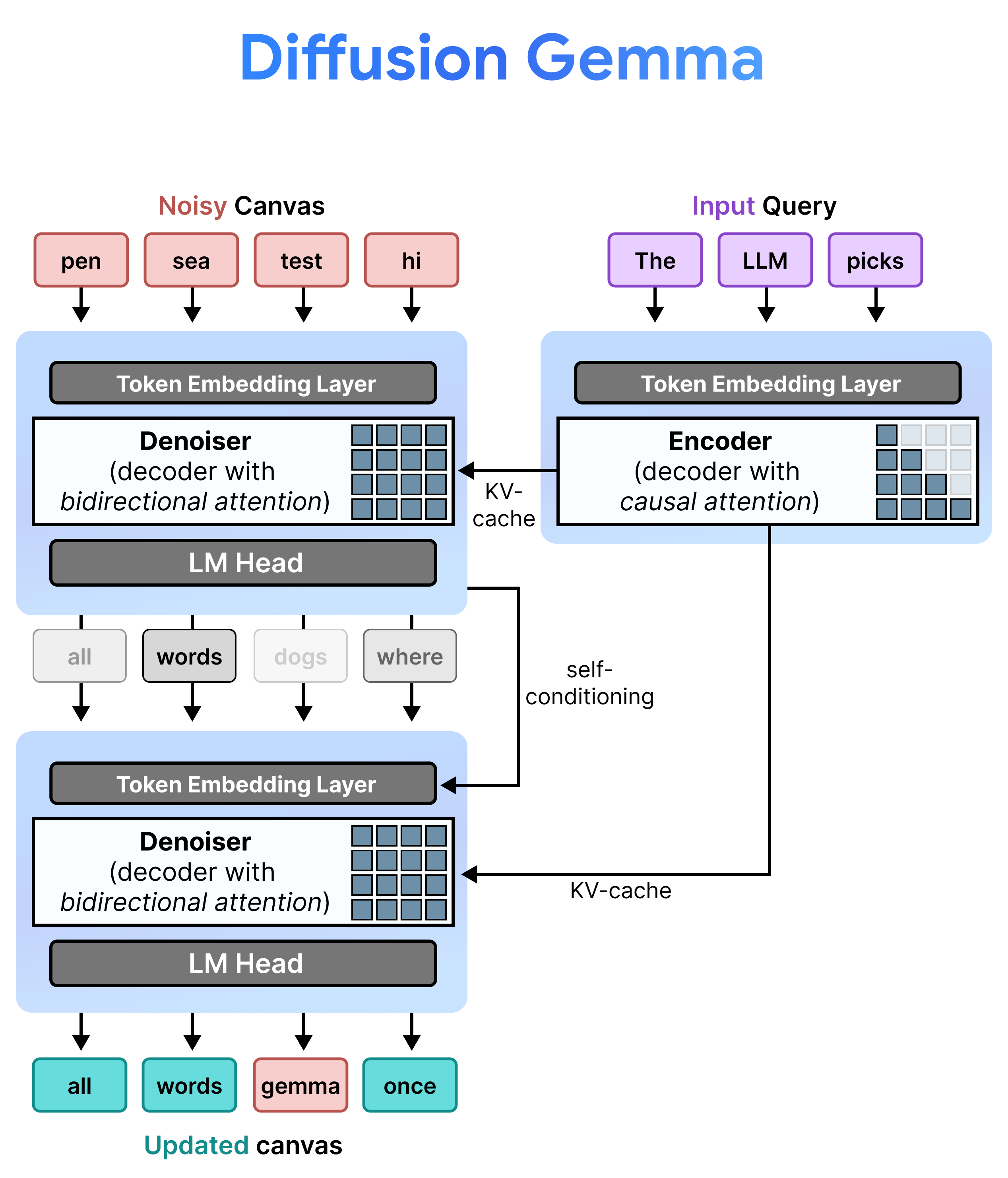
Arkitektura: Mbushja paraprake dhe heqja e zhurmës në mënyrë graduale
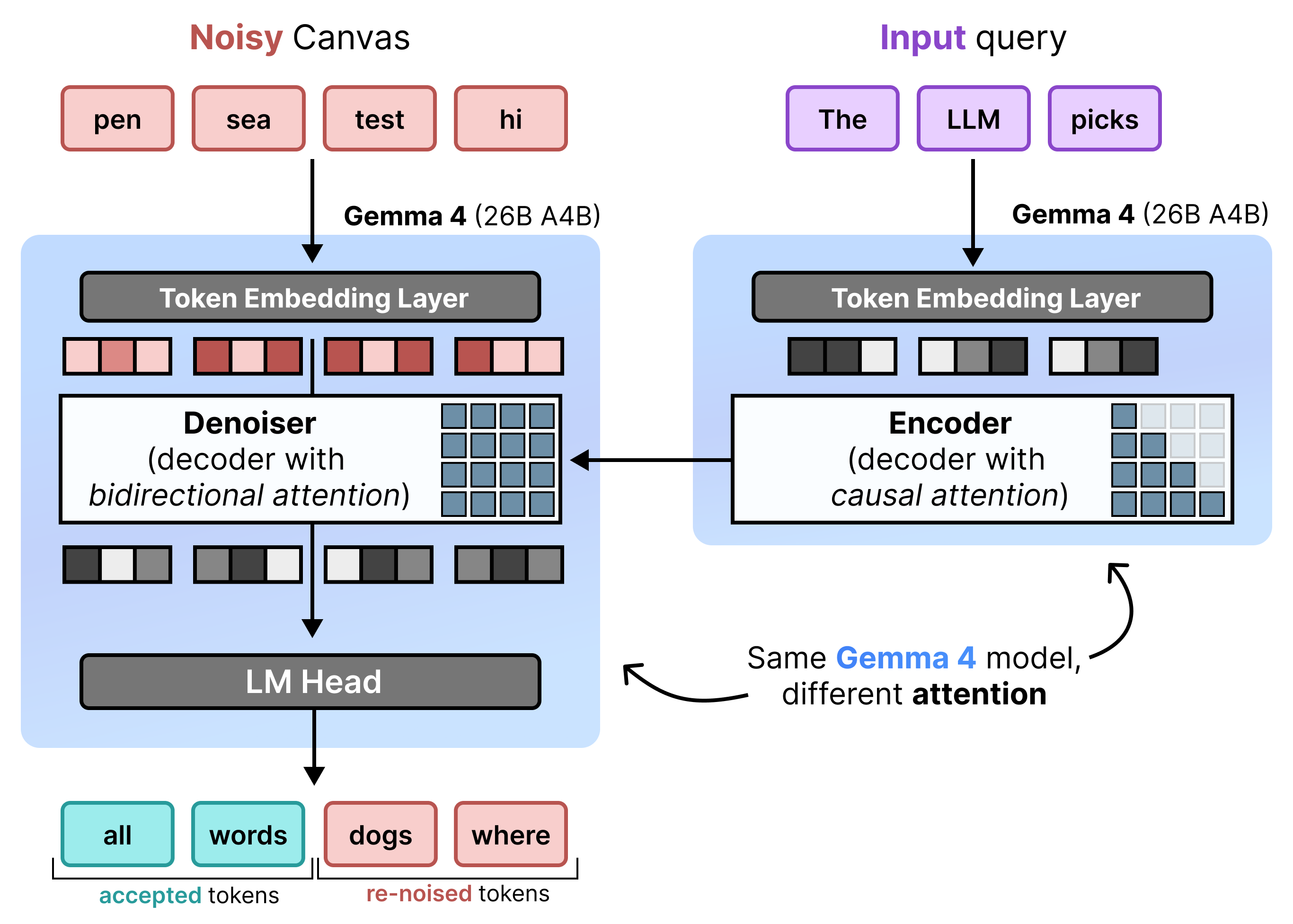
DiffusionGemma zbaton në mënyrë efikase Uniform State Diffusion duke alternuar midis Parambushjes Incrementale dhe Zhveshjes së Zhurmës . Modeli Gemma 4 26B A4B nuk përdoret në mënyrë native, por është i përshtatur për të mbështetur detyrat e ndryshme të zhveshjes së zhurmës dhe kodimit. Në vend që të përdoren modele të ndara, një rrjet i vetëm shtyllës kurrizore kalon dinamikisht midis dy mënyrave:
- Parambushje / Parambushje Rritëse (Shkakore): Përdor vëmendjen shkakësore për të përthithur kontekstin e kërkesës dhe për të shkruar në memorjen e përkohshme KV. Kjo ekzekutohet një herë për të parambushur kontekstin fillestar dhe pastaj një herë për bllok për të shtuar çdo kanavacë të finalizuar me 256 shenja në memorjen e përkohshme KV përpara se të vazhdojë me heqjen e zhurmës nga kanavaca tjetër.
- Zhurmëzimi (Bidireksional): Përdor vëmendje bidireksionale për të zhurmuar në mënyrë iterative kanavacën. Tokenët e pyetjeve në çdo pozicion në kanavacë mund të marrin pjesë në të gjithë tokenët e tjerë të kanavacës (si dhe në memorjen e përkohshme KV), duke e lejuar modelin të përpunojë kontekstin në mënyrë bidireksionale.
Kornizat e Inferencës së Avancuar
Për të zhvendosur një kanavacë nga zhurma e pastër në tekstin e finalizuar, DiffusionGemma përdor një koleksion sistemesh themelore të dekodimit:
Vetë-kushtëzim
Gjatë nxjerrjes së përfundimit, dekoderi (i njohur edhe si dezhurmuesi) ruan gjendjen e tij të mëparshme. Pas përfundimit të një hapi dezhurmimi, ai shumëzon matricën e gjeneruar të shpërndarjes së probabilitetit me tabelën e ngulitjes së tokenëve. Kjo prodhon një përfaqësim vektorial të lokalizuar që mbart një kujtesë të parashikimeve të tij të mëparshme dhe metrikave të besimit, e cila kalohet direkt në hapin tjetër.
Marrja e mostrave me shumë kanavacë (shpërndarja e bllokut)
Meqenëse një kanavacë e vetme është e fiksuar në 256 tokena, DiffusionGemma lidh së bashku difuzionin dhe autoregresionin për tekstin në formë të gjatë. Ai ekzekuton cikle difuzioni për të gjeneruar një bllok të plotë prej 256 tokenash, ia shton atë bllok të përfunduar kontekstit të kërkesës, përditëson memorien e përkohshme KV të koduesit dhe nis një cikël krejt të ri difuzioni të kanavacës prej 256 tokenash.
Përmbledhje
Modelet standarde të gjuhës autoregresive gjenerojnë tekst në mënyrë sekuenciale (një token në të njëjtën kohë), gjë që i bën ato të kufizuara në kujtesë dhe krijon një pengesë latente për përdoruesit individualë. DiffusionGemma e zgjidh këtë duke kaluar në një model të kufizuar në llogaritje që gjeneron një "kanavacë" të plotë me 256 token njëkohësisht.
Duke përdorur Uniform State Diffusion , modeli zëvendëson tekstin me zhurmë të rastësishme të fjalorit dhe e përpunon në mënyrë iterative të gjithë kanavacën paralelisht. Ai përdor një Gemma 4 26B A4B të akorduar imët për të mbështetur detyrat e ndryshme të heqjes së zhurmës dhe kodimit. Kornizat e përparuara si vetëkushtëzimi, marrja e mostrave në bllok me shumë kanavacë i lejojnë modelit të korrigjojë dinamikisht gabimet, të trajtojë gjenerimin e formave të gjata dhe të arrijë vonesë ultra të ulët për një përdorues të vetëm.