
アプリケーションに生成 AI を追加すると、驚異的なパワーと価値をアプリケーションに とはいえ、ユーザーの安全とプライバシーを 提供します。
安全性を重視した設計
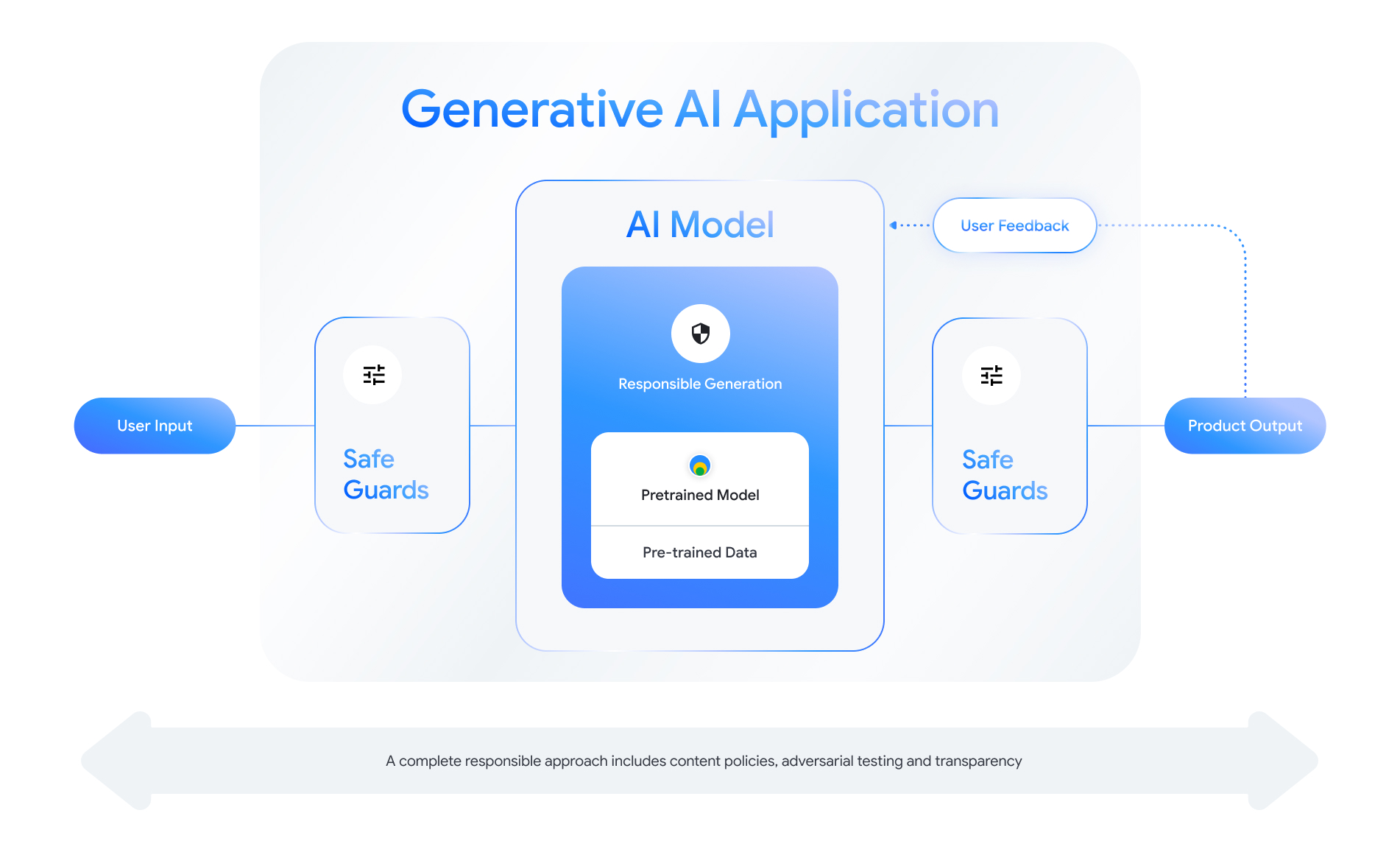
生成 AI 対応の各機能には、安全性のレイヤを設計するための機会があります。として 次の図に示すように、安全性について考える一つの方法として、 この機能を中心とした AI モデルです。このモデルは次のようにする必要があります。
- 割り当てられたタスクを実施するために連携している。
- 安全保護対策によって保護されており、境界外の通行を 入力と出力が拒否されます。および
- 全体的に評価して、モデルとリソースがどのように 安全に影響するやり取りにシステムが対応します。
詳しくは、 「責任ある AI プロダクトの作成」セッション Google I/O 2024 に参加して、デザイン上の考慮事項、思考演習、 責任ある開発を加速させるのに役立つ 学びました。
また、以下のベスト プラクティスと例もご確認いただけます。
- AI がどのように動作するかを規定するポリシーを定義 アプリケーションを
- コミュニケーションのための透明性のアーティファクトを作成する ユーザーに対する責任あるアプローチおよび
- 不正使用からアプリケーションを保護する。
何よりも重要なのは、安全と責任に対する健全なアプローチが 技術、文化、プロセスに適応し、自己分析に適応できる 学びました。自分自身とチームと連携して、 ベストプラクティスを実践します
システムレベルのポリシーを定義する
コンテンツの安全性に関するポリシーは、どのような種類の有害なコンテンツを禁止するかを定めています 支援します各プラットフォームのコンテンツ ポリシーについてはご存じかもしれません (YouTube、Google Play など)。目次 よく似ています。つまり、生成 AI アプリケーションでは、 アプリケーションで生成してはならないコンテンツであり、モデルのチューニング方法の指針となる 適切な安全保護対策を追加できます
ポリシーはアプリケーションのユースケースを反映する必要があります。たとえば、 以下に基づいたファミリー活動のアイデアの提供を目的とした生成 AI プロダクトです。 コミュニティの提案には、コンテンツの生成を禁止するポリシーが ユーザーに害を及ぼす可能性があるため、暴力的な性質を持つコンテンツ。逆に ユーザーが提案した SF 小説のアイデアを要約するアプリケーションは、 暴力シーンは数多く出てくるので、それを許容したいと このジャンルを選択します。
有害なコンテンツの生成を安全ポリシーで禁止する必要があります また、どのような種類のコンテンツがそれを満たすのかを アプリの基準となっていますまた、 ただし、次のような、教育、ドキュメンタリー、科学、芸術の文脈で投稿されたコンテンツは例外となります。 有害と見なされる可能性があります。
次のような、非常に詳細なレベルで明確なポリシーを定義する。 例を挙げてポリシーに対する例外を設けることは、責任ある AI を 説明します。ポリシーは、モデル開発の各ステップで使用されます。データ 精度が低いと、データの誤ったラベル付け、過剰な削除、 モデルの安全性レスポンスに影響を及ぼします対象 定義が明確でないと、評価間の関係が悪くなり、 モデルが安全性を満たしているかどうかの判断が難しくなる 対応できます。
架空のポリシー(説明のみ)
以下は、 ユースケースに合わせて調整できます。
| ポリシーのカテゴリ | ポリシー |
|---|---|
| 個人を特定できる機密情報(SPII) | アプリケーションでは、個人を特定できる機密情報を 個人情報(例: メールアドレス、クレジット カード番号、 個人の社会保障番号など)。 |
| ヘイトスピーチ | 否定的または有害なコンテンツがアプリケーションで生成されない ターゲティング ID や保護対象属性(人種差別、 差別の助長、保護対象となっている組織に対する暴力の呼びかけ できます。 |
| 嫌がらせ | このアプリケーションは、悪意のある、脅迫、いじめ、 個人を対象とした不適切なコンテンツ( 不幸な出来事の否認、被害者の中傷 暴力を含む)。 |
| 危険なコンテンツ | 有害なコンテンツに関する手順やアドバイスは生成されません。 (例: 銃器の改造や製造など)に 爆発物装置, テロリズムの助長, 自殺など) |
| 露骨な性表現 | このアプリケーションでは、 性行為などのわいせつなコンテンツ(例: 露骨な性表現を含む) 性的興奮を引き起こすことを目的としたコンテンツなど)に分類されるコンテンツ。 |
| 有害な商品やサービスへのアクセスを可能にする | 本アプリケーションでは、以下を助長または実現するコンテンツを生成しません。 有害な可能性のある商品、サービス、アクティビティ( ギャンブル、医薬品、 花火、性的サービス) |
| 悪意のあるコンテンツ | アプリケーションでは、不正な行為を行う命令は生成されません。 (例: フィッシング詐欺、スパム、フィッシング メール、 大量勧誘を目的としたコンテンツ、脱獄方法など)。 |
透明性のアーティファクト
ドキュメントは、デベロッパーにとって透明性を実現する重要な手段です。 政府、政策アクター、プロダクトのエンドユーザーです。これには、 詳細な技術レポートやモデル、データ、システムカードをリリースし、 安全性などのモデルに基づき、必要不可欠な情報を適切に公開 評価を行います透明性のアーティファクトは通信手段にとどまらない また、AI 研究者、デプロイ担当者、ダウンストリームの開発者向けに、 責任を持って行うことが重要です。この情報は、 モデルの詳細を理解したいと考える お客様もいるからです
考慮すべき透明性に関するガイドライン:
- ユーザーが試験運用版を使っていることを明示する 生成 AI テクノロジーを紹介し、予想外のモデルの可能性を強調 確認します。
- 生成 AI のサービスやプロダクトがどのように 理解しやすい言葉で機能します体系的に公開することを検討する モデルカードなどの透明性アーティファクトが含まれます。これらのカードには モデルの使用目的を理解し、モデルに与えられた評価を 重要な役割を果たします
- フィードバックの提供方法や、フィードバックのコントロール方法について示します。
例:
<ph type="x-smartling-placeholder">
- </ph>
- ユーザーが事実に基づく質問を検証できる仕組みを提供する
- ユーザー フィードバック用の高評価 / 低評価アイコン
- 問題を報告し、迅速に対応するためのサポートを提供するリンク ユーザー フィードバック
- ユーザー アクティビティを保存、削除するユーザー コントロール
安全な AI システム
生成 AI 対応アプリケーションは複雑な攻撃対象領域を提示 従来のアプリケーションよりも多様な緩和策が必要です。 Google のセキュア AI フレームワーク(SAIF)は、 生成 AI 対応アプリケーションの設計方法を検討するための概念フレームワーク セキュリティを確保できます。このフレームワークは、クラウド コンピューティング モデルと アライメント、敵対的評価、 効果的にセーフガードを組み込んで、アプリケーションを安全に保護します。 ただし、これらは出発点にすぎないことを覚えておいてください。追加の変更 組織の実践方法、モニタリング、アラートを、組織の実践方法、 セキュリティ目標を達成できます
デベロッパー向けリソース
生成 AI のポリシーの例:
- Cloud Gemini API と PaLM API は、 安全性構築の基礎となる安全性属性のリスト あります。
- 2023 年 Google AI に関する原則の進捗状況に関する最新情報。
- MLCommons Association(ML 協会)は、 AI システムを改善するためのオープンなコラボレーションの理念(参考文献 6) AI の安全性に基づいてモデルを評価する際の AI 安全性ベンチマーク。
透明性のアーティファクトのための単一のテンプレートは、 既存のモデルカードを出発点として活用できる 独自に作成するには:
- Gemma のモデルカード
- 元のモデルカード用紙のモデルカード テンプレート
- Google Cloud APIs のモデルカード