Imagen 是 Google 的高保真圖像生成模型,可根據文字提示生成逼真且高品質的圖像。所有生成的圖像都會加上 SynthID 浮水印。如要進一步瞭解可用的 Imagen 模型變體,請參閱「模型版本」一節。
使用 Imagen 模型生成圖像
以下範例說明如何使用 Imagen 模型生成圖片:
Python
from google import genai
from google.genai import types
from PIL import Image
from io import BytesIO
client = genai.Client()
response = client.models.generate_images(
model='imagen-4.0-generate-001',
prompt='Robot holding a red skateboard',
config=types.GenerateImagesConfig(
number_of_images= 4,
)
)
for generated_image in response.generated_images:
generated_image.image.show()
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
async function main() {
const ai = new GoogleGenAI({});
const response = await ai.models.generateImages({
model: 'imagen-4.0-generate-001',
prompt: 'Robot holding a red skateboard',
config: {
numberOfImages: 4,
},
});
let idx = 1;
for (const generatedImage of response.generatedImages) {
let imgBytes = generatedImage.image.imageBytes;
const buffer = Buffer.from(imgBytes, "base64");
fs.writeFileSync(`imagen-${idx}.png`, buffer);
idx++;
}
}
main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
config := &genai.GenerateImagesConfig{
NumberOfImages: 4,
}
response, _ := client.Models.GenerateImages(
ctx,
"imagen-4.0-generate-001",
"Robot holding a red skateboard",
config,
)
for n, image := range response.GeneratedImages {
fname := fmt.Sprintf("imagen-%d.png", n)
_ = os.WriteFile(fname, image.Image.ImageBytes, 0644)
}
}
REST
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/models/imagen-4.0-generate-001:predict" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"prompt": "Robot holding a red skateboard"
}
],
"parameters": {
"sampleCount": 4
}
}'

Imagen 設定
Imagen 目前僅支援英文提示詞和下列參數:
numberOfImages:要生成的圖片數量,範圍為 1 到 4 (含 1 和 4)。預設值為 4。imageSize:生成圖像的大小。這項功能僅適用於標準和 Ultra 模型。支援的值為1K和2K。 預設值為1K。aspectRatio:變更生成的圖像的顯示比例。支援的值為"1:1"、"3:4"、"4:3"、"9:16"和"16:9"。預設值為"1:1"。personGeneration:允許模型生成人物圖像。支援的值如下:"dont_allow":禁止生成人物圖像。"allow_adult":生成成人圖片,但不能生成兒童圖片。此為預設值。"allow_all":生成包含成人和兒童的圖片。
Imagen 提示指南
本節的 Imagen 指南將說明如何修改文字轉圖片提示,產生不同的結果,並提供可建立的圖片範例。
提示撰寫基礎知識
好的提示應具備描述性且清楚明瞭,並使用有意義的關鍵字和修飾符。首先,請思考主題、脈絡和風格。

主題:在任何提示中,首先要考慮的是主題,也就是您想生成圖片的物件、人物、動物或風景。
背景資訊:背景或情境與主體同樣重要,嘗試將拍攝主體放在各種背景中。例如白色背景的攝影棚、戶外或室內環境。
風格:最後,新增想要的圖片風格。風格可以是廣泛的類型 (繪畫、攝影、素描),也可以是非常具體的類型 (粉彩畫、炭筆畫、等距 3D)。你也可以合併樣式。
撰寫提示詞的第一個版本後,請加入更多詳細資料來修正提示詞,直到生成想要的圖像為止。反覆運算很重要。 首先請確立核心概念,然後不斷修正和擴展這個概念,直到生成的圖片接近您的想像。

|

|

|
無論提示簡短或詳盡,Imagen 模型都能將你的想法轉化為細緻的圖像。透過反覆提示,加入詳細資料,直到獲得完美結果為止。
|
簡短提示可快速生成圖像。 
|
提示越長,就能新增更多詳細資料,打造出理想的圖片。 
|
撰寫 Imagen 提示的其他建議:
- 使用描述性語言:使用詳細的形容詞和副詞,為 Imagen 描繪清晰的圖像。
- 提供背景資訊:視需要提供背景資訊,協助 AI 瞭解內容。
- 參考特定藝術家或風格:如果你有特定美學概念,參考特定藝術家或藝術運動會很有幫助。
- 使用提示工程工具:考慮探索提示工程工具或資源,協助您修正提示並獲得最佳結果。
- 強化個人和團體相片中的臉部細節:將臉部細節指定為相片的焦點 (例如在提示中使用「肖像」一詞)。
生成圖片中的文字
Imagen 模型可以在圖片中加入文字,開創更多創意圖像生成可能性。請參閱下列指引,充分運用這項功能:
- 放心疊代:您可能需要重新生成圖片,直到達到想要的樣貌為止。Imagen 的文字整合功能仍在發展中,有時多試幾次才能獲得最佳結果。
- 簡短扼要:文字長度應限制在 25 個字元以內,才能獲得最佳生成結果。
多個詞組:嘗試使用兩到三個不同的詞組,提供額外資訊。為求簡潔,請避免使用超過三個片語。

提示:海報,標題為粗體字「Summerland」,下方是宣傳標語「Summer never felt so good」 文字位置:Imagen 會盡量按照指示放置文字,但偶爾會出現變化。這項功能會持續改善。
字型樣式:指定一般字型樣式,以微妙的方式影響 Imagen 的選擇。請勿期待完全複製字型,但可期待創意詮釋。
字型大小:指定字型大小或一般大小 (例如小、中、大),影響字型大小的生成結果。
提示參數化
如要進一步控制輸出結果,建議將輸入內容參數化至 Imagen。舉例來說,假設您希望顧客能為自己的商家生成標誌,並確保標誌一律以純色背景生成,您也想限制用戶端可從選單中選取的選項。
在本範例中,您可以建立類似下列內容的參數化提示:
A {logo_style} logo for a {company_area} company on a solid color background. Include the text {company_name}.在自訂使用者介面中,顧客可以使用選單輸入參數,而他們選擇的值會填入 Imagen 收到的提示。
例如:
提示:
A minimalist logo for a health care company on a solid color background. Include the text Journey.
提示:
A modern logo for a software company on a solid color background. Include the text Silo.
提示:
A traditional logo for a baking company on a solid color background. Include the text Seed.
進階提示詞撰寫技巧
根據攝影描述符、形狀和材質、歷史藝術運動和圖像品質修飾符等屬性,使用下列範例建立更具體的提示。
攝影
- 提示包含:「一張...的相片」
如要使用這種風格,請先使用清楚告知 Imagen 你要尋找相片的關鍵字。提示開頭為「一張<某某事物>的相片。。。"。例如:

|

|

|
圖片來源:每張圖片都是使用 Imagen 4 模型,根據對應的文字提示生成。
攝影修飾符
在下列範例中,您可以看到幾個攝影專屬的修飾符和參數。您可以組合多個修飾符,以便更精確地控制。
相機距離 - 特寫,從遠處拍攝

提示:咖啡豆的特寫相片 
提示:一張縮小的相片,內容是凌亂廚房中的一小袋咖啡豆 攝影機位置 - 空拍、由下往上拍

提示:高樓林立的城市空照圖 
提示:一張森林樹冠的照片,從下方拍攝,背景是藍天 光線 - 自然、戲劇性、暖色、冷色

提示:現代扶手椅的攝影棚照片,自然光 
提示:現代扶手椅的攝影棚照片,戲劇性燈光 相機設定 - 動作模糊、柔焦、散景、人像

提示:從車內拍攝城市照片,要有摩天大樓和動態模糊 
提示:夜晚城市中橋梁的柔焦相片 鏡頭類型 - 35 公釐、50 公釐、魚眼、廣角、微距

提示:葉子的相片,微距鏡頭 
提示:街頭攝影、紐約市、魚眼鏡頭 底片類型 - 黑白、拍立得

提示:戴著太陽眼鏡的小狗的拍立得肖像照 
提示:戴太陽眼鏡的狗的黑白照片
圖片來源:每張圖片都是使用 Imagen 4 模型,根據對應的文字提示生成。
插畫和藝術
- 提示包含:「painting 的...」、「A sketch of...」
藝術風格從鉛筆素描等單色風格,到超寫實數位藝術都有。舉例來說,下列圖片使用相同提示,但風格不同:
「背景為摩天大樓的運動風電動斜背轎車」[art style or creation technique]

|

|

|

|

|

|
圖片來源:每張圖片都是使用 Imagen 2 模型,根據對應的文字提示生成。
形狀和材質
- 提示包含:「...由...製成」、「...形狀...」
這項技術的優勢之一,就是能製作出原本難以或無法實現的圖像。舉例來說,你可以用不同材質和紋理重新製作公司標誌。

|

|

|
圖片來源:每張圖片都是使用 Imagen 4 模型,根據對應的文字提示生成。
歷史藝術參考資料
- 提示包含:「...的風格」
多年來,某些風格已成為經典。以下提供一些歷史繪畫或藝術風格的構想,供您參考。
「以[art period or movement] 的風格生成風力發電廠的圖片」

|

|

|
圖片來源:每張圖片都是使用 Imagen 4 模型,根據對應的文字提示生成。
圖片品質修飾符
某些關鍵字可讓模型瞭解您要尋找高品質素材資源。品質修飾符的範例如下:
- 一般修飾符 - 高品質、美麗、風格化
- 相片 - 4K、HDR、攝影棚相片
- 藝術、插畫 - 由專業人士繪製,細緻
以下列舉幾個範例,說明有/沒有品質修飾符的提示。

|

photo of a corn stalk taken by a professional photographer |
圖片來源:每張圖片都是使用 Imagen 4 模型,根據對應的文字提示生成。
顯示比例
Imagen 圖像生成功能可讓你設定五種不同的圖像顯示比例。
- 正方形 (1:1,預設) - 標準正方形相片。這個長寬比的常見用途包括社群媒體貼文。
全螢幕 (4:3) - 這種顯示比例常見於媒體或電影。 這也是大多數舊型 (非寬螢幕) 電視和中片幅相機的尺寸。與 1:1 相比,16:9 可橫向捕捉更多場景, 因此是攝影的首選長寬比。

提示:音樂家彈奏鋼琴的手指特寫、黑白電影、復古 (4:3 長寬比) 
提示:為高級餐廳拍攝的薯條專業棚內照片,風格類似美食雜誌 (4:3 長寬比) 直向全螢幕 (3:4):這是旋轉 90 度的全螢幕顯示比例。與 1:1 顯示比例相比,這項功能可垂直擷取更多場景。

提示:一名女性在健行,水窪中映照出她的靴子,背景是高山,廣告風格,戲劇性角度 (3:4 長寬比) 
提示:空拍圖,一條河流流經神秘山谷 (顯示比例 3:4) 寬螢幕 (16:9) - 這個比例已取代 4:3,現在是電視、螢幕和手機螢幕 (橫向) 最常見的顯示比例。如要拍攝更多背景 (例如風景),請使用這個顯示比例。

提示:一名男子穿著全白服裝坐在海灘上,特寫鏡頭,黃金時刻光線 (顯示比例 16:9) 直向 (9:16):這個比例是寬螢幕,但經過旋轉。這是相對較新的長寬比,因短片應用程式 (例如 YouTube Shorts) 而廣為人知。適用於高聳的物件,例如建築物、樹木、瀑布或其他類似物件。

提示:以數位方式繪製一棟宏偉的現代摩天大樓,背景是美麗的日落 (顯示比例 9:16)
逼真圖像
不同版本的圖像生成模型可能會提供藝術風格和寫實風格的輸出內容。在提示中使用下列字詞,根據要生成的主題,生成更擬真的輸出內容。
| 用途 | 鏡頭類型 | 焦距 | 其他詳細資訊 |
|---|---|---|---|
| 人物 (肖像) | Prime、Zoom | 24-35mm | 黑白電影、黑色電影、景深、雙色調 (提及兩種顏色) |
| 食物、昆蟲、植物 (物體、靜物) | 巨集 | 60-105mm | 細節豐富、精準對焦、光線受控 |
| 運動、野生動物 (動作) | 望遠變焦 | 100-400mm | 快門速度快、追蹤動作或移動 |
| 天文、風景 (廣角) | 廣角 | 10-24mm | 長時間曝光、清晰對焦、長時間曝光、平滑的水面或雲朵 |
人像
| 用途 | 鏡頭類型 | 焦距 | 其他詳細資訊 |
|---|---|---|---|
| 人物 (肖像) | Prime、Zoom | 24-35mm | 黑白電影、黑色電影、景深、雙色調 (提及兩種顏色) |
Imagen 可使用表格中的多個關鍵字,生成下列肖像:

|

|

|

|
提示:一位女性,35 公釐肖像,藍色和灰色雙色調
模型:imagen-4.0-generate-001

|

|

|

|
提示詞:A woman, 35mm portrait, film noir
模型:imagen-4.0-generate-001
物件
| 用途 | 鏡頭類型 | 焦距 | 其他詳細資訊 |
|---|---|---|---|
| 食物、昆蟲、植物 (物體、靜物) | 巨集 | 60-105mm | 細節豐富、精準對焦、光線受控 |
使用表格中的幾個關鍵字,Imagen 可以生成下列物件圖片:

|

|

|

|
提示:leaf of a prayer plant, macro lens, 60mm
模型:imagen-4.0-generate-001

|

|

|

|
提示:一盤義大利麵,100 公釐微距鏡頭
模型:imagen-4.0-generate-001
動作
| 用途 | 鏡頭類型 | 焦距 | 其他詳細資訊 |
|---|---|---|---|
| 運動、野生動物 (動作) | 望遠變焦 | 100-400mm | 快門速度快、追蹤動作或移動 |
使用表格中的幾個關鍵字,Imagen 可以生成下列動態圖片:

|

|
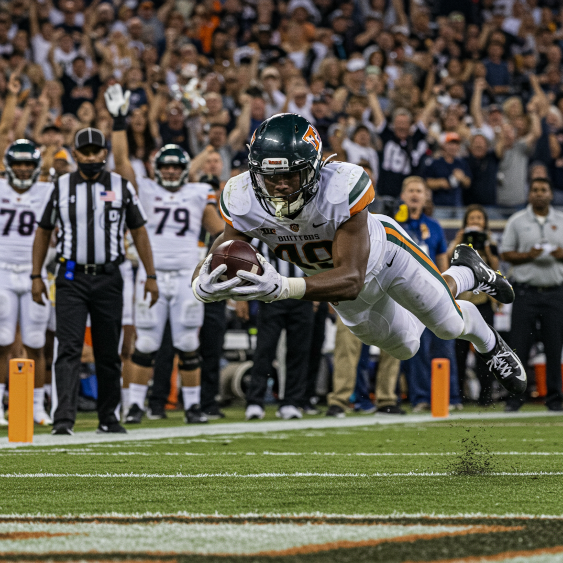
|

|
提示:接球達陣,快速快門速度,動作追蹤
模型:imagen-4.0-generate-001

|

|

|

|
提示:森林中奔跑的鹿,快門速度快,動作追蹤
模型:imagen-4.0-generate-001
廣角
| 用途 | 鏡頭類型 | 焦距 | 其他詳細資訊 |
|---|---|---|---|
| 天文、風景 (廣角) | 廣角 | 10-24mm | 長時間曝光、清晰對焦、長時間曝光、平滑的水面或雲朵 |
使用表格中的幾個關鍵字,Imagen 可以生成下列廣角圖像:

|

|

|

|
提示:an expansive mountain range, landscape wide angle 10mm
模型:imagen-4.0-generate-001

|

|

|

|
提示:月亮相片,天文攝影,10 公釐廣角
模型:imagen-4.0-generate-001