Narzędzie Computer Use umożliwia tworzenie agentów sterujących przeglądarką, komórką i komputerem, którzy wchodzą w interakcje z użytkownikiem i automatyzują zadania. Na podstawie zrzutów ekranu model może „widzieć” ekran komputera i „działać”, generując określone działania interfejsu, takie jak kliknięcia myszą i wpisywanie z klawiatury. Podobnie jak w przypadku wywoływania funkcji musisz wdrożyć środowisko wykonawcze po stronie klienta, aby otrzymywać i wykonywać działania związane z korzystaniem z komputera.
Gemini 3.5 Flash to zalecany model do użytku na komputerze. Wprowadzamy w nim kilka nowych funkcji:
- Obsługa wielu środowisk: twórz agentów dla środowisk przeglądarki, urządzeń mobilnych i komputerów.
- Uproszczone działania z intencjami: działania zawierają pole
intent, które wyjaśnia rozumowanie modelu dla każdego kroku. - Konfigurowalne zasady bezpieczeństwa: dostosuj zachowanie związane z bezpieczeństwem za pomocą wbudowanych kategorii zasad i zastąpień.
- Wykrywanie wstrzykiwania promptów: włącz skanowanie zrzutów ekranu, aby wykrywać ukryte instrukcje, które mogą być wykorzystywane do ataków.
Za pomocą narzędzia Computer Use możesz tworzyć agentów, którzy:
- automatyzować powtarzające się wprowadzanie danych lub wypełnianie formularzy w witrynach;
- przeprowadzać automatyczne testy aplikacji internetowych i ścieżek użytkowników,
- prowadzić wyszukiwanie w różnych witrynach (np. zbierać informacje o produktach, cenach i opiniach w witrynach e-commerce, aby podjąć decyzję o zakupie);
Oto minimalny przykład inicjowania klienta i wysyłania prompta do modelu z narzędziem computer_use włączonym w środowisku przeglądarki:
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Search for 'Gemini API' on Google.",
tools=[{"type": "computer_use", "environment": "browser"}]
)
print(interaction)
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
const interaction = await ai.interactions.create({
model: 'gemini-3.5-flash',
input: "Search for 'Gemini API' on Google.",
tools: [{ type: "computer_use", environment: "browser" }]
});
console.log(interaction);
Jak działa korzystanie z komputera
Aby utworzyć agenta z modelem Computer Use, musisz skonfigurować ciągłą pętlę między aplikacją a interfejsem API. Oto, co Twój kod będzie robić na każdym etapie:
- Wysyłanie żądania do modelu
- Aplikacja wysyła żądanie do interfejsu API zawierające narzędzie Computer Use, ustawienia konfiguracji (np. środowisko docelowe), prompt użytkownika i zrzut ekranu.
- Otrzymywanie odpowiedzi modelu
- Model analizuje ekran i prompt, a następnie zwraca odpowiedź, która zawiera sugerowany
function_callreprezentujący działanie w interfejsie (np. kliknięcie, przewinięcie lub naciśnięcie klawisza). - W przypadku Gemini 3.5 Flash odpowiedź zawiera też uzasadnienie
intent, które wyjaśnia, dlaczego model wybrał to działanie. - W przypadku starszych modeli (np.
gemini-2.5-computer-use-preview-10-2025) odpowiedź może zawieraćsafety_decisionz wewnętrznego systemu bezpieczeństwa, który klasyfikuje działanie jako zwykłe/dozwolone,require_confirmation(wymagające zatwierdzenia przez użytkownika) lub zablokowane.
- Model analizuje ekran i prompt, a następnie zwraca odpowiedź, która zawiera sugerowany
- Wykonaj otrzymane działanie
- Jeśli działanie jest dozwolone (lub użytkownik je potwierdzi), kod po stronie klienta analizuje
function_call, skaluje znormalizowane współrzędne, aby dopasować je do widocznego obszaru, i wykonuje działanie w środowisku docelowym za pomocą narzędzi do automatyzacji (takich jak Playwright). Jeśli działanie jest zablokowane, klient powinien wstrzymać wykonanie lub obsłużyć przerwanie.
- Jeśli działanie jest dozwolone (lub użytkownik je potwierdzi), kod po stronie klienta analizuje
- Zapisz stan nowego środowiska
- Po wykonaniu działania aplikacja robi nowy zrzut ekranu i wysyła go z powrotem do modelu w
function_result, aby poprosić o wykonanie następnego kroku.
- Po wykonaniu działania aplikacja robi nowy zrzut ekranu i wysyła go z powrotem do modelu w
Proces ten powtarza się od kroku 2, stale prosząc model o wykonanie kolejnej czynności, dopóki zadanie nie zostanie ukończone lub przerwane.
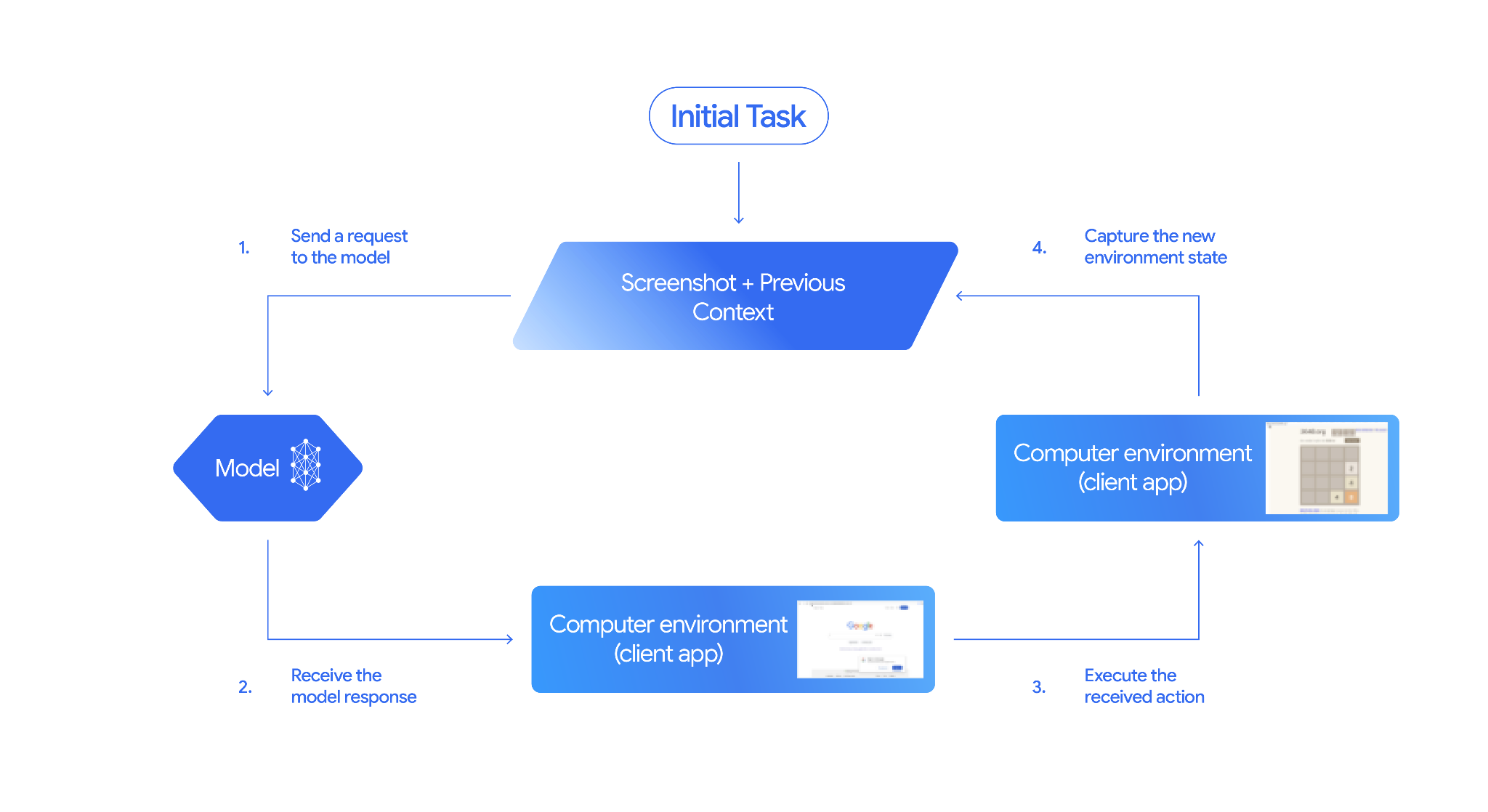
Jak wdrożyć korzystanie z komputera
Zanim zaczniesz korzystać z narzędzia do używania komputera, musisz skonfigurować:
- Bezpieczne środowisko wykonawcze: uruchamiaj agenta w piaskownicy w maszynie wirtualnej lub kontenerze, aby odizolować go od systemu hosta i ograniczyć jego potencjalny wpływ. Implementacja referencyjna zawiera gotową do użycia piaskownicę opartą na Dockerze, której możesz użyć jako punktu początkowego.
- Obsługa działań po stronie klienta: wdróż logikę po stronie klienta, aby wykonywać działania związane z współrzędnymi, wpisywać tekst i robić zrzuty ekranu.
W przykładach poniżej jako środowiska wykonawczego używamy przeglądarki internetowej, a jako modułu obsługi po stronie klienta – Playwright.
0. Konfigurowanie Playwright
Najpierw zainstaluj wymagane pakiety:
pip install google-genai playwright
playwright install chromium
Następnie zainicjuj instancję przeglądarki Playwright, która będzie używana do wykonywania:
from playwright.sync_api import sync_playwright
# 1. Configure screen dimensions for the target environment
SCREEN_WIDTH = 1440
SCREEN_HEIGHT = 900
# 2. Start the Playwright browser
# In production, utilize a sandboxed environment.
playwright = sync_playwright().start()
# Set headless=False to see the actions performed on your screen
browser = playwright.chromium.launch(headless=False)
# 3. Create a context and page with the specified dimensions
context = browser.new_context(
viewport={"width": SCREEN_WIDTH, "height": SCREEN_HEIGHT}
)
page = context.new_page()
# 4. Navigate to an initial page to start the task
page.goto("https://www.google.com")
# The 'page', 'SCREEN_WIDTH', and 'SCREEN_HEIGHT' variables
# will be used in the steps below.
1. Wysyłanie żądania do modelu
Zainicjuj bibliotekę klienta i skonfiguruj narzędzie Computer Use. Pamiętaj, że podczas wysyłania żądania nie musisz określać rozmiaru wyświetlacza. Model przewiduje współrzędne pikseli przeskalowane do wysokości i szerokości ekranu.
Gemini 3.5 Flash (zalecany)
Python
Użyj google-genaipakietu SDK Pythona (w wersji 2.7.0 lub nowszej), aby skonfigurować żądanie kierowane na środowisko przeglądarki:
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model='gemini-3.5-flash',
input="Find a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th",
tools=[
{
"type": "computer_use",
"environment": "browser",
"enable_prompt_injection_detection": True
}
]
)
print(interaction)
JavaScript
Użyj pakietu @google/genai Node.js SDK, aby skonfigurować żądanie kierowane na środowisko przeglądarki:
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
const interaction = await ai.interactions.create({
model: 'gemini-3.5-flash',
input: "Find a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th",
tools: [
{
type: "computer_use",
environment: "browser",
enable_prompt_injection_detection: true
}
]
});
console.log(interaction);
REST
Aby wysłać żądanie, użyj polecenia curl:
curl -X POST \
"https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-3.5-flash",
"input": "Find me a flight from SF to Hawaii on Jun 30th, coming back on Jul 6th. Start by navigating directly to flights.google.com",
"tools": [
{
"type": "computer_use",
"environment": "browser",
"enable_prompt_injection_detection": true
}
]
}'
Gemini 2.5 (starsza wersja)
Python
from google import genai
client = genai.Client()
# Specify predefined functions to exclude (optional)
excluded_functions = ["drag_and_drop"]
interaction = client.interactions.create(
model='gemini-2.5-computer-use-preview-10-2025',
input="Search for highly rated smart fridges on Google Shopping.",
tools=[
{
"type": "computer_use",
"environment": "browser",
"excluded_predefined_functions": excluded_functions
}
]
)
print(interaction)
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
// Specify predefined functions to exclude (optional)
const excludedFunctions = ["drag_and_drop"];
const interaction = await ai.interactions.create({
model: 'gemini-2.5-computer-use-preview-10-2025',
input: "Search for highly rated smart fridges on Google Shopping.",
tools: [
{
type: "computer_use",
environment: "browser",
excluded_predefined_functions: excludedFunctions
}
]
});
console.log(interaction);
2. Otrzymywanie odpowiedzi modelu
Model odpowiedzi sugeruje wywołanie funkcji. W przypadku Gemini 3.5 Flash odpowiedź zawiera dostosowany zamiar rozumowania wraz z współrzędnymi. Poniżej znajdziesz przykłady obu odpowiedzi:
Gemini 3.5 Flash
{
"steps": [
{
"type": "function_call",
"name": "click",
"arguments": {
"x": 450,
"y": 120,
"intent": "Click the search box to type the destination."
}
}
]
}
Gemini 2.5 (starsza wersja)
{
"steps": [
{
"type": "model_output",
"content": [
{
"type": "text",
"text": "I will type the search query into the search bar."
}
]
},
{
"type": "function_call",
"name": "type_text_at",
"arguments": {
"x": 371,
"y": 470,
"text": "highly rated smart fridges",
"press_enter": true
}
}
]
}
3. wykonywać otrzymane działania,
Aplikacja musi przeanalizować współrzędne odpowiedzi, wykonać działanie i skalować je ze znormalizowanych współrzędnych 1000 x 1000.
Poniższy kod obsługuje zarówno starsze polecenia narzędzi (click_at, type_text_at), jak i uproszczone polecenia Gemini 3.5 Flash (click, type).
Python
from typing import Any, List, Tuple
import time
def denormalize_x(x: int, screen_width: int) -> int:
"""Convert normalized x coordinate (0-1000) to actual pixel coordinate."""
return int(x / 1000 * screen_width)
def denormalize_y(y: int, screen_height: int) -> int:
"""Convert normalized y coordinate (0-1000) to actual pixel coordinate."""
return int(y / 1000 * screen_height)
def execute_function_calls(interaction, page, screen_width, screen_height):
results = []
function_calls = [
step for step in interaction.steps if step.type == "function_call"
]
for function_call in function_calls:
action_result = {}
fname = function_call.name
args = function_call.arguments
print(f" -> Executing: {fname} (Intent: {args.get('intent', 'N/A')})")
try:
if fname in ("open_web_browser", "open_app"):
pass # Handled / already open
elif fname in ("click", "click_at", "double_click", "triple_click", "middle_click", "right_click", "move", "long_press"):
actual_x = denormalize_x(args["x"], screen_width)
actual_y = denormalize_y(args["y"], screen_height)
if fname in ("click", "click_at"):
page.mouse.click(actual_x, actual_y)
elif fname == "double_click":
page.mouse.dblclick(actual_x, actual_y)
elif fname == "right_click":
page.mouse.click(actual_x, actual_y, button="right")
elif fname == "middle_click":
page.mouse.click(actual_x, actual_y, button="middle")
elif fname == "move":
page.mouse.move(actual_x, actual_y)
elif fname in ("type", "type_text_at"):
actual_x = denormalize_x(args["x"], screen_width) if "x" in args else None
actual_y = denormalize_y(args["y"], screen_height) if "y" in args else None
text = args["text"]
press_enter = args.get("press_enter", False)
if actual_x is not None and actual_y is not None:
page.mouse.click(actual_x, actual_y)
# Clear field first
page.keyboard.press("Meta+A")
page.keyboard.press("Backspace")
page.keyboard.type(text)
if press_enter:
page.keyboard.press("Enter")
elif fname == "navigate":
page.goto(args["url"])
elif fname == "go_back":
page.go_back()
elif fname == "go_forward":
page.go_forward()
elif fname == "wait":
time.sleep(args.get("seconds", 1))
else:
print(f"Warning: Custom or unhandled function {fname}")
page.wait_for_load_state(timeout=5000)
time.sleep(1)
except Exception as e:
print(f"Error executing {fname}: {e}")
action_result = {"error": str(e)}
results.append((fname, function_call.id, action_result))
return results
JavaScript
function denormalizeX(x, screenWidth) {
// Convert normalized x coordinate (0-1000) to actual pixel coordinate.
return Math.floor((x / 1000) * screenWidth);
}
function denormalizeY(y, screenHeight) {
// Convert normalized y coordinate (0-1000) to actual pixel coordinate.
return Math.floor((y / 1000) * screenHeight);
}
async function executeFunctionCalls(interaction, page, screenWidth, screenHeight) {
const results = [];
const functionCalls = interaction.steps.filter(step => step.type === "function_call");
for (const functionCall of functionCalls) {
const actionResult = {};
const fname = functionCall.name;
const args = functionCall.arguments;
console.log(` -> Executing: ${fname} (Intent: ${args.intent || 'N/A'})`);
try {
if (fname === "open_web_browser" || fname === "open_app") {
// Handled / already open
} else if (["click", "click_at", "double_click", "triple_click", "middle_click", "right_click", "move", "long_press"].includes(fname)) {
const actualX = denormalizeX(args.x, screenWidth);
const actualY = denormalizeY(args.y, screenHeight);
if (fname === "click" || fname === "click_at") {
await page.mouse.click(actualX, actualY);
} else if (fname === "double_click") {
await page.mouse.dblclick(actualX, actualY);
} else if (fname === "right_click") {
await page.mouse.click(actualX, actualY, { button: "right" });
} else if (fname === "middle_click") {
await page.mouse.click(actualX, actualY, { button: "middle" });
} else if (fname === "move") {
await page.mouse.move(actualX, actualY);
}
} else if (fname === "type" || fname === "type_text_at") {
const actualX = args.x !== undefined ? denormalizeX(args.x, screenWidth) : null;
const actualY = args.y !== undefined ? denormalizeY(args.y, screenHeight) : null;
const text = args.text;
const pressEnter = args.press_enter || false;
if (actualX !== null && actualY !== null) {
await page.mouse.click(actualX, actualY);
}
// Clear field first
await page.keyboard.press("Meta+A");
await page.keyboard.press("Backspace");
await page.keyboard.type(text);
if (pressEnter) {
await page.keyboard.press("Enter");
}
} else if (fname === "navigate") {
await page.goto(args.url);
} else if (fname === "go_back") {
await page.goBack();
} else if (fname === "go_forward") {
await page.goForward();
} else if (fname === "wait") {
await new Promise(resolve => setTimeout(resolve, (args.seconds || 1) * 1000));
} else {
console.log(`Warning: Custom or unhandled function ${fname}`);
}
await page.waitForLoadState('load', { timeout: 5000 }).catch(() => {});
await new Promise(resolve => setTimeout(resolve, 1000));
} catch (e) {
console.log(`Error executing ${fname}: ${e}`);
actionResult.error = e.message;
}
results.push([fname, functionCall.id, actionResult]);
}
return results;
}
4. Przechwytywanie nowego stanu środowiska
Po wykonaniu działań wyślij wynik wykonania funkcji z powrotem do modelu, aby mógł on wykorzystać te informacje do wygenerowania następnego działania. Jeśli wykonano kilka działań (równoległych wywołań), w kolejnej turze użytkownika musisz wysłać function_result dla każdego z nich.
Python
import json
import base64
def get_function_responses(page, results):
screenshot_bytes = page.screenshot(type="png")
current_url = page.url
function_responses = []
for name, call_id, result in results:
function_responses.append({
"type": "function_result",
"name": name,
"call_id": call_id,
"result": [
{
"type": "text",
"text": json.dumps({"url": current_url, **result})
},
{
"type": "image",
"data": base64.b64encode(screenshot_bytes).decode("utf-8"),
"mime_type": "image/png"
}
]
})
return function_responses
JavaScript
async function getFunctionResponses(page, results) {
const screenshotBuffer = await page.screenshot({ type: 'png' });
const screenshotBase64 = screenshotBuffer.toString('base64');
const currentUrl = page.url();
const functionResponses = [];
for (const [name, callId, result] of results) {
functionResponses.push({
type: "function_result",
name: name,
call_id: callId,
result: [
{
type: "text",
text: JSON.stringify({ url: currentUrl, ...result })
},
{
type: "image",
data: screenshotBase64,
mime_type: "image/png"
}
]
});
}
return functionResponses;
}
Po określeniu sposobu rejestrowania i formatowania stanu środowiska możesz połączyć wszystkie te kroki w ciągłą pętlę wykonywania.
Tworzenie pętli agenta
Aby włączyć interakcje wieloetapowe, połącz 4 kroki z sekcji Jak wdrożyć korzystanie z komputera w jedną pętlę. Pętla ta w dalszym ciągu wysyła prośby o wykonanie działań i przekazuje wyniki z powrotem do modelu, dopóki zadanie nie zostanie ukończone.
Pamiętaj, aby prawidłowo zarządzać historią rozmowy, dodając do niej na każdym etapie odpowiedzi modelu i odpowiedzi funkcji.
Python
import time
from typing import Any, List, Tuple
from playwright.sync_api import sync_playwright
from google import genai
client = genai.Client()
# Constants for screen dimensions
SCREEN_WIDTH = 1440
SCREEN_HEIGHT = 900
# Setup Playwright
print("Initializing browser...")
playwright = sync_playwright().start()
browser = playwright.chromium.launch(headless=False)
context = browser.new_context(viewport={"width": SCREEN_WIDTH, "height": SCREEN_HEIGHT})
page = context.new_page()
# Define helper functions. Copy/paste from steps 3 and 4
# def denormalize_x(...)
# def denormalize_y(...)
# def execute_function_calls(...)
# def get_function_responses(...)
try:
# Go to initial page
page.goto("https://ai.google.dev/gemini-api/docs")
# Take initial screenshot
initial_screenshot = page.screenshot(type="png")
USER_PROMPT = "Go to ai.google.dev/gemini-api/docs and search for pricing."
print(f"Goal: {USER_PROMPT}")
# First interaction
interaction = client.interactions.create(
model='gemini-3.5-flash',
input=[
{"type": "text", "text": USER_PROMPT},
{"type": "image", "data": base64.b64encode(initial_screenshot).decode("utf-8"), "mime_type": "image/png"}
],
tools=[{
"type": "computer_use",
"environment": "browser",
"enable_prompt_injection_detection": True
}]
)
# Agent Loop
turn_limit = 5
for i in range(turn_limit):
print(f"\n--- Turn {i+1} ---")
has_function_calls = any(
step.type == "function_call"
for step in interaction.steps
)
if not has_function_calls:
text_response = " ".join([
content_block.text for step in interaction.steps if step.type == "model_output"
for content_block in step.content if content_block.type == "text"
])
print("Agent finished:", text_response)
break
print("Executing actions...")
results = execute_function_calls(interaction, page, SCREEN_WIDTH, SCREEN_HEIGHT)
print("Capturing state...")
function_responses = get_function_responses(page, results)
# Continue conversation with function responses
interaction = client.interactions.create(
model='gemini-3.5-flash',
previous_interaction_id=interaction.id,
input=function_responses,
tools=[{
"type": "computer_use",
"environment": "browser",
"enable_prompt_injection_detection": True
}]
)
finally:
# Cleanup
print("\nClosing browser...")
browser.close()
playwright.stop()
JavaScript
import { chromium } from 'playwright';
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
// Constants for screen dimensions
const SCREEN_WIDTH = 1440;
const SCREEN_HEIGHT = 900;
console.log("Initializing browser...");
const browser = await chromium.launch({ headless: false });
const context = await browser.newContext({
viewport: { width: SCREEN_WIDTH, height: SCREEN_HEIGHT }
});
const page = await context.newPage();
// Define helper functions. Copy/paste from steps 3 and 4:
// function denormalizeX(...)
// function denormalizeY(...)
// async function executeFunctionCalls(...)
// async function getFunctionResponses(...)
try {
// Go to initial page
await page.goto("https://ai.google.dev/gemini-api/docs");
// Take initial screenshot
const initialScreenshotBuffer = await page.screenshot({ type: 'png' });
const initialScreenshotBase64 = initialScreenshotBuffer.toString('base64');
const USER_PROMPT = "Go to ai.google.dev/gemini-api/docs and search for pricing.";
console.log(`Goal: ${USER_PROMPT}`);
// First interaction
let interaction = await ai.interactions.create({
model: 'gemini-3.5-flash',
input: [
{ type: 'text', text: USER_PROMPT },
{ type: 'image', data: initialScreenshotBase64, mime_type: 'image/png' }
],
tools: [{
type: 'computer_use',
environment: 'browser',
enable_prompt_injection_detection: true
}]
});
// Agent Loop
const turnLimit = 5;
for (let i = 0; i < turnLimit; i++) {
console.log(`\n--- Turn ${i + 1} ---`);
const hasFunctionCalls = interaction.steps.some(step => step.type === "function_call");
if (!hasFunctionCalls) {
const textResponses = [];
for (const step of interaction.steps) {
if (step.type === "model_output") {
for (const contentBlock of step.content || []) {
if (contentBlock.type === "text") {
textResponses.push(contentBlock.text);
}
}
}
}
console.log("Agent finished:", textResponses.join(" "));
break;
}
console.log("Executing actions...");
const results = await executeFunctionCalls(interaction, page, SCREEN_WIDTH, SCREEN_HEIGHT);
console.log("Capturing state...");
const functionResponses = await getFunctionResponses(page, results);
// Continue conversation with function responses
interaction = await ai.interactions.create({
model: 'gemini-3.5-flash',
previous_interaction_id: interaction.id,
input: functionResponses,
tools: [{
type: 'computer_use',
environment: 'browser',
enable_prompt_injection_detection: true
}]
});
}
} finally {
// Cleanup
console.log("\nClosing browser...");
await browser.close();
}
Obsługiwane środowiska (Gemini 3.5 Flash)
Model Gemini 3.5 Flash obsługuje 3 środowiska określone w computer_use konfiguracjach:
Środowisko przeglądarki (ENVIRONMENT_BROWSER)
Dostępne działania w narzędziu przeglądarki:
| Nazwa polecenia | Opis | Argumenty (w wywołaniu funkcji) |
|---|---|---|
| kliknąć | Lewy przycisk myszy kliknie w danym punkcie. | y: int (0–999)x: int (0–999)intent: str |
| double_click | Dwukrotne kliknięcie współrzędnych. | y: int (0–999)x: int (0–999)intent: str |
| triple_click | Trzykrotne kliknięcie we współrzędnych. | y: int (0–999)x: int (0–999)intent: str |
| middle_click | Kliknięcie środkowym przyciskiem w danym miejscu. | y: int (0–999)x: int (0–999)intent: str |
| right_click | Kliknięcia prawym przyciskiem myszy we współrzędnych. | y: int (0–999)x: int (0–999)intent: str |
| mouse_down | Naciska i przytrzymuje przycisk myszy we współrzędnych. | y: int (0–999)x: int (0–999)intent: str |
| mouse_up | Zwalnia przycisk myszy we współrzędnych. | y: int (0–999)x: int (0–999)intent: str |
| przenieść | Przenosi kursor w określone miejsce. | y: int (0–999)x: int (0–999)intent: str |
| type | Wpisuje tekst. | text: strpress_enter: bool (opcjonalny, domyślnie false)intent: str |
| drag_and_drop | Przeciąga element od współrzędnych początkowych do końcowych. | start_y: int (0–999)start_x: int (0–999)end_y: int (0–999)end_x: int (0–999)intent: str |
| wait | Wstrzymuje wykonywanie na określony czas (w sekundach). | seconds: int (opcjonalny, domyślnie 1)intent: str |
| press_key | Naciśnięcie i puszczenie określonego klawisza. | key: strintent: str |
| key_down | Naciśnięcie i przytrzymanie określonego klawisza. | key: strintent: str |
| key_up | Zwalnia określony klawisz. | key: strintent: str |
| klawisz skrótu | Naciśnięcie określonej kombinacji klawiszy. | keys: List[str]intent: str |
| take_screenshot | Zwraca zrzut bieżącego ekranu. | intent: str |
| scroll | Przewija w górę, w dół, w lewo lub w prawo o określoną liczbę pikseli. | y: int (0–999)x: int (0–999)direction: str ("up", "down", "left", "right")magnitude_in_pixels: int (0–999, opcjonalnie, domyślnie 300)intent: str |
| go_back | Wracasz do poprzedniej strony w historii przeglądarki. | intent: str |
| navigate | Przechodzi bezpośrednio do określonego adresu URL. | url: strintent: str |
| go_forward | Przechodzi do następnej strony internetowej w historii przeglądarki. | intent: str |
Środowisko mobilne (ENVIRONMENT_MOBILE)
Działania w środowisku zoptymalizowanym pod kątem Androida:
| Nazwa polecenia | Opis | Argumenty (w wywołaniu funkcji) |
|---|---|---|
| open_app | Otwiera aplikację według nazwy. | app_name: strintent: str |
| kliknąć | Lewy przycisk myszy kliknie w danym punkcie. | y: int (0–999)x: int (0–999)intent: str |
| list_apps | Zawiera listę aplikacji dostępnych na urządzeniu, zwracając ich nazwy i nazwy pakietów. | intent: str |
| wait | Wstrzymuje wykonywanie na określony czas (w sekundach). | seconds: int (opcjonalny, domyślnie 1)intent: str |
| go_back | Cofasz się do poprzedniego ekranu lub strony internetowej. | intent: str |
| type | Wpisuje tekst. | text: strpress_enter: bool (opcjonalny, domyślnie false)intent: str |
| drag_and_drop | Przeciąga element od współrzędnych początkowych do końcowych. | start_y: int (0–999)start_x: int (0–999)end_y: int (0–999)end_x: int (0–999)intent: str |
| long_press | Wykonuje długie naciśnięcie w określonym miejscu na ekranie. | y: int (0–999)x: int (0–999)seconds: int (opcjonalnie, domyślnie 2)intent: str |
| press_key | Naciśnięcie i puszczenie określonego klawisza. | key: strintent: str |
| take_screenshot | Zwraca zrzut bieżącego ekranu. | intent: str |
Środowisko graficzne (ENVIRONMENT_DESKTOP)
Polecenia kursora na poziomie systemu operacyjnego w środowiskach desktopowych:
| Nazwa polecenia | Opis | Argumenty (w wywołaniu funkcji) |
|---|---|---|
| kliknąć | Lewy przycisk myszy kliknie w danym punkcie. | y: int (0–999)x: int (0–999)intent: str |
| double_click | Dwukrotne kliknięcie współrzędnych. | y: int (0–999)x: int (0–999)intent: str |
| triple_click | Trzykrotne kliknięcie we współrzędnych. | y: int (0–999)x: int (0–999)intent: str |
| middle_click | Kliknięcie środkowym przyciskiem w danym miejscu. | y: int (0–999)x: int (0–999)intent: str |
| right_click | Kliknięcia prawym przyciskiem myszy we współrzędnych. | y: int (0–999)x: int (0–999)intent: str |
| mouse_down | Naciska i przytrzymuje przycisk myszy we współrzędnych. | y: int (0–999)x: int (0–999)intent: str |
| mouse_up | Zwalnia przycisk myszy we współrzędnych. | y: int (0–999)x: int (0–999)intent: str |
| przenieść | Przenosi kursor w określone miejsce. | y: int (0–999)x: int (0–999)intent: str |
| type | Wpisuje tekst. | text: strpress_enter: bool (opcjonalny, domyślnie false)intent: str |
| drag_and_drop | Przeciąga element od współrzędnych początkowych do końcowych. | start_y: int (0–999)start_x: int (0–999)end_y: int (0–999)end_x: int (0–999)intent: str |
| wait | Wstrzymuje wykonywanie na określony czas (w sekundach). | seconds: int (opcjonalny, domyślnie 1)intent: str |
| press_key | Naciśnięcie i puszczenie określonego klawisza. | key: strintent: str |
| key_down | Naciśnięcie i przytrzymanie określonego klawisza. | key: strintent: str |
| key_up | Zwalnia określony klawisz. | key: strintent: str |
| klawisz skrótu | Naciśnięcie określonej kombinacji klawiszy. | keys: List[str]intent: str |
| take_screenshot | Zwraca zrzut bieżącego ekranu. | intent: str |
| scroll | Przewija w górę, w dół, w lewo lub w prawo o określoną liczbę pikseli. | y: int (0–999)x: int (0–999)direction: str ("up", "down", "left", "right")magnitude_in_pixels: int (0–999, opcjonalnie, domyślnie 300)intent: str |
Starsze obsługiwane działania w interfejsie (Gemini 2.5)
W przypadku starszych modeli (gemini-2.5-computer-use-preview-10-2025) obsługiwane są te działania:
| Nazwa polecenia | Opis | Argumenty (w wywołaniu funkcji) | Przykładowe wywołanie funkcji |
|---|---|---|---|
| open_web_browser | Otwiera przeglądarkę. | Brak | {"name": "open_web_browser", "arguments": {}} |
| wait_5_seconds | Wstrzymuje wykonywanie na 5 sekund. | Brak | {"name": "wait_5_seconds", "arguments": {}} |
| go_back | Przechodzi do poprzedniej strony w historii. | Brak | {"name": "go_back", "arguments": {}} |
| go_forward | Przechodzi do następnej strony w historii. | Brak | {"name": "go_forward", "arguments": {}} |
| search | Przechodzi do domyślnej wyszukiwarki. | Brak | {"name": "search", "arguments": {}} |
| navigate | Przekierowuje przeglądarkę bezpośrednio na podany adres URL. | url: str |
{"name": "navigate", "arguments": {"url": "https://www.wikipedia.org"}} |
| click_at | Kliknięcia w określonych współrzędnych. | y: int (0–999), x: int (0–999) |
{"name": "click_at", "arguments": {"y": 300, "x": 500}} |
| hover_at | Umieszcza wskaźnik myszy w określonym miejscu. | y: int (0–999), x: int (0–999) |
{"name": "hover_at", "arguments": {"y": 150, "x": 250}} |
| type_text_at | Wpisuje tekst we współrzędnych. | y: int (0–999), x: int (0–999), text: str, press_enter: bool (opcjonalnie, domyślnie True), clear_before_typing: bool (opcjonalnie, domyślnie True) |
{"name": "type_text_at", "arguments": {"y": 250, "x": 400, "text": "search", "press_enter": false}} |
| key_combination | Naciśnij klawisze lub kombinacje klawiszy. | keys: str |
{"name": "key_combination", "arguments": {"keys": "Control+A"}} |
| scroll_document | Przewija całą stronę internetową. | direction: str |
{"name": "scroll_document", "arguments": {"direction": "down"}} |
| scroll_at | Przewija do współrzędnych (x,y). | y: int, x: int, direction: str, magnitude: int (opcjonalny, domyślnie 800) |
{"name": "scroll_at", "arguments": {"y": 500, "x": 500, "direction": "down"}} |
| drag_and_drop | Przeciąganie między dwoma współrzędnymi. | y: int, x: int, destination_y: int, destination_x: int |
{"name": "drag_and_drop", "arguments": {"y": 100, "destination_y": 500, "destination_x": 500, "x": 100}} |
Funkcje niestandardowe zdefiniowane przez użytkownika
Możesz rozszerzyć funkcjonalność modelu, dodając niestandardowe funkcje zdefiniowane przez użytkownika. Na przykład w scenariuszach z udziałem człowieka (HITL) możesz wykluczyć domyślne, wstępnie zdefiniowane działania i zarejestrować działania niestandardowe.
Narzędzia niestandardowe Gemini 3.5 Flash
Python
Wyklucz standardowe, zdefiniowane wstępnie działania przeglądarki (np. click) i zarejestruj niestandardowe narzędzie yield_to_user:
from google import genai
client = genai.Client()
yield_to_user_tool = {
"type": "function",
"name": "yield_to_user",
"description": "Yields control back to the user for assistance or verification when an automated action is unsafe or ambiguous.",
"parameters": {
"type": "object",
"properties": {
"reason": {
"type": "string",
"description": "The reason why the agent is yielding control to the human."
}
},
"required": ["reason"]
}
}
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Click the submit button. If you need a second factor authentication code, ask me.",
tools=[
{
"type": "computer_use",
"environment": "mobile",
"excluded_predefined_functions": ["click"]
},
yield_to_user_tool
]
)
JavaScript
Wyklucz standardowe, zdefiniowane wstępnie działania przeglądarki (np. click) i zarejestruj niestandardowe narzędzie yield_to_user:
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
const yieldToUserTool = {
type: "function",
name: "yield_to_user",
description: "Yields control back to the user for assistance or verification when an automated action is unsafe or ambiguous.",
parameters: {
type: "object",
properties: {
reason: {
type: "string",
description: "The reason why the agent is yielding control to the human."
}
},
required: ["reason"]
}
};
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Click the submit button. If you need a second factor authentication code, ask me.",
tools: [
{
type: "computer_use",
environment: "mobile",
excluded_predefined_functions: ["click"]
},
yieldToUserTool
]
});
Niestandardowe narzędzia Gemini 2.5 (starsza wersja)
Python
from google import genai
client = genai.Client()
# Define custom tools here
custom_functions = [...] # Describe parameters as function declarations
excluded_functions = [
"open_web_browser",
"wait_5_seconds",
"go_back",
"go_forward",
"search",
"navigate",
"hover_at",
"scroll_document",
"key_combination",
"drag_and_drop",
]
interaction = client.interactions.create(
model='gemini-2.5-computer-use-preview-10-2025',
input="Open Chrome, then long-press at 200,400.",
tools=[
{
"type": "computer_use",
"environment": "browser",
"excluded_predefined_functions": excluded_functions
},
*custom_functions
]
)
print(interaction)
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
// Define custom tools here
const customFunctions = [...]; // Describe parameters as function declarations
const excludedFunctions = [
"open_web_browser",
"wait_5_seconds",
"go_back",
"go_forward",
"search",
"navigate",
"hover_at",
"scroll_document",
"key_combination",
"drag_and_drop",
];
const interaction = await ai.interactions.create({
model: 'gemini-2.5-computer-use-preview-10-2025',
input: "Open Chrome, then long-press at 200,400.",
tools: [
{
type: "computer_use",
environment: "browser",
excluded_predefined_functions: excludedFunctions
},
...customFunctions
]
});
console.log(interaction);
Zarządzanie poziomami myślenia (Gemini 3.5 Flash)
W przypadku agentów korzystających z komputera możesz skonfigurować różne poziomy myślenia, aby zrównoważyć jakość działania i szybkość wykonywania. Niższe poziomy myślenia zwykle zapewniają dobrą równowagę w przypadku standardowych zadań automatyzacji.
Bezpieczeństwo
Konfigurowanie zasad bezpieczeństwa (Gemini 3.5 Flash)
Model Gemini 3.5 Flash zawiera wbudowane kategorie usług związane z bezpieczeństwem, które automatycznie określają, czy wymagane jest potwierdzenie użytkownika.
| Kategoria zasad bezpieczeństwa | Opis |
|---|---|
FINANCIAL_TRANSACTIONS |
blokuje lub wywołuje potwierdzenie działań związanych z płatnościami, płatnościami w sklepie lub towarami podlegającymi regulacjom; |
SENSITIVE_DATA_MODIFICATION |
chroni dokumentację medyczną, finansową i państwową przed nieautoryzowanymi modyfikacjami; |
COMMUNICATION_TOOL |
Ogranicza możliwość samodzielnego wysyłania e-maili, wiadomości na czacie lub wersji roboczych przez agenta. |
ACCOUNT_CREATION |
Ogranicza możliwość autonomicznego rejestrowania nowych kont w witrynach przez agenta. |
DATA_MODIFICATION |
Reguluje ogólne modyfikacje systemu plików, udostępnianie danych i usuwanie pamięci. |
USER_CONSENT_MANAGEMENT |
Wymaga przejęcia kontroli nad stroną przez banery z prośbą o zgodę na stosowanie plików cookie i komunikaty dotyczące prywatności. |
LEGAL_TERMS_AND_AGREEMENTS |
Zapobiega samodzielnemu akceptowaniu przez model Warunków korzystania z usługi lub prawnie wiążących umów. |
Zastąpienia bezpieczeństwa
Możesz zastąpić wybrane zasady, przekazując zastąpienia:
Python
from google import genai
client = genai.Client()
interaction = client.interactions.create(
model="gemini-3.5-flash",
input="Clean up the local folder by archiving old logs.",
tools=[
{
"type": "computer_use",
"environment": "desktop",
"safety_policy_overrides": [
{"category": "DATA_MODIFICATION"}
]
}
]
)
JavaScript
import { GoogleGenAI } from '@google/genai';
const ai = new GoogleGenAI();
const interaction = await ai.interactions.create({
model: "gemini-3.5-flash",
input: "Clean up the local folder by archiving old logs.",
tools: [
{
type: "computer_use",
environment: "desktop",
safety_policy_overrides: [
{ category: "DATA_MODIFICATION" }
]
}
]
});
Wykrywanie wstrzykiwania promptów (Gemini 3.5 Flash)
Opcjonalny mechanizm bezpieczeństwa, który skanuje piksele zrzutu ekranu pod kątem ukrytych instrukcji dotyczących złośliwych promptów (np. „Zignoruj poprzednie polecenia”) i blokuje wykonanie, gdy je wykryje.
Potwierdzanie decyzji dotyczącej bezpieczeństwa (Gemini 2.5 Legacy)
W przypadku starszych modeli odpowiedź może zawierać parametr safety_decision:
{
"steps": [
{
"type": "function_call",
"name": "click_at",
"arguments": {
"x": 60,
"y": 100,
"safety_decision": {
"explanation": "Must check check-box",
"decision": "require_confirmation"
}
}
}
]
}
Jeśli wartość safety_decision to require_confirmation, wyświetl użytkownikowi prośbę. Jeśli użytkownik potwierdzi, ustaw wartość safety_acknowledgement w function_result.
Python
def get_safety_confirmation(safety_decision):
# Prompt user
return "CONTINUE" # Or TERMINATE
# Inside execute_function_calls:
if 'safety_decision' in function_call.arguments:
decision = get_safety_confirmation(function_call.arguments['safety_decision'])
if decision == "TERMINATE":
break
extra_fr_fields["safety_acknowledgement"] = True
Sprawdzone metody ochrony bezpieczeństwa
Korzystanie z komputera wiąże się z wyjątkowymi zagrożeniami dla bezpieczeństwa i działania, ponieważ model działający w imieniu użytkownika może napotkać na ekranach niezaufane treści lub popełniać błędy podczas wykonywania działań. Aby chronić dane i systemy użytkowników, stosuj te sprawdzone metody:
Proces z udziałem człowieka:
- Wymuszaj potwierdzenie przez użytkownika: gdy odpowiedź dotycząca bezpieczeństwa wskazuje na
require_confirmation(lub gdy wymaga tego starsza decyzja dotycząca bezpieczeństwa), wyświetl prośbę o zatwierdzenie przez użytkownika. Podaj niestandardowe instrukcje dotyczące bezpieczeństwa: wdróż niestandardową instrukcję systemową, aby zdefiniować i egzekwować własne granice bezpieczeństwa. Na przykład:
Python
from google import genai client = genai.Client() system_instruction = """ ## **RULE 1: Seek User Confirmation (USER_CONFIRMATION)** This is your first and most important check. If the next required action falls into any of the following categories, you MUST stop immediately, and seek the user's explicit permission. **Procedure for Seeking Confirmation:** * **For Consequential Actions:** Perform all preparatory steps (e.g., navigating, filling out forms, typing a message). You will ask for confirmation **AFTER** all necessary information is entered on the screen, but **BEFORE** you perform the final, irreversible action (e.g., before clicking "Send", "Submit", "Confirm Purchase", "Share"). * **For Prohibited Actions:** If the action is strictly forbidden (e.g., accepting legal terms, solving a CAPTCHA), you must first inform the user about the required action and ask for their confirmation to proceed. **USER_CONFIRMATION Categories:** * **Consent and Agreements:** You are FORBIDDEN from accepting, selecting, or agreeing to any of the following on the user's behalf. You must ask the user to confirm before performing these actions. * Terms of Service * Privacy Policies * Cookie consent banners * End User License Agreements (EULAs) * Any other legally significant contracts or agreements. * **Robot Detection:** You MUST NEVER attempt to solve or bypass the following. You must ask the user to confirm before performing these actions. * CAPTCHAs (of any kind) * Any other anti-robot or human-verification mechanisms, even if you are capable. * **Financial Transactions:** * Completing any purchase. * Managing or moving money (e.g., transfers, payments). * Purchasing regulated goods or participating in gambling. * **Sending Communications:** * Sending emails. * Sending messages on any platform (e.g., social media, chat apps). * Posting content on social media or forums. * **Accessing or Modifying Sensitive Information:** * Health, financial, or government records (e.g., medical history, tax forms, passport status). * Revealing or modifying sensitive personal identifiers (e.g., SSN, bank account number, credit card number). * **User Data Management:** * Accessing, downloading, or saving files from the web. * Sharing or sending files/data to any third party. * Transferring user data between systems. * **Browser Data Usage:** * Accessing or managing Chrome browsing history, bookmarks, autofill data, or saved passwords. * **Security and Identity:** * Logging into any user account. * Any action that involves misrepresentation or impersonation (e.g., creating a fan account, posting as someone else). * **Insurmountable Obstacles:** If you are technically unable to interact with a user interface element or are stuck in a loop you cannot resolve, ask the user to take over. --- ## **RULE 2: Default Behavior (ACTUATE)** If an action does **NOT** fall under the conditions for `USER_CONFIRMATION`, your default behavior is to **Actuate**. **Actuation Means:** You MUST proactively perform all necessary steps to move the user's request forward. Continue to actuate until you either complete the non-consequential task or encounter a condition defined in Rule 1. * **Example 1:** If asked to send money, you will navigate to the payment portal, enter the recipient's details, and enter the amount. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Send" button. * **Example 2:** If asked to post a message, you will navigate to the site, open the post composition window, and write the full message. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Post" button. After the user has confirmed, remember to get the user's latest screen before continuing to perform actions. # Final Response Guidelines: Write final response to the user in the following cases: - User confirmation - When the task is complete or you have enough information to respond to the user """ interaction = client.interactions.create( model="gemini-3.5-flash", system_instruction=system_instruction, input="Prepare a draft but do not send.", tools=[{ "type": "computer_use", "environment": "browser" }] )JavaScript
import { GoogleGenAI } from '@google/genai'; const ai = new GoogleGenAI(); const systemInstruction = ` ## **RULE 1: Seek User Confirmation (USER_CONFIRMATION)** This is your first and most important check. If the next required action falls into any of the following categories, you MUST stop immediately, and seek the user's explicit permission. **Procedure for Seeking Confirmation:** * **For Consequential Actions:** Perform all preparatory steps (e.g., navigating, filling out forms, typing a message). You will ask for confirmation **AFTER** all necessary information is entered on the screen, but **BEFORE** you perform the final, irreversible action (e.g., before clicking "Send", "Submit", "Confirm Purchase", "Share"). * **For Prohibited Actions:** If the action is strictly forbidden (e.g., accepting legal terms, solving a CAPTCHA), you must first inform the user about the required action and ask for their confirmation to proceed. **USER_CONFIRMATION Categories:** * **Consent and Agreements:** You are FORBIDDEN from accepting, selecting, or agreeing to any of the following on the user's behalf. You must ask the user to confirm before performing these actions. * Terms of Service * Privacy Policies * Cookie consent banners * End User License Agreements (EULAs) * Any other legally significant contracts or agreements. * **Robot Detection:** You MUST NEVER attempt to solve or bypass the following. You must ask the user to confirm before performing these actions. * CAPTCHAs (of any kind) * Any other anti-robot or human-verification mechanisms, even if you are capable. * **Financial Transactions:** * Completing any purchase. * Managing or moving money (e.g., transfers, payments). * Purchasing regulated goods or participating in gambling. * **Sending Communications:** * Sending emails. * Sending messages on any platform (e.g., social media, chat apps). * Posting content on social media or forums. * **Accessing or Modifying Sensitive Information:** * Health, financial, or government records (e.g., medical history, tax forms, passport status). * Revealing or modifying sensitive personal identifiers (e.g., SSN, bank account number, credit card number). * **User Data Management:** * Accessing, downloading, or saving files from the web. * Sharing or sending files/data to any third party. * Transferring user data between systems. * **Browser Data Usage:** * Accessing or managing Chrome browsing history, bookmarks, autofill data, or saved passwords. * **Security and Identity:** * Logging into any user account. * Any action that involves misrepresentation or impersonation (e.g., creating a fan account, posting as someone else). * **Insurmountable Obstacles:** If you are technically unable to interact with a user interface element or are stuck in a loop you cannot resolve, ask the user to take over. --- ## **RULE 2: Default Behavior (ACTUATE)** If an action does **NOT** fall under the conditions for `USER_CONFIRMATION`, your default behavior is to **Actuate**. **Actuation Means:** You MUST proactively perform all necessary steps to move the user's request forward. Continue to actuate until you either complete the non-consequential task or encounter a condition defined in Rule 1. * **Example 1:** If asked to send money, you will navigate to the payment portal, enter the recipient's details, and enter the amount. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Send" button. * **Example 2:** If asked to post a message, you will navigate to the site, open the post composition window, and write the full message. You will then **STOP** as per Rule 1 and ask for confirmation before clicking the final "Post" button. After the user has confirmed, remember to get the user's latest screen before continuing to perform actions. # Final Response Guidelines: Write final response to the user in the following cases: - User confirmation - When the task is complete or you have enough information to respond to the user `; const interaction = await ai.interactions.create({ model: "gemini-3.5-flash", system_instruction: systemInstruction, input: "Prepare a draft but do not send.", tools: [{ type: "computer_use", environment: "browser" }] });
- Wymuszaj potwierdzenie przez użytkownika: gdy odpowiedź dotycząca bezpieczeństwa wskazuje na
Bezpieczne środowisko wykonawcze: uruchamiaj agenta w bezpiecznym środowisku piaskownicy, aby ograniczyć jego potencjalny wpływ. Może to być maszyna wirtualna w piaskownicy, kontener (np. Docker) lub dedykowany profil przeglądarki z ograniczonymi uprawnieniami. Wskazówki dotyczące konfigurowania piaskownicy za pomocą Dockera znajdziesz w implementacji referencyjnej na GitHubie.
Czyszczenie danych wejściowych: czyszczenie całego tekstu wygenerowanego przez użytkownika w promptach w celu zmniejszenia ryzyka niezamierzonych instrukcji lub wstrzykiwania promptów. Jest to przydatna warstwa zabezpieczeń, ale nie zastępuje bezpiecznego środowiska wykonawczego.
Zabezpieczenia treści: używaj zabezpieczeń i interfejsów Content Safety API, aby oceniać dane wejściowe użytkownika, dane wejściowe i wyjściowe narzędzia oraz odpowiedzi agenta pod kątem odpowiedniości, wstrzykiwania promptów i wykrywania jailbreaku.
Listy dozwolonych i zablokowanych: wdróż mechanizmy filtrowania, aby kontrolować, gdzie model może się poruszać i co może robić. Dobrym punktem początkowym jest lista zablokowanych zakazanych witryn, a jeszcze bezpieczniejsza jest bardziej restrykcyjna lista dozwolonych.
Dostrzegalność i rejestrowanie: prowadź szczegółowe dzienniki na potrzeby debugowania, kontroli i reagowania na incydenty. Klient powinien rejestrować prompty, zrzuty ekranu, sugerowane przez model działania (
function_call), odpowiedzi związane z bezpieczeństwem i wszystkie działania ostatecznie wykonywane przez klienta.Zarządzanie środowiskiem: zadbaj o spójność środowiska GUI. Nieoczekiwane wyskakujące okienka, powiadomienia lub zmiany układu mogą wprowadzić model w błąd. W miarę możliwości zaczynaj każde nowe zadanie od znanego, czystego stanu.
Wersje modelu
Z funkcji korzystania z komputera możesz korzystać w przypadku tych modeli:
- Gemini 3.5 Flash (
gemini-3.5-flash): zalecany model do użytku na komputerze, który oferuje uproszczone działania z intencjami, obsługę środowisk przeglądarki, urządzeń mobilnych i komputerów, konfigurowalne zasady bezpieczeństwa oraz wykrywanie wstrzykiwania promptów. - Gemini 3 Flash (wersja testowa) (
gemini-3-flash-preview): model w wersji testowej obsługujący korzystanie z komputera. - Gemini 2.5 (starsza wersja testowa) (
gemini-2.5-computer-use-preview-10-2025): starsza wersja testowa modelu zoptymalizowana pod kątem korzystania z komputera w przeglądarce.
Co dalej?
- Wypróbuj korzystanie z komputera w środowisku demonstracyjnym Browserbase.
- Przykładowy kod znajdziesz w implementacji referencyjnej.
- Dowiedz się więcej o innych narzędziach Gemini API: