
رسیدگی به سوالات مشتریان، از جمله ایمیلها، بخش ضروری اداره بسیاری از کسبوکارها است، اما میتواند به سرعت طاقتفرسا شود. با کمی تلاش، مدلهای هوش مصنوعی (AI) مانند Gemma میتوانند به آسانتر شدن این کار کمک کنند.
هر کسبوکاری به سوالاتی مانند ایمیلها به شیوهای متفاوت پاسخ میدهد، بنابراین مهم است که بتوانید فناوریهایی مانند هوش مصنوعی مولد را با نیازهای کسبوکار خود تطبیق دهید. این پروژه به مشکل خاص استخراج اطلاعات سفارش از ایمیلهای ارسالی به یک نانوایی به دادههای ساختاریافته میپردازد، به طوری که بتوان آن را به سرعت به سیستم مدیریت سفارش اضافه کرد. با استفاده از 10 تا 20 نمونه از سوالات و خروجی مورد نظر خود، میتوانید یک مدل Gemma را برای پردازش ایمیلهای مشتریان خود تنظیم کنید، به شما در پاسخگویی سریع کمک کند و با سیستمهای تجاری موجود خود ادغام شود. این پروژه به عنوان یک الگوی کاربردی هوش مصنوعی ساخته شده است که میتوانید آن را گسترش داده و تطبیق دهید تا از مدلهای Gemma برای کسبوکار خود ارزش کسب کنید.
برای مشاهدهی ویدیویی از پروژه و نحوهی گسترش آن، شامل بینشهایی از افرادی که آن را ساختهاند، ویدیوی «ساخت دستیار هوش مصنوعی ایمیل تجاری با هوش مصنوعی گوگل» را ببینید. همچنین میتوانید کد این پروژه را در مخزن کد کتاب آشپزی Gemma بررسی کنید. در غیر این صورت، میتوانید با استفاده از دستورالعملهای زیر، گسترش پروژه را شروع کنید.
نمای کلی
این آموزش شما را در راهاندازی، اجرا و گسترش یک برنامه دستیار ایمیل تجاری که با Gemma، پایتون و Flask ساخته شده است، راهنمایی میکند. این پروژه یک رابط کاربری وب پایه ارائه میدهد که میتوانید آن را متناسب با نیازهای خود تغییر دهید. این برنامه برای استخراج دادهها از ایمیلهای مشتریان در ساختاری برای یک نانوایی فرضی ساخته شده است. میتوانید از این الگوی برنامه برای هر کار تجاری که از ورودی و خروجی متن استفاده میکند، استفاده کنید.
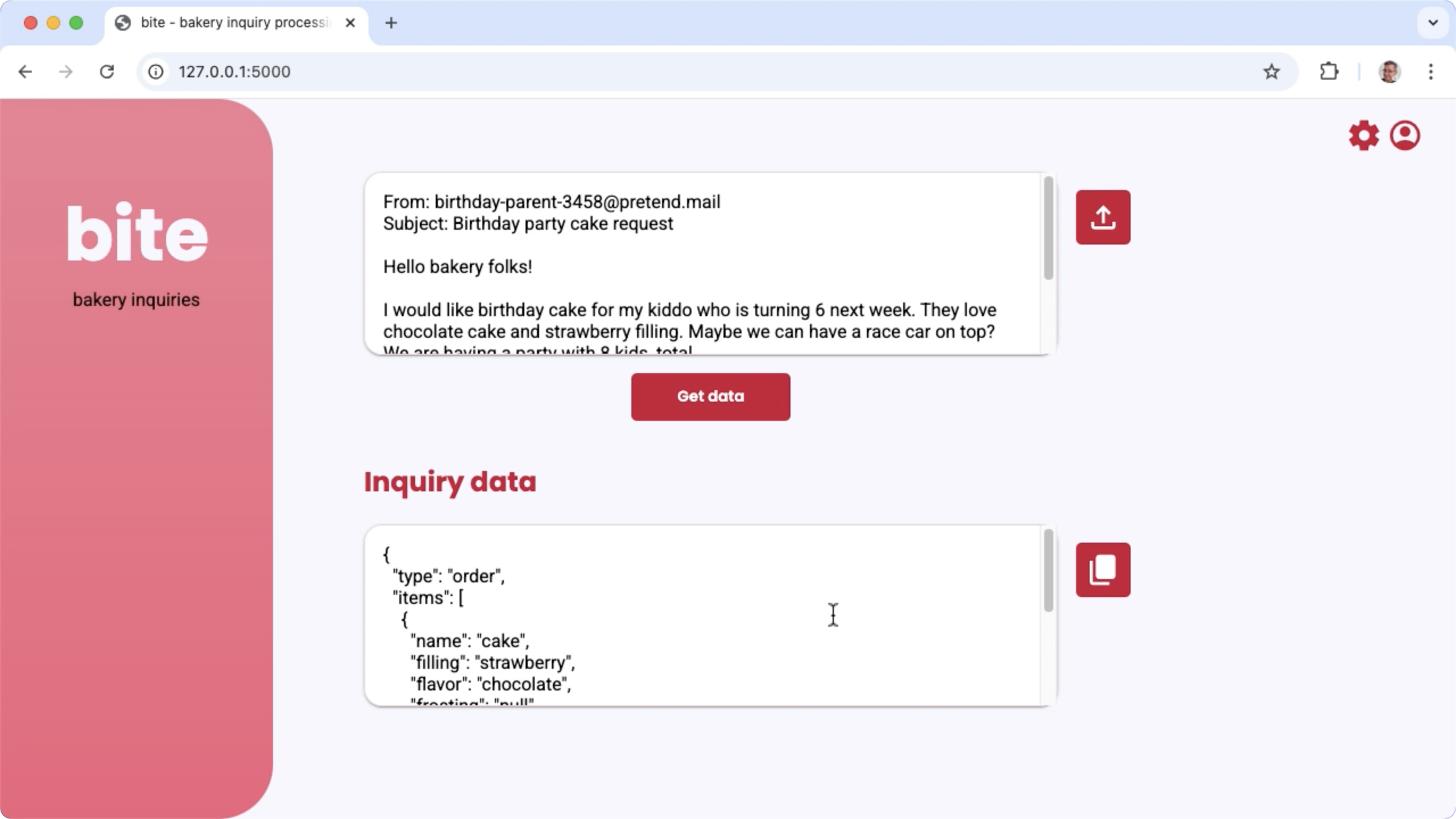
شکل ۱. رابط کاربری پروژه برای پردازش درخواستهای ایمیل نانوایی
الزامات سختافزاری
این فرآیند تنظیم را روی کامپیوتری با واحد پردازش گرافیکی (GPU) یا واحد پردازش تنسور (TPU) و حافظه کافی GPU یا TPU برای نگهداری مدل موجود، به علاوه دادههای تنظیم، اجرا کنید. برای اجرای پیکربندی تنظیم در این پروژه، به حدود ۱۶ گیگابایت حافظه GPU، تقریباً به همان مقدار رم معمولی و حداقل ۵۰ گیگابایت فضای دیسک نیاز دارید.
شما میتوانید بخش تنظیم مدل Gemma از این آموزش را با استفاده از یک محیط Colab با زمان اجرای T4 GPU اجرا کنید. اگر این پروژه را روی یک نمونه Google Cloud VM میسازید، نمونه را با توجه به این الزامات پیکربندی کنید:
- سختافزار پردازنده گرافیکی : برای اجرای این پروژه به یک کارت گرافیک NVIDIA T4 نیاز است (NVIDIA L4 یا بالاتر توصیه میشود)
- سیستم عامل : گزینه Deep Learning on Linux ، به ویژه Deep Learning VM با CUDA 12.3 M124 به همراه درایورهای نرمافزار GPU از پیش نصب شده را انتخاب کنید.
- اندازه دیسک بوت : حداقل ۵۰ گیگابایت فضای دیسک برای دادهها، مدلها و نرمافزارهای پشتیبانی خود در نظر بگیرید.
راهاندازی پروژه
این دستورالعملها شما را در آمادهسازی این پروژه برای توسعه و آزمایش راهنمایی میکنند. مراحل کلی راهاندازی شامل نصب نرمافزارهای پیشنیاز، کپی کردن پروژه از مخزن کد، تنظیم چند متغیر محیطی، نصب کتابخانههای پایتون و آزمایش برنامه وب است.
نصب و پیکربندی
این پروژه از پایتون ۳ و محیطهای مجازی ( venv ) برای مدیریت بستهها و اجرای برنامه استفاده میکند. دستورالعملهای نصب زیر برای یک دستگاه میزبان لینوکس است.
برای نصب نرمافزارهای مورد نیاز:
پایتون ۳ و بسته محیط مجازی
venvبرای پایتون را نصب کنید:sudo apt update sudo apt install git pip python3-venv
پروژه را کلون کنید
کد پروژه را روی کامپیوتر توسعهدهنده خود دانلود کنید. برای بازیابی کد منبع پروژه به نرمافزار کنترل منبع گیت نیاز دارید.
برای دانلود کد پروژه:
مخزن git را با استفاده از دستور زیر کلون کنید:
git clone https://github.com/google-gemini/gemma-cookbook.gitبه صورت اختیاری، مخزن گیت محلی خود را طوری پیکربندی کنید که از پرداخت پراکنده استفاده کند، تا فقط فایلهای پروژه را داشته باشید:
cd gemma-cookbook/ git sparse-checkout set Demos/business-email-assistant/ git sparse-checkout init --cone
نصب کتابخانههای پایتون
کتابخانههای پایتون را با فعال کردن محیط مجازی پایتون venv برای مدیریت بستهها و وابستگیهای پایتون نصب کنید. قبل از نصب کتابخانههای پایتون با نصبکننده pip ، مطمئن شوید که محیط مجازی پایتون را فعال کردهاید. برای اطلاعات بیشتر در مورد استفاده از محیطهای مجازی پایتون، به مستندات پایتون venv مراجعه کنید.
برای نصب کتابخانههای پایتون:
در یک پنجره ترمینال، به دایرکتوری
business-email-assistantبروید:cd Demos/business-email-assistant/محیط مجازی پایتون (venv) را برای این پروژه پیکربندی و فعال کنید:
python3 -m venv venv source venv/bin/activateکتابخانههای پایتون مورد نیاز برای این پروژه را با استفاده از اسکریپت
setup_pythonنصب کنید:./setup_python.sh
تنظیم متغیرهای محیطی
این پروژه برای اجرا به چند متغیر محیطی، از جمله نام کاربری Kaggle و توکن API Kaggle، نیاز دارد. برای دانلود مدلهای Gemma، باید یک حساب Kaggle داشته باشید و درخواست دسترسی به آنها را بدهید. برای این پروژه، نام کاربری Kaggle و توکن API Kaggle خود را به دو فایل .env اضافه میکنید که به ترتیب توسط برنامه وب و برنامه تنظیم خوانده میشوند.
برای تنظیم متغیرهای محیطی:
- با دنبال کردن دستورالعملهای موجود در مستندات Kaggle ، نام کاربری و کلید توکن Kaggle خود را دریافت کنید.
- با دنبال کردن دستورالعملهای «دسترسی به Gemma» در صفحه تنظیمات Gemma ، به مدل Gemma دسترسی پیدا کنید.
- با ایجاد یک فایل متنی
.envدر هر یک از این مکانها در کلون پروژه خود، فایلهای متغیر محیطی را برای پروژه ایجاد کنید:email-processing-webapp/.env model-tuning/.env
پس از ایجاد فایلهای متنی
.env، تنظیمات زیر را به هر دو فایل اضافه کنید:KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME_HERE> KAGGLE_KEY=<YOUR_KAGGLE_KEY_HERE>
اجرا و تست اپلیکیشن
پس از اتمام نصب و پیکربندی پروژه، برنامه وب را اجرا کنید تا تأیید شود که آن را به درستی پیکربندی کردهاید. شما باید این کار را به عنوان یک بررسی اولیه قبل از ویرایش پروژه برای استفاده شخصی خود انجام دهید.
برای اجرا و آزمایش پروژه:
در یک پنجره ترمینال، به دایرکتوری
email-processing-webappبروید:cd business-email-assistant/email-processing-webapp/برنامه را با استفاده از اسکریپت
run_appاجرا کنید:./run_app.shپس از شروع برنامه وب، کد برنامه یک URL را فهرست میکند که میتوانید در آن مرور و آزمایش کنید. معمولاً این آدرس به صورت زیر است:
http://127.0.0.1:5000/در رابط وب، دکمه Get data را در زیر اولین فیلد ورودی فشار دهید تا پاسخی از مدل ایجاد شود.
اولین پاسخ از مدل پس از اجرای برنامه، زمان بیشتری طول میکشد، زیرا باید مراحل مقداردهی اولیه را در اولین اجرای نسل کامل کند. درخواستهای بعدی و تولید در یک برنامه وب از قبل در حال اجرا، در زمان کمتری انجام میشوند.
برنامه را تمدید کنید
پس از اجرای برنامه، میتوانید با تغییر رابط کاربری و منطق کسبوکار، آن را گسترش دهید تا برای وظایفی که مربوط به شما یا کسبوکارتان است، کار کند. همچنین میتوانید با تغییر اجزای اعلانی که برنامه به مدل هوش مصنوعی مولد ارسال میکند، رفتار مدل Gemma را با استفاده از کد برنامه تغییر دهید.
این برنامه به همراه دادههای ورودی از کاربر، دستورالعملهایی را برای مدل ارائه میدهد که شامل یک اعلان کامل از مدل است. شما میتوانید این دستورالعملها را برای تغییر رفتار مدل تغییر دهید، مانند تعیین نام پارامترها و ساختار JSON برای تولید. یک راه سادهتر برای تغییر رفتار مدل، ارائه دستورالعملها یا راهنماییهای اضافی برای پاسخ مدل است، مانند تعیین اینکه پاسخهای تولید شده نباید شامل هیچ قالببندی Markdown باشند.
برای تغییر دستورالعملهای سریع:
- در پروژه توسعه، فایل کد
business-email-assistant/email-processing-webapp/app.pyرا باز کنید. در کد
app.py، دستورالعملهای اضافات را به تابعget_prompt():اضافه کنید:def get_prompt(): return """ Extract the relevant details of this request and return them in JSON code, with no additional markdown formatting:\n"""
این مثال عبارت «بدون قالببندی اضافی نشانهگذاری» را به دستورالعملها اضافه میکند.
ارائه دستورالعملهای سریع اضافی میتواند به شدت بر خروجی تولید شده تأثیر بگذارد و پیادهسازی آن به طور قابل توجهی تلاش کمتری میطلبد. ابتدا باید این روش را امتحان کنید تا ببینید آیا میتوانید رفتار مورد نظر خود را از مدل دریافت کنید یا خیر. با این حال، استفاده از دستورالعملهای سریع برای تغییر رفتار مدل Gemma محدودیتهای خود را دارد. به طور خاص، محدودیت کلی توکن ورودی مدل، که برای Gemma 2، ۸۱۹۲ توکن است، شما را ملزم میکند که دستورالعملهای سریع دقیق را با اندازه دادههای جدیدی که ارائه میدهید متعادل کنید تا زیر آن محدودیت باقی بمانید.
مدل را تنظیم کنید
انجام تنظیم دقیق یک مدل Gemma روش پیشنهادی برای پاسخگویی مطمئنتر آن به وظایف خاص است. به طور خاص، اگر میخواهید مدل JSON را با ساختار خاصی، شامل پارامترهای با نام مشخص، تولید کند، باید تنظیم مدل را برای آن رفتار در نظر بگیرید. بسته به وظیفهای که میخواهید مدل انجام دهد، میتوانید با 10 تا 20 مثال به قابلیتهای اولیه دست یابید. این بخش از آموزش نحوه تنظیم و اجرای تنظیم دقیق روی یک مدل Gemma را برای یک وظیفه خاص توضیح میدهد.
دستورالعملهای زیر نحوه انجام عملیات تنظیم دقیق در محیط ماشین مجازی را توضیح میدهند، با این حال، میتوانید این عملیات تنظیم را با استفاده از دفترچه یادداشت Colab مرتبط با این پروژه نیز انجام دهید.
الزامات سختافزاری
الزامات محاسباتی برای تنظیم دقیق، مشابه الزامات سختافزاری برای بقیه پروژه است. اگر تعداد توکنهای ورودی را به ۲۵۶ و اندازه دسته را به ۱ محدود کنید، میتوانید عملیات تنظیم را در یک محیط Colab با زمان اجرای T4 GPU اجرا کنید.
آمادهسازی دادهها
قبل از شروع تنظیم مدل Gemma، باید دادهها را برای تنظیم آماده کنید. وقتی مدلی را برای یک کار خاص تنظیم میکنید، به مجموعهای از نمونههای درخواست و پاسخ نیاز دارید. این نمونهها باید متن درخواست ( بدون هیچ دستورالعملی) و متن پاسخ مورد انتظار را نشان دهند. برای شروع، باید یک مجموعه داده با حدود 10 نمونه آماده کنید. این نمونهها باید نشاندهنده طیف کاملی از درخواستها و پاسخهای ایدهآل باشند. مطمئن شوید که درخواستها و پاسخها تکراری نیستند، زیرا این امر میتواند باعث شود پاسخهای مدل تکراری باشند و به طور مناسب با تغییرات در درخواستها تنظیم نشوند. اگر مدل را برای تولید یک قالب داده ساختاریافته تنظیم میکنید، مطمئن شوید که تمام پاسخهای ارائه شده کاملاً با قالب خروجی داده مورد نظر شما مطابقت دارند. جدول زیر چند نمونه رکورد از مجموعه داده این نمونه کد را نشان میدهد:
| درخواست | پاسخ |
|---|---|
| سلام نانوایی مرکزی هند، آیا شما 10 پندا و سی لادو باندی دارید؟ آیا کیکهای وانیلی و شکلاتی هم میفروشید؟ من دنبال یک سایز 15 سانتیمتری هستم. | { "نوع": "درخواست", "اقلام": [ { "نام": "پندا", "مقدار": 10 }, { "نام": "باندی لادو", "مقدار": 30 }, { "نام": "کیک", "مواد داخل کیک": null, "فراستینگ": "وانیلی", "طعم": "شکلاتی", "اندازه": "6 اینچ" } ] } |
| من کسب و کار شما را در نقشه گوگل دیدم. آیا شما ژله و گلاب جامون میفروشید؟ | { "نوع": "درخواست", "اقلام": [ { "نام": "جلابی", "مقدار": null }, { "نام": "گلاب جامون", "مقدار": null } ] } |
جدول 1. فهرست بخشی از مجموعه دادههای تنظیم برای استخراجکننده دادههای ایمیل نانوایی.
قالب داده و بارگذاری
شما میتوانید دادههای تنظیم خود را در هر قالبی که مناسب باشد، از جمله رکوردهای پایگاه داده، فایلهای JSON، CSV یا فایلهای متنی ساده، ذخیره کنید، البته تا زمانی که ابزار بازیابی رکوردها را با کد پایتون داشته باشید. این پروژه فایلهای JSON را از یک دایرکتوری data در آرایهای از اشیاء دیکشنری میخواند. در این برنامه تنظیم نمونه، مجموعه دادههای تنظیم با استفاده از تابع prepare_tuning_dataset() در ماژول model-tuning/main.py بارگذاری میشود:
def prepare_tuning_dataset():
# collect data from JSON files
prompt_data = read_json_files_to_dicts("./data")
...
همانطور که قبلاً ذکر شد، میتوانید مجموعه دادهها را در قالبی مناسب ذخیره کنید، به شرطی که بتوانید درخواستها را با پاسخهای مرتبط بازیابی کرده و آنها را در یک رشته متنی که به عنوان رکورد تنظیم استفاده میشود، جمعآوری کنید.
سوابق تنظیم را جمع کنید
برای فرآیند تنظیم واقعی، برنامه هر درخواست و پاسخ را در یک رشته واحد به همراه دستورالعملهای اعلان و محتوای پاسخ، جمعآوری میکند. سپس برنامه تنظیم، رشته را برای مصرف توسط مدل، توکنسازی میکند. میتوانید کد مربوط به جمعآوری یک رکورد تنظیم را در تابع prepare_tuning_dataset() ماژول model-tuning/main.py به شرح زیر مشاهده کنید:
def prepare_tuning_dataset():
...
# prepare data for tuning
tuning_dataset = []
template = "{instruction}\n{response}"
for prompt in prompt_data:
tuning_dataset.append(template.format(instruction=prompt["prompt"],
response=prompt["response"]))
return tuning_dataset
این تابع دادهها را به عنوان ورودی خود میگیرد و با اضافه کردن یک خط فاصله بین دستورالعمل و پاسخ، آنها را قالببندی میکند.
وزنهای مدل را تولید کنید
پس از اینکه دادههای تنظیم را در محل خود قرار دادید و بارگذاری کردید، میتوانید برنامه تنظیم را اجرا کنید. فرآیند تنظیم برای این برنامه نمونه از کتابخانه Keras NLP برای تنظیم مدل با تکنیک Low Rank Adaptation یا LoRA استفاده میکند تا وزنهای مدل جدید تولید شود. در مقایسه با تنظیم دقیق کامل، استفاده از LoRA به طور قابل توجهی از نظر حافظه کارآمدتر است زیرا تغییرات وزنهای مدل را تقریبی میکند. سپس میتوانید این وزنهای تقریبی را روی وزنهای مدل موجود قرار دهید تا رفتار مدل را تغییر دهید.
برای انجام تنظیم و محاسبه وزنهای جدید:
در یک پنجره ترمینال، به دایرکتوری
model-tuning/بروید.cd business-email-assistant/model-tuning/فرآیند تنظیم را با استفاده از اسکریپت
tune_modelاجرا کنید:./tune_model.sh
فرآیند تنظیم، بسته به منابع محاسباتی موجود شما، چندین دقیقه طول میکشد. پس از اتمام موفقیتآمیز، برنامه تنظیم، فایلهای وزنی جدید *.h5 را در دایرکتوری model-tuning/weights با فرمت زیر مینویسد:
gemma2-2b_inquiry_tuned_4_epoch##.lora.h5
عیبیابی
اگر تنظیم با موفقیت انجام نشود، دو دلیل احتمالی وجود دارد:
- کمبود حافظه یا منابع مصرفی : این خطاها زمانی رخ میدهند که فرآیند تنظیم، حافظهای را درخواست میکند که از حافظه GPU یا حافظه CPU موجود بیشتر است. مطمئن شوید که در حین اجرای فرآیند تنظیم، برنامه وب را اجرا نمیکنید. اگر در حال تنظیم روی دستگاهی با ۱۶ گیگابایت حافظه GPU هستید، مطمئن شوید که مقدار
token_limitروی ۲۵۶ وbatch_sizeروی ۱ تنظیم شده باشد. - درایورهای GPU نصب نشدهاند یا با JAX سازگار نیستند : فرآیند تنظیم مستلزم آن است که دستگاه محاسباتی درایورهای سختافزاری سازگار با نسخه کتابخانههای JAX را نصب کرده باشد. برای جزئیات بیشتر، به مستندات نصب JAX مراجعه کنید.
استقرار مدل تنظیمشده
فرآیند تنظیم، وزنهای متعددی را بر اساس دادههای تنظیم و تعداد کل دورههای تنظیم در برنامه تنظیم تولید میکند. به طور پیشفرض، برنامه تنظیم، ۳ فایل وزن مدل تولید میکند، یکی برای هر دوره تنظیم. هر دوره تنظیم متوالی، وزنهایی تولید میکند که نتایج دادههای تنظیم را با دقت بیشتری بازتولید میکنند. میتوانید نرخ دقت هر دوره را در خروجی نهایی فرآیند تنظیم، به شرح زیر مشاهده کنید:
...
8/8 ━━━━━━━━━━━━━━━━━━━━ 121s 195ms/step - loss: 0.5432 - sparse_categorical_accuracy: 0.5982
Epoch 2/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 194ms/step - loss: 0.3320 - sparse_categorical_accuracy: 0.6966
Epoch 3/3
8/8 ━━━━━━━━━━━━━━━━━━━━ 2s 192ms/step - loss: 0.2135 - sparse_categorical_accuracy: 0.7848
در حالی که میخواهید نرخ دقت نسبتاً بالا، حدود ۰.۸۰ باشد، نمیخواهید این نرخ خیلی بالا یا خیلی نزدیک به ۱.۰۰ باشد، زیرا این بدان معناست که وزنها به بیشبرازش دادههای تنظیم نزدیک شدهاند. وقتی این اتفاق میافتد، مدل در درخواستهایی که تفاوت قابل توجهی با نمونههای تنظیم دارند، عملکرد خوبی ندارد. به طور پیشفرض، اسکریپت استقرار، وزنهای دوره ۳ را انتخاب میکند که معمولاً نرخ دقتی حدود ۰.۸۰ دارند.
برای اعمال وزنهای تولید شده به برنامه وب:
در یک پنجره ترمینال، به دایرکتوری
model-tuningبروید:cd business-email-assistant/model-tuning/فرآیند تنظیم را با استفاده از اسکریپت
deploy_weightsاجرا کنید:./deploy_weights.sh
پس از اجرای این اسکریپت، باید یک فایل *.h5 جدید در دایرکتوری email-processing-webapp/weights/ مشاهده کنید.
مدل جدید را آزمایش کنید
پس از اینکه وزنهای جدید را در برنامه مستقر کردید، وقت آن است که مدل تازه تنظیمشده را امتحان کنید. میتوانید این کار را با اجرای مجدد برنامه وب و تولید یک پاسخ انجام دهید.
برای اجرا و آزمایش پروژه:
در یک پنجره ترمینال، به دایرکتوری
email-processing-webappبروید:cd business-email-assistant/email-processing-webapp/برنامه را با استفاده از اسکریپت
run_appاجرا کنید:./run_app.shپس از شروع برنامه وب، کد برنامه یک URL را فهرست میکند که میتوانید در آن مرور و آزمایش کنید، معمولاً این آدرس است:
http://127.0.0.1:5000/در رابط وب، دکمه Get data را در زیر اولین فیلد ورودی فشار دهید تا پاسخی از مدل ایجاد شود.
اکنون شما یک مدل Gemma را در یک برنامه تنظیم و مستقر کردهاید! با برنامه آزمایش کنید و سعی کنید محدودیتهای قابلیت تولید مدل تنظیمشده را برای وظیفه خود تعیین کنید. اگر سناریوهایی را پیدا کردید که در آنها مدل عملکرد خوبی ندارد، با اضافه کردن درخواست و ارائه یک پاسخ ایدهآل، اضافه کردن برخی از آن درخواستها به لیست دادههای نمونه تنظیم خود را در نظر بگیرید. سپس فرآیند تنظیم را دوباره اجرا کنید، وزنهای جدید را دوباره مستقر کنید و خروجی را آزمایش کنید.
منابع اضافی
برای اطلاعات بیشتر در مورد این پروژه، به مخزن کد Gemma Cookbook مراجعه کنید. اگر برای ساخت برنامه به کمک نیاز دارید یا به دنبال همکاری با سایر توسعهدهندگان هستید، به سرور Discord انجمن توسعهدهندگان گوگل مراجعه کنید. برای پروژههای بیشتر Build with Google AI، به لیست پخش ویدیو مراجعه کنید.